
什么?单块GPU也能训练大模型了?
还是20系就能拿下的那种???
没开玩笑,事实已经摆在眼前:
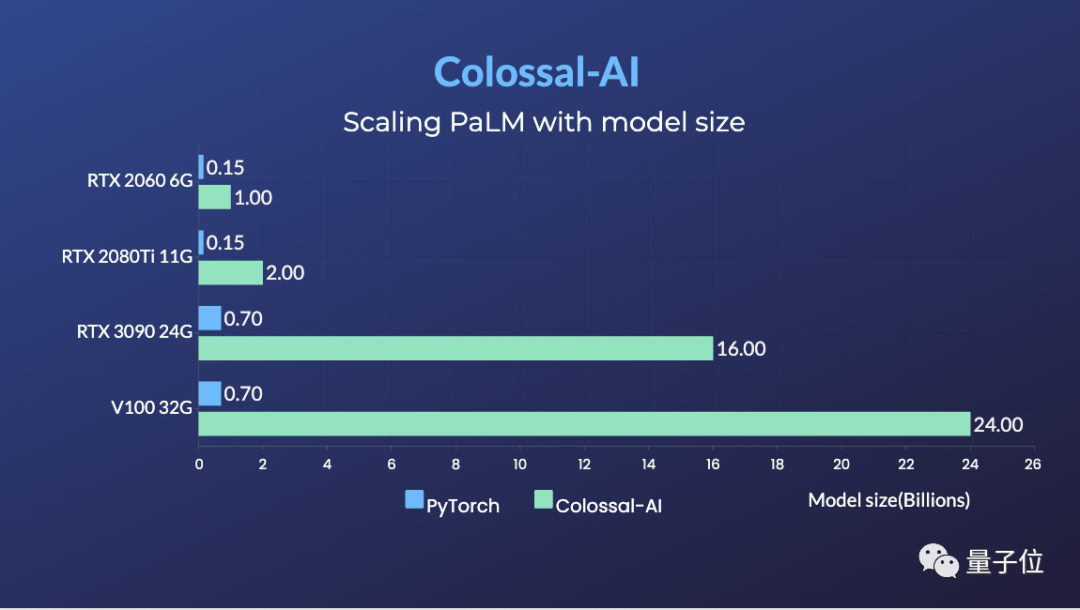
RTX 2060 6GB普通游戏本能训练15亿参数模型;
RTX 3090 24GB主机直接单挑180亿参数大模型;
Tesla V100 32GB连240亿参数都能拿下。
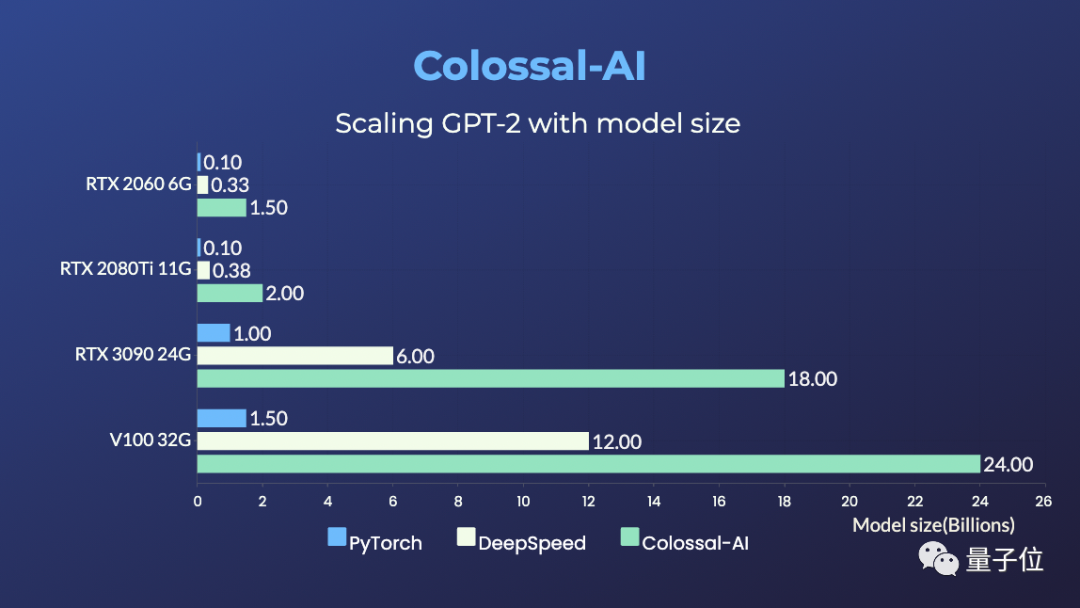
相比于PyTorch和业界主流的DeepSpeed方法,提升参数容量能达到10多倍。
而且这种方法完全开源,只需要几行代码就能搞定,修改量也非常少。

这波操作真是直接腰斩大模型训练门槛啊,老黄岂不是要血亏。
那么,搞出如此大名堂的是何方大佬呢?
