
Chat GPT热度尚未退散,一场大会又将AI大模型的注意力推向新高度。
在刚刚举办的北京智源大会上,汇聚了众多传说中的AI大佬,以张钹、张宏江为代表的国内AI最前沿领军人物,Geoffery Hinton、Yann LeCun、姚期智、Joseph Sifakis这四位图灵奖得主,Open AI创始人Sam Altman、PaLM-E和RoBERTa等AI公司高管。
因每次的智源大会秉承着专业的学术思想路线,因此在国内外人工领域内行精英圈层口碑极高,但对大众来说,却稍显高冷。而在本次大会上,Sam Altman指出为搞清楚通用AI技术的发展,Open AI必须要推进AI研究变革。
但这一说法却遭到了不少AI大佬们的反对。其中,加州伯克利分校教授斯图尔特·罗素抨击Open AI研发的Chat GPT和GPT-4没有在“回答”问题,它们不理解世界,也不是一个通用AI的发展步骤。杨立昆更是直接指出,当前的GPT自回归模型存在缺乏规划、推理的能力,未来GPT系统或将被抛弃。
除激烈的学术争论外,关于当前AI如何监管、后续AI的发展方向也成了本次会议讨论的焦点。
1、后续AI到底要如何监管?
进入到2023年以来,在生成式AI以势如破竹的速度席卷诸多领域的同时,由AI所引发的各种问题也在加剧外界的担忧。
在我国,“AI诈骗”成为近期社会关注的方向之一。日前,内蒙古包头警方通报一起利用AI实施诈骗的案件,福州市某公司法人代表郭先生10分钟内被骗430万元。据通报,骗子通过AI换脸和拟声技术,佯装熟人实施诈骗。无独有偶,江苏常州的小刘被骗子冒充其同学发语音、打视频电话,小刘看到“真人”后信以为真,“借”了6000元给骗子。
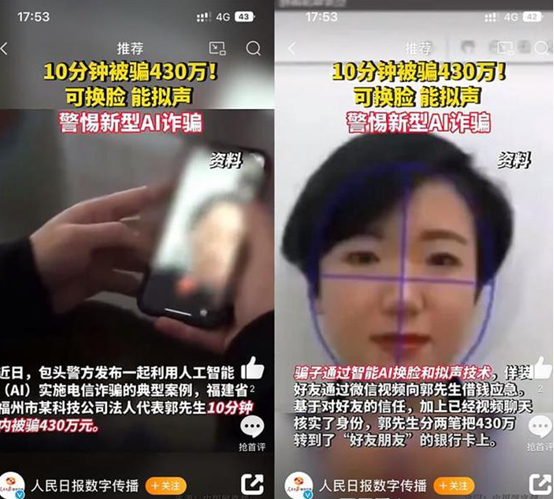
图源:抖音
事实上,AI诈骗案发生的背后还是和当前AI技术迅速发展,技术合成门槛持续降低有关。而从后续来看,若AI大模型技术不断突破,未来也将逐渐从面部合成转向到全身合成、3D合成技术,其合成效果也将更加逼真。
在美国,AI是否会影响选举成为当地媒体讨论的重点。据美联社报道,如今复杂的生成性AI工具能在几秒钟内“克隆”某人的声音和形象,制造出大量“假料”。只要绑定强大的社交媒体算法,AI就可以迅速锁定受众进行传播,以前所未见的规模和速度破坏选举。
美国其他媒体则预测,因美国下一任总统选举是在明年举行,不排除美国两党将使用AI技术用于宣传、筹款等活动。更重要的是,因Chat GPT在文本能力上有着*的表现。因此,参选者的团队仅需在几秒钟就能生成一份措辞华丽的演讲稿。
