
6 月 26 日晚,猎豹移动 CEO 傅盛在朋友圈转发了一篇名为《朱啸虎:ChatGPT对创业公司很不友好》的微信文章,附评论「硅谷一半的创业企业都围绕 ChatGPT 开始了,我们的投资人还能这么无知者无畏」。
这一转发很快引起了文章中的当事人、金沙江创投董事总经理朱啸虎的回击,称「绝大多数创业公司在 ChatGPT 面前都毫无价值」,并举例细分赛道中受 ChatGPT 冲击*的两家创业公司 —— 做自动语法纠错的 Grammarly 以及使用 ChatGPT 实现自动营销文案生成的 Jasper。
这场辩论,最终以两人在「创业公司很难(借助大模型)获得再造 BAT 的机会」这一点上取得共识而结束。但在这场辩论之外,「大模型商业化应该怎么做」这件事,是除了产品进展之外业界最关注的领域。
01 OpenAI 的失败
在沉寂一个多月之后,OpenAI 也酝酿着下一次面向大模型商业化领域的冲击:据 The Information 报道,OpenAI CEO 山姆-奥特曼在六月的一次内部会议中表示,正在计划创建一个「大模型应用商店」,作为大模型商用领域的一次新尝试。
知情人士透露,OpenAI 计划推出的这个「应用商店」,将会是允许 OpenAI 客户自行上架定制大模型,再根据其他企业的实际需求,进行定制化销售的平台。
这意味着 OpenAI,再一次将「大模型 App Store」这件事提上了日程:这已经不是 OpenAI *次尝试将 ChatGPT 变得更加「商业化」:在一个月之前,OpenAI 已经推出过类似的「应用商店」项目 —— 彼时 OpenAI 开放了 ChatGPT 第三方插件商店,允许用户直接从中下载到第三方插件,整合进自己的 ChatGPT 中拓展至更多使用场景。
但这一模式并未如 OpenAI 所愿,让 ChatGPT 掀起新一轮的应用浪潮,迄今为止应用商店中大部分插件的下载数量仅为几万次,几个由较大服务商开发的 ChatGPT 插件,也仅有十几万下载量,并未将这一模式真正推广给大部分用户。
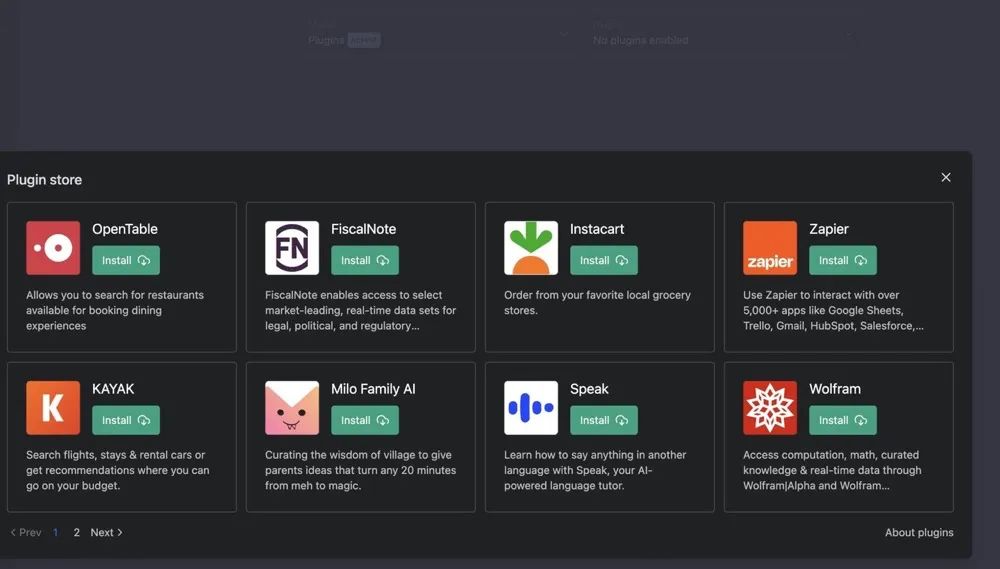
这直接暴露出 OpenAI 在大模型领域真正的短板:大模型的商业化运用不仅需要超前于时代的技术,同时也需要超前于时代的大模型商业运营模式。
通用语言大模型设计的主要目的,是为了直接面对全球数十亿的用户,回答上百亿种各式各样的问题,并非为了在某一个专业领域,解决某一种特殊的行业问题,所需语料来源一般也都是广泛的公开文献与网络信息,网络信息不仅可能有错误、有谣言、有偏见,许多专业知识与行业数据积累不足,导致模型的行业针对性与精准度不够。但在产业场景中,用户对企业提供的专业服务要求高,容错性低。企业一旦提供了错误信息,可能引起巨大的法律责任或公关危机。过去已经发生过多起类似的事件。
这是 ChatGPT 与主流行业用户需求之间最重要的错位,也是 ChatGPT 并未能在大模型商业化中取得更多成绩的原因。
如今,即使 OpenAI 是这个 AI 时代中最重要的开拓者,当 OpenAI 在商业化大模型领域的开拓遇到了瓶颈,也不得不转而与曾经的合作伙伴兼股东的微软,变为业务上的直接竞争对手:如果 OpenAI 最终将开放「大模型应用商店」,也就意味着 OpenAI 将正式深度参与到大模型的商业化领域。