它就是国产开源项目Colossal-AI。
自开源以来,曾多次霸榜GitHub热门*。
△开源地址:https://github.com/hpcaitech/ColossalAI
主要做的事情就是加速各种大模型训练,GPT-2、GPT-3、ViT、BERT等模型都能搞定。
比如能半小时左右预训练一遍ViT-Base/32,2天训完15亿参数GPT模型、5天训完83亿参数GPT模型。
同时还能省GPU。
比如训练GPT-3时使用的GPU资源,可以只是英伟达Megatron-LM的一半。
那么这一回,它又是如何让单块GPU训练百亿参数大模型的呢?
我们深扒了一下原理~
高效利用GPU+CPU异构内存
为什么单张消费级显卡很难训练AI大模型?
显存有限,是*的困难。
当今大模型风头正盛、效果又好,谁不想上手感受一把?
但动不动就“CUDA out of memory”,着实让人遭不住。
目前,业界主流方法是微软DeepSpeed提出的ZeRO(Zero Reduency Optimizer)。
它的主要原理是将模型切分,把模型内存平均分配到单个GPU上。
数据并行度越高,GPU上的内存消耗越低。
这种方法在CPU和GPU内存之间仅使用静态划分模型数据,而且内存布局针对不同的训练配置也是恒定的。
由此会导致两方面问题。
*,当GPU或CPU内存不足以满足相应模型数据要求时,即使还有其他设备上有内存可用,系统还是会崩溃。
第二,细粒度的张量在不同内存空间传输时,通信效率会很低;当可以将模型数据提前放置到目标计算设备上时,CPU-GPU的通信量又是不必要的。
目前已经出现了不少DeepSpeed的魔改版本,提出使用电脑硬盘来动态存储模型,但是硬盘的读写速度明显低于内存和显存,训练速度依旧会被拖慢。
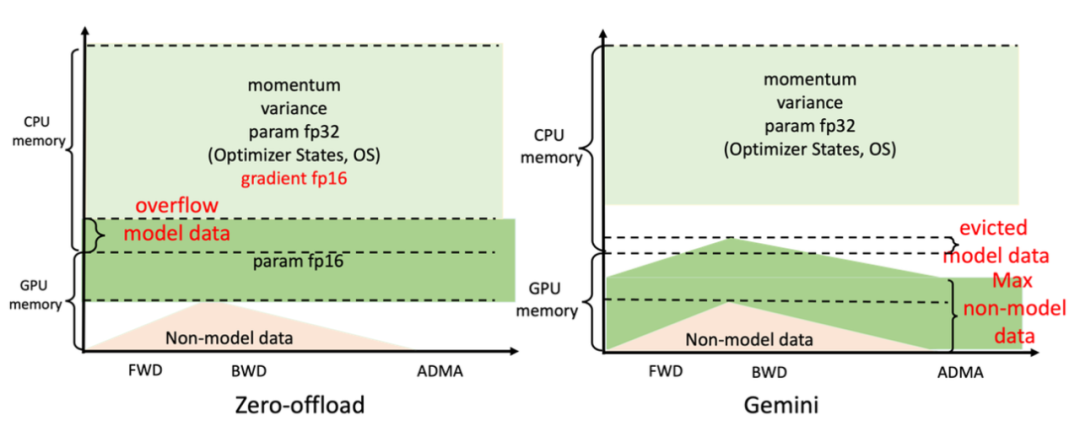
针对这些问题,Colossal-AI采用的解决思路是高效利用GPU+CPU的异构内存。
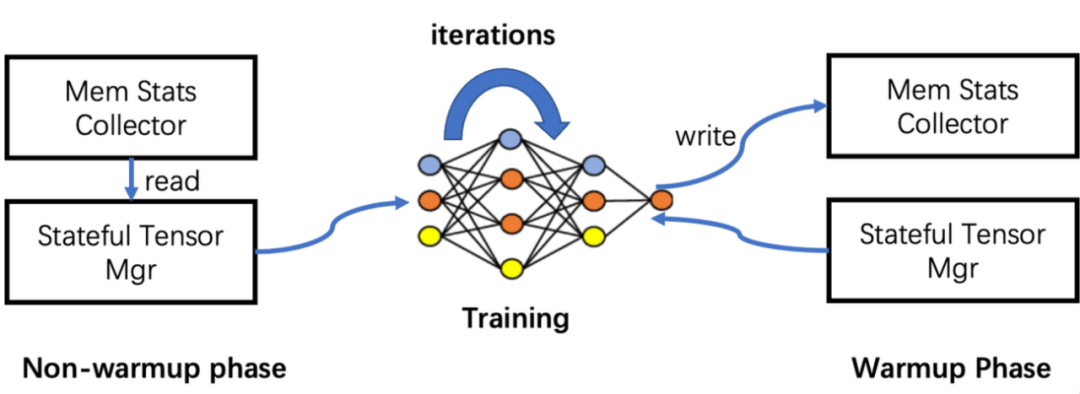
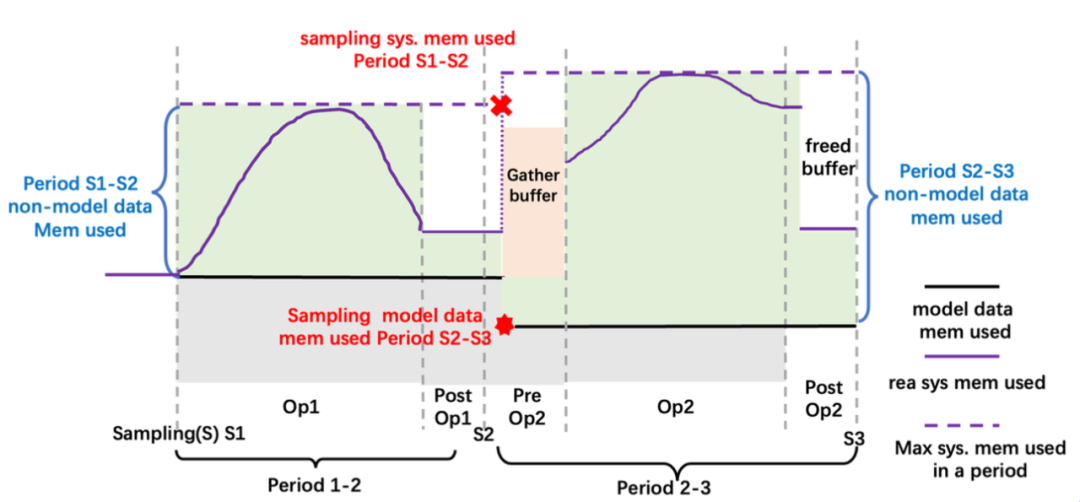