基于外界对AI的种种担忧,日前,由“AI教父”杰弗里・辛顿、Anthropic的首席执行官达里奥・阿莫代,Google Deep Mind首席执行官戴米斯・哈萨比斯等超过350位AI领域高管和专家共同签署了“减轻AI带来的灭绝风险,应该与流行病和核战争等其他社会规模的风险一起,成为全球优先事项”的联合声明。

针对后续AI如何监管的问题,Sam Altman在智源大会上指出,目前Open AI正在通过多种方式来解决这一问题。首先,早在5月26日,Open AI启动了一项激励计划,出资100万美元,向社会征集有效的AI治理方案。
其次,Sam Altman认为人类是无法发现一些恶意模型在一些邪恶的事情。目前Open AI正在投资一些新的、互补的方向,希望能够实现突破。但可扩展的监督是尝试使用AI 系统来协助人类发现其他系统缺陷,而解释能力是用GPT-4解释GPT-2神经元,虽然还有很长的路要走,但Open AI相信机器学习技术可进一步提高AI可解释能力。同时,Sam Altman也认为未来只有把模型做得更智能,更加有帮助,才能更好地实现通用AI的目标优势,进而降低AI风险。
最后,Open AI短期内虽不会推出GPT-5版本,但未来十年全球可能会拥有更强大的AI系统,全球范围内需做好提前准备。而Open AI后续对AI大模型的核心工作仍是训练,并且准备在全球建立一套数据库,以反映全球AI的价值观和偏好,即时向全球分享AI安全研究。
除Open AI自身努力外,Sam Altman也呼吁全球共同努力来完善对于AI的监管。比如说,Sam Altman指出当前中国拥有一些世界上*秀的AI人才,考虑到解决 AI 系统对齐的困难需要来自世界各地*的头脑。
因此,Sam Altman也希望未来中国AI研究人员能够在AI风险上做出贡献。Tegmark也认为,目前中国在人工智能的监管方面做得最多,其次则为欧洲,最后则是美国。

图源:智源大会
另外,Sam Altman也指出,全球AI监管的合作困难是有的,但这也实则是一种机遇。AI在让全世界走到一起的同时,后续也需要出台系统性的框架和安全标准。
但考虑当前全球大国和大国之间的博弈加剧,地缘冲突呈现多点式爆发,各国政府对生成式AI的态度不一,这在让全球关于AI监管的合作短时间难以落地的同时,也会影响到生成式AI公司的市场业务。
欧洲一直走在AI监管的前沿,5月份欧盟已经接近通过一项人工智能技术监管的立法,这也有望成为全球首部全面的人工智能法案,并可能成为发达经济体的先例。
欧盟委员会主席乌尔苏拉·冯德莱恩此前在接受媒体采访说曾表示,“我们希望人工智能系统准确、可靠、安全且无歧视,无论其来源如何。欧盟相关法律法规的出台,可能会让Open AI后续退出欧盟市场。因此,后续如何根据全球监管政策的调整,不断完善自家的生成式AI模型,这不仅仅是Open AI自身遇到的问题,更是全行业需不断关注的问题。
2、生成式AI未来的发展方向在哪?
