
在刚刚结束的2022华为开发者大会(HDC2022)上,升级版的手语数字人再次亮相,为大会的主题演讲进行了实时翻译。
相较去年HDC,手语数字人不仅在形象上有了优化,覆盖手语词汇量更是提高到了2万+,还能支持多达26种面部表情和准确的口动,在需要的时候实现恰当的情绪化表达,大大提高了手语的可懂度。
这样一个会手语的数字人,已不仅限于连续两年在华为开发者大会上“崭露头角”了。其实在政府网站、学校和移动应用等场景,手语数字人也已经逐渐上岗。
实际上,制作一个精良的数字人并不简单,如果要求高度定制化,技术门槛只会更上一个台阶。
这也导致当下数字人颇有种大厂“奢侈品”的味道。
毕竟,并非所有人都能承担起如此高昂费用和制作复杂度,以手语数字人为例,需求很大一部分来自于学校、公益机构等。
而在这些现象背后,其实还隐藏着数字人在制作、应用落地方面的一连串难题。
大厂竞速,降低数字人落地门槛
想要探寻数字人的落地瓶颈,还需从它的生产制作流程看起。
制作数字人的流程,可以分为建模、驱动和渲染三个阶段。
建模即搭起数字人的“基础骨架模型”,驱动负责让模型“动起来像人”,渲染则负责让模型“看起来像人”。
听起来不难,但在传统的数字人制作流程中,每一阶段都面临操作繁杂、算法门槛高、开发周期长的问题,成本更是大型企业才负担得起。
极高的制作门槛,和数字人主打的“服务场景”却并不匹配。
像银行、政务服务、直播间、景点导览、学校等需求方,往往不具备独立开发制作数字人的技术能力,能承受的制作成本更是相对有限。
这种情况下,不少科技厂商如华为竞相涉足数字人领域的研发,力图降低每个制作阶段的技术门槛。
在建模上,传统方式往往要利用多方位摄像头,对模特们打点扫描,采集说话时唇部、表情、面部肌肉、肢体细节和姿态等身体数据,随后按照需求设计建模,如卡通风、超写实风格等。
BUT,这背后需要的工作量非常大,而且需要专业人员操作。
相比之下,目前已经有更多AI算法来降低3D建模门槛,也适配不同的数字人风格。
在本次HDC上,华为就展示了一套高效的3D卡通数字人建模服务,能够帮助开发者快速构建自定义的3D卡通数字人资产。基于业界前沿的全属性特征识别和多模态基模融合两大核心技术,只需要1张照片,AI算法1秒钟就能生成一个活灵活现的卡通风格数字人,甚至连身体都能建模好。
全属性特征识别技术能够对发型、眼形、眉形、胡子和眼镜等面部主要属性迅速而精准地识别,每个部分又可细化到常见的特征,如单双眼皮、卷直发等,实现美与像的平衡。
值得一提的是,这样的神经网络模型非常轻量,大小仅在KB级别(不到1MB),推理时间更是达到毫秒级,大部分情况下识别准确率超90%;
而如何在毫秒级时间内,仅凭一张照片就“拼”出最合适的卡通化人脸,同时换上最合适的风格,则是多模态基模融合技术的能力。
依托大量基础几何(1k+)和形状素材(100+),配合百万级的AI训练数据,高效建模得以轻松实现。
通过3D卡通数字人建模服务和HMS Core手语服务的配合——无论是热情活泼的手语老师,还是端庄亲和的手语直播主持人,都能快速搞定。
建模完成后就是驱动和渲染了,让模型不仅能像人一样表情自然、肢体动作流畅,还能具备一定语言理解表达能力。
传统平台虽然有动作库、降低人工制作难度,但最复杂的往往是两个动作之间的过渡、以及将语音文本和表情逐帧对应的过程。
目前有大厂已经试图在用算法搞定动作过渡,至于语音文本和表情对应则可以用AI算法来降低工作量。

此次HDC,华为正式发布的HMS Core 3D Engine,不仅能进行超大规模数字世界的实时渲染,对于数字人的驱动也专门提供了一套能搞定实时骨骼动画、表情动画、脚步/全身IK、布娃娃系统、动画重定向、多重动画融合的“工具包”。
3D Engine的动画编辑器不仅支持创建多个动作状态机,而且还能对多个角色的动作进行平滑过渡,解决数字人动作之间“不流畅”的问题。
除了单纯的动作驱动,让数字人具备理解表达能力,同样是决定驱动真实性的一环。
HMS Core的手语服务,用AI算法给数字人打开了“手语表达与理解”能力。
基于大量深度学习算法,让模型学习语音、唇形、表情参数间的潜在映射关系,手语服务通过HMS Core 3D Engine驱动模型在接收到输入信号时,自动做出对应的动作。
建模和驱动之后,就来到最终的渲染部分。
传统方法往往计算量极高,更别提直播场景中常见的实时渲染。
尤其是写实数字人,为避免高时延,实时渲染往往选择牺牲数字人的真实感,包括皮肤、头发和眼睛等部位,想要打造真实感难度非常高,最后往往只能采用3D卡通数字人来完成实时直播。
在这种背景下,HMS Core的3D Engine在实现在实时渲染的同时,还尽可能还原写实数字人真实的效果。利用3D Engine呈现出来的数字人,不仅能与场景进行实时交互,在皮肤材质、发丝仿真、眼球材质等渲染上也足够细致,这些细节直接影响了数字人的逼真程度。
皮肤材质上通过次表面反射、双叶高光对皮肤的光泽度和通透感实现了增强,呈现出了更自然的皮肤效果。
在发丝上,则是通过实时物理模拟完成10万+发丝运动,来增强头发的阴影、半透明和高光渲染效果。
眼球还原上甚至精确到了虹膜、瞳孔、巩膜、晶状体折射率等,根据参数进行调整。
整体来说,相较于传统数字人制作流程,从降低门槛、提高易用性等维度出发, HMS Core提出了一个更为简易的数字人全流程解决方案。
背后技术能力并不简单
其实,面临数字人落地的难题和机遇,国内外不少公司都在投入这一赛道角逐。
这其中既包括苹果、Meta和英伟达等科技巨头,也有Neon和DATAGRID等初创公司,凭借自身软硬件优势“扩张”在数字人行业的版图。
在赛道玩家云集的情况下,华为降低用“人”成本的底气何在?