具体来看,是利用深度学习网络训练过程中不断迭代的特性,按照迭代次数将整个训练过程分为预热和正式两个阶段。
预热阶段,监测采集到非模型数据内存信息;
正式阶段,根据采集到的信息,预留出下一个算子在计算设备上所需的峰值内存,移动出一些GPU模型张量到CPU内存。
大概逻辑如下所示:
这里稍微展开说明下,模型数据由参数、梯度和优化器状态组成,它们的足迹和模型结构定义有关。
非模型数据由operator生成的中间张量组成,会根据训练任务的配置(如批次大小)动态变化。
它俩常干的事呢,就是抢GPU显存。
所以,就需要在GPU显存不够时CPU能来帮忙,与此同时还要避免其他情况下内存浪费。
Colossal-AI高效利用GPU+CPU的异构内存,就是这样的逻辑。
而以上过程中,获取非模型数据的内存使用量其实非常难。
因为非模型数据的生存周期并不归用户管理,现有的深度学习框架没有暴露非模型数据的追踪接口给用户。其次,CUDA context等非框架开销也需要统计。
在这里Colossal-AI的解决思路是,在预热阶段用采样的方式,获得非模型数据对CPU和GPU的内存的使用情况。
简单来说,这是道加减法运算:
非数据模型使用 = 两个统计时刻之间系统*内存使用 — 模型数据内存使用
已知,模型数据内存使用可以通过查询管理器得知。
具体来看就是下面酱婶的:
所有模型数据张量交给内存管理器管理,每个张量标记一个状态信息,包括HOLD、COMPUTE、FREE等。
然后,根据动态查询到的内存使用情况,不断动态转换张量状态、调整张量位置,更高效利用GPU显存和CPU内存。
在硬件非常有限的情况下,*化模型容量和平衡训练速度。这对于AI普及化、低成本微调大模型下游任务等,都具有深远意义。
而且最最最关键的是——加内存条可比买高端显卡划 算 多 了。
前不久,Colossal-AI还成功复现了谷歌的最新研究成果PaLM (Pathways Language Model),表现同样非常奈斯,而微软DeepSpeed目前还不支持PaLM模型。
Colossal-AI还能做什么?