不可否认的是,当前GPT-4在诸多能力上得到了很大提高。和GPT-3.5相比,GPT-4在复杂专业领域的性能表现大幅提升,逻辑推理能力也更强,其在美国律师资格考试测试中,GPT-4的成绩可以达到前10%,但GPT-3.5只能达到后10%的水平。
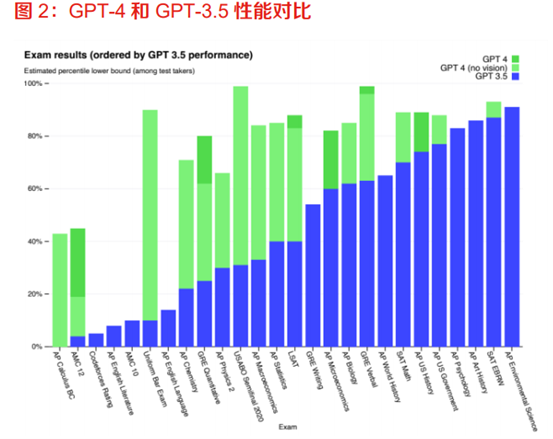
图源:Open AI
能力的大幅度提高,也让Chat GPT正开拓更多的使用场景。目前OpenAI官方也给出了几大应用场景,如在Duolingo里加入AI与用户进行日常聊天,加速用户对语言的学习;摩根士丹利采用GPT-4来对其知识库进行管理,帮助员工快速访问想要的内容。
但针对GPT目前的能力,也有不少大佬存在质疑。斯图尔特·罗素在演讲中指出,Chat GPT和GPT-4他们并不理解世界,也没有在“回答”问题,目前的大语言模型仅仅只是一块拼图,这个拼图目前缺少哪些以及最终会拼成什么样,这些均不确定。诸多能力上的欠缺,也决定了发展通用人工智能还有很长的路要走。基于对GPT-4能力的种种质疑,也让斯图尔特·罗素在Sam Altman在演讲期间全程在修改PPT。

图源:智源大会
和斯图尔特·罗素持有相同观点的也有来自图灵奖”得主、“深度学习三巨头”之一、Meta首席人工智能科学家杨立昆。他认为,当前GPT的自回归模型因缺乏规划,导致其推理能力目前整体不行。若单纯根据概率生成自回归的大语言模型从本质上根本无法解决幻觉,错误的问题。在输入文本增大的时候,错误的概率也会呈指数增加。
事实上,两位大佬对GPT的指责并非不是没有道理。因Chat GPT所使用的RLHF算法,本身就是借助人类的感知,让模型判断自己的答案质量,训练自己逐步给出更高质量的回答。若想要让模型的推理能力得以提高的话,则需要在补充数据库大量参数的同时,对算法也要进行不断迭代。

图源:西南证券
但各种风险的存在,也让众多生成式AI公司并不敢轻易尝试。若生成式AI能到达和小说作家一样的具备故事推理能力,以及人物情感创造能力,这是否会让生成式AI完全脱离人类的控制呢?这在引发全球恐慌的同时,又是否会遭遇来自当地政府的强监管,进而让生成式AI此前的投入付诸东流呢?
针对未来生成式AI的发展方向,杨立昆给出的答案是世界模型。这个世界模型不单单是神经水平上模仿人脑的模型,而是在认知模块上也完全贴合人脑分区的世界模型,它与大语言模型*的差别在于可以有规划和预测能力(世界模型)以及成本核算能力(成本模块)。
借助世界模型能够更好地理解这个世界并预测和规划未来,通过成本核算模块,结合一个简单的需求(一定按照最节约行动成本的逻辑去规划未来),它就可以杜绝一切潜在的毒害和不可靠性。

图源:智源大会
但问题是世界模型在训练期间的参数、算法、成本等等问题,杨立昆也只是简单地给出了一些战略级想法。比如采用自监督模型去训练以及建立多层级的思维模式等等,但对于具体如何落地,杨立昆也无法给出一个完整的方案。
而其他参会嘉宾对于未来生成式AI的发展方向,也并没有分享自己的看法。因此,后续生成式AI仍将维持各家“各自为政”的局面,全球统一的生成式AI或许也只能停留在实验室阶段。
3、国内生成式AI预测
智源研究院院长黄铁军教授在会后接受媒体采访时说,当前国内生成式AI大模型存在的问题是行业过热,但训练数据过小,现在百亿模型也只是刚刚涌现能力。虽然中间也都有一些技术能力,但因重复性发力,这在让行业资源愈发分散的同时,其智能水平和国外生成式AI大模型相比,仍有一定差距。