一方面,在AI等技术上,华为这些年也在不断地进行研究和积累。
据华为介绍,在NeurIPS近五年来引用最多的50篇论文、以及ACL近五年来应用最高的20篇论文中,都各自有一篇华为诺亚方舟实验室的论文,同时ACL引用最高的30篇论文中,更是有3篇相关论文。
华为轮值董事长徐直军,此前也透露过华为的AI研发数据:仅2018一年,华为的AI研发投入就达到15亿美元,研发团队更是超过5000人。
具体到内容上,这些论文中就有不少像多模态技术这类与数字人息息相关的研究。
被ACM Multimedia 2022收录的一篇新论文中,华为泊松实验室就联合人大高瓴人工智能学院提出了一种名叫MMTG的新模型,意图让AI看到图文混杂的输入时能理解它们的关联,并创作出新的文本,进一步提升数字人的表达能力。

另一方面是独特的应用场景优势,作为鸿蒙生态的重要组成部分,HMS Core提供的一系列全面的端、云开放能力,为数字人在移动端乃至鸿蒙生态上的落地提供了有力的支持。
通过HMS Core 3D Engine和手语服务打造的手语数字人,已经开放给畅听无碍、知音等第三方App集成接入,实现在手机上的直接使用,为听障人群带来生活的便利。
2700亿市场如何把握?
事实上,不止手语数字人,目前更多场景都面临着使用数字人的情况。
据《量子位虚拟数字人白皮书》预测,2030年我国虚拟数字人市场规模将快速增长至2700亿。
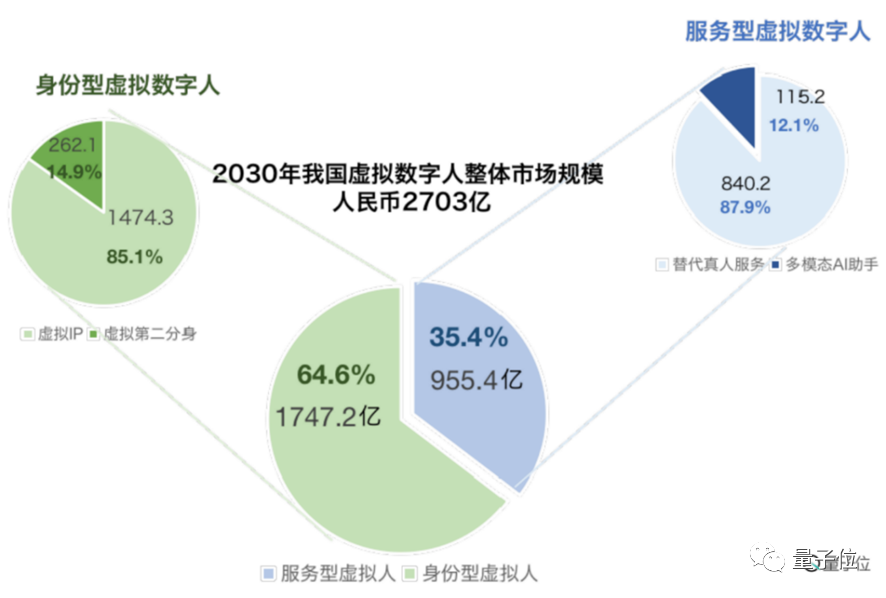
按需求场景划分,主要有身份型虚拟人和服务型虚拟人。
身份型虚拟人即虚拟偶像、真人人偶分身等,服务型虚拟人的常见应用场景有银行、政务大厅、播音室等。
比如在银行数字化转型趋势下,数字人银行客服通过语音交互,就能以更贴近于传统柜台的方式,提供更加人性化便捷的服务;
还有手语翻译场景,我国听障人群数量达到2700万,但专业手语翻译师的数量恐怕还不到1万。3D手语数字人在弥补专业人才缺口的同时,也能快速普及国家通用手语。
目前,我们已经能看到越来越多的数字人开始上岗工作,随着华为等大厂的技术投入,其成本和使用门槛也在进一步降低。
【本文由投资界合作伙伴微信公众号:量子位授权发布,本平台仅提供信息存储服务。】如有任何疑问,请联系(editor@zero2ipo.com.cn)投资界处理。