前面也提到,Colossal-AI能挑战的任务非常多,比如加速训练、节省GPU资源。
那么它是如何做到的呢?
简单来说,Colossal-AI就是一个整合了多种并行方法的系统,提供的功能包括多维并行、大规模优化器、自适应任务调度、消除冗余内存等。

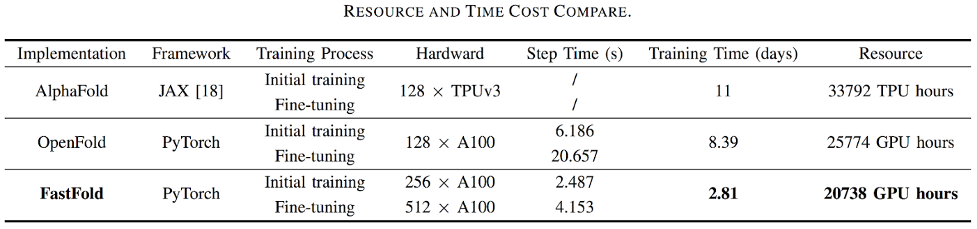
目前,基于Colossal-AI的加速方案FastFold,能够将蛋白质结构预测模型AlphaFold的训练时间,从原本的11天,减少到只需67小时。
而且总成本更低,在长序列推理任务中,也能实现9~11.6倍的速度提升。
这一方案成功超越谷歌和哥伦比亚大学的方法。
此外,Colossal-AI还能只用一半GPU数量训练GPT-3。
相比英伟达方案,Colossal-AI仅需一半的计算资源,即可启动训练;若使用相同计算资源,则能提速11%,可降低GPT-3训练成本超百万美元。

与此同时,Colossal-AI也非常注重开源社区建设,提供中文教程、开放用户社群论坛,根据大家的需求反馈不断更新迭代。
比如之前有读者留言说,Colossal-AI要是能在普通消费级显卡上跑就好了。

这不,几个月后,已经安排好了~
背后团队:LAMB优化器作者尤洋领衔
看到这里,是不是觉得Colossal-AI确实值得标星关注一发?
实际上,这一国产项目背后的研发团队来头不小。
领衔者,正是LAMB优化器的提出者尤洋。
他曾以*名的成绩保送清华计算机系硕士研究生,后赴加州大学伯克利分校攻读CS博士学位。
拿过IPDPS/ICPP*论文、ACM/IEEE George Michael HPC Fellowship、福布斯30岁以下精英(亚洲 2021)、IEEE-CS超算杰出新人奖、UC伯克利EECS Lotfi A. Zadeh优秀毕业生奖。
在谷歌实习期间,凭借LAMB方法,尤洋曾打破BERT预训练世界纪录。
据英伟达官方GitHub显示,LAMB比Adam优化器快出整整72倍。微软的DeepSpeed也采用了LAMB方法。
2021年,尤洋回国创办潞晨科技——一家主营业务为分布式软件系统、大规模人工智能平台以及企业级云计算解决方案的AI初创公司。
团队的核心成员均来自美国加州大学伯克利分校、哈佛大学、斯坦福大学、芝加哥大学、清华大学、北京大学、新加坡国立大学、新加坡南洋理工大学等国内外知名高校;拥有Google Brain、IBM、Intel、 Microsoft、NVIDIA等知名厂商工作经历。
公司成立即获得创新工场、真格基金等多家*VC机构种子轮投资。
【本文由投资界合作伙伴量子位授权发布,本平台仅提供信息存储服务。】如有任何疑问,请联系(editor@zero2ipo.com.cn)投资界处理。