如黄铁军教授所言,以阿里旗下的“通义千问”大模型为例,因该大模型训练时的数据是从阿里旗下的淘宝、支付宝、天猫等产业中抽取的大量中文对话和文本数据,以及一些其他来源的文本数据,其前期训练数据量是约2000亿个词,相当于14TB的文本数据。
而Chat GPT的训练数据量是约45亿个词,相当于300GB的文本数据。训练数据的相对较小,让阿里的“通义千问”也欠缺多模态能力,在文字方面上来看二者均和GPT-4有较大差距。
另据InfoQ 研究中心发布的《大语言模型综合能力测评报告2023》数据显示,目前Chat GPT以77.13%的综合得分*于国内其他的大模型厂商。
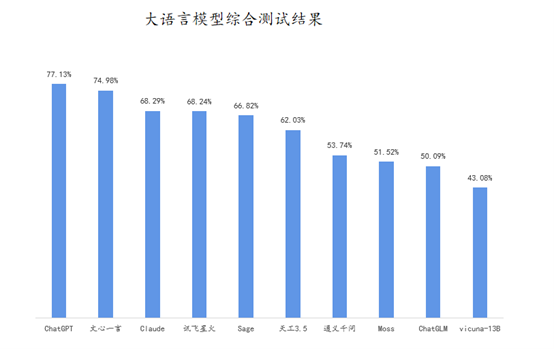
图源:《大语言模型综合能力测评报告2023》
同时,黄铁军教授也指出,今天的大模型都是技术迭代的一个中间产品,随着后续国内大模型行业的发展,未来能够存活的大模型生态合理数量为3个左右。
正如黄铁军教授所说,此前马化腾在腾讯内部的高层会议上曾指出,未来十年C端市场红利将消失殆尽,整个希望在ToB端市场,互联网的下半场则属于产业互联网。阿里商业研究院此前也指出,未来十年是传统企业转型的黄金风口。
但从ToB端市场来看,以发展多年的SaaS市场作为参考,大模型若想要真正打开ToB端市场,其核心一定是要客户带来“降本增效”的价值,尤其是在当前不少行业对大模型仍保持观望的情况下更是如此。以传统制造业为主,目前中小型传统制造业普遍遇到的问题是订单减少,行业一直在价格战中厮杀,下游回款周期变长,许多中小制造业目前均是在苦苦支撑。为避免出现较高的试错成本,不少中小制造企业自然不敢轻易尝试大模型的使用。
并且从SaaS产业的发展历程来看,自2004年初期开始国内SaaS产业在经历了波澜不惊的10年之后,于2015年迎来了一波生长高峰。从2020年疫情暴发至今,疫情加速企业数字化转型,国内SaaS市场进入了关键的生长期。但即使如此,当前国内SaaS产业生态尚未完整,市场并未成熟。
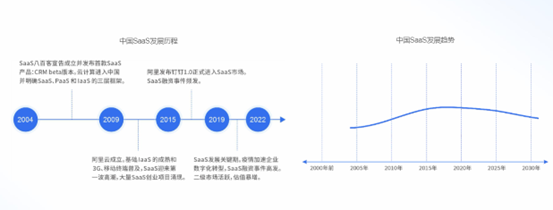
图源:Flash Cloud
显然,大模型打开TOB端市场也并非一朝一夕,而是一个极其缓慢的过程。而且模型迭代其间因算法、算力、数据产生的成本,包括后续推出各种功能,均要求大模型公司不断投入高额资金。
商业化落地时间长,资金投入高,短期内难以盈利等问题的存在,后续也会让缺乏现金流的企业,在资金压力面前只能将企业自身的大模型进行关停,行业资源也会更加向头部大模型厂商身上集中。
而从网约车、外卖等多个行业的经验来看,一个新兴行业在历经多年的大浪淘沙过程中,后续能够真正发展起来的企业也只在3家左右,其他不少企业则被淹没在历史的长河中。
4、结语
不可否认的是,生成式的AI能力正在逐渐被市场所认可,但如何对AI进行监管将会是后续全球多国一直要重视的问题。
而对于我们普通人担心未来是否会被AI抢走饭碗,引发自己失业所产生的焦虑,或许正如Tegmark所说,经济和就业市场的变化会越来越快,如果你在基础知识方面很强,并且非常善于创造性的开放思维,你就可以灵活地随波逐流。
【本文由投资界合作伙伴微信公众号:DoNews授权发布,本平台仅提供信息存储服务。】如有任何疑问,请联系(editor@zero2ipo.com.cn)投资界处理。