值得注意的还有国内大模型动态:虽然国内大模型行业在前沿研究领域与 OpenAI 等*梯队仍有差距,但在商业化落地领域国内大模型行业的研究几乎已经走在了世界前沿:按照 AI 创业者季逸超(Peakji)的看法,未来大模型的主要应用方式将变为 ToC 本地运行, ToB 私有化部署的形态,前者为体积较小的「小模型」,直接部署在手机/电脑中,直接借助于设备本身的算力,来完成一些简单的生成式 AI 工作。
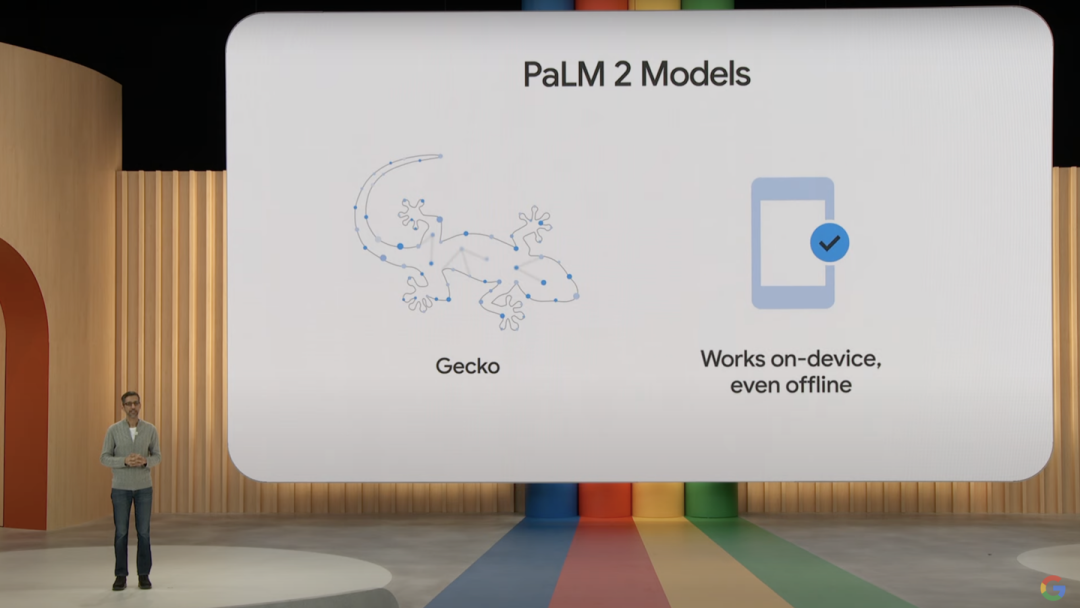
这也是 Google 在今年 I/O 大会中发布了同时发布四个不同体积版本的 PaLM 2 模型的原因,其中体积最小、代号为「壁虎」的大模型,完全能直接在设备本地端离线运行的生成式人工智能,完全不占用任何云端计算算力。相对而言由于体积较小,一般通用大模型能搭载上百亿个参数,这些本地运行的大模型可能只需数亿个模型,即可自主完成包括自然语言理解、语音识别、图像识别等手机中常用的 AI 场景。
02 私有化部署
正如朱啸虎所言,行业对于大模型主要的期待,在于「能不能解决问题」,因此私有化部署将会是未来行业大模型的关键趋势, 即将主要的 AI 大模型,根据客户的实际需求进行深度定制,搭配不同性能的计算集群/数据库,针对每一个用户类型,打造对应的模型来提高工作效率。
在 OpenAI 之前,私有化部署的 AI 大模型产业已经愈发成熟:海外的微软、Salesforce,国内的腾讯云,其实都已经盯上这一市场;Saleforce 已经在为行业客户提供基于 GPT-4 的定制聊天机器人业务,对于这些依赖出售定制大模型服务的厂商来讲,通过 OpenAI 提供的应用商店平台,也能接触到更多潜在用户。
但无论是私有化部署还是直接借助于现有的通用大模型产品,为了让现有的人工智能能力与用户的实际需求更好的匹配,大模型所需的原材料 —— 数据,都是至关重要的一环:这也是目前腾讯云大模型的合作中,在与包括上海大学、中央电视台等行业需求用户携手定制的原因。
「既要保证数据的质量与覆盖,也需要关注敏感数据的保护与安全合规,这些对于企业用户使用大模型来讲至关重要」腾讯集团高级执行副总裁、云与智慧产业事业群 CEO 在介绍大模型数据时认为算力与服务都是目前推动大模型私有化部署的关键背景。
一位数据分析领域创业公司 CEO 对记者表示:除了大模型技术类人才目前极度短缺以外,目前拥有「大模型使用经验」的产品经理,目前在行业中都仍算是凤毛麟角的存在,即使很多数据分析公司都对大模型有着极高的期待,但由于专业人才的缺失、加上用于专业辅助训练的语料不足,现有的生成式对话机器人在未经专业定制之前,甚至很难满足入门级别的行业需求。
谁能「交付最终服务」,谁就能在当下最快速地占据最多的 AI 大模型市场。MaaS(Model-as-a-Service)模式也就成了如今巨头们提供大模型服务时,不约而同的选择。
MaaS 模式的大行其道,也催生出众多不做通用大模型、专做 toB 市场的行业大模型厂商:除了腾讯云之外,还有华为发布的盘古大模型,其主要方向即是 AI for Industry(AI赋能产业),为煤矿、水泥、电力、金融、农业等行业。
根据腾讯云发布的相关数据,目前大模型的主要落地场景还是集中在金融/客服,以及教育领域:在海外有 OpenAI 与可汗学院合作、开发定制聊天机器人、帮助学生准备考试用复习材料,同时也杜绝学生使用 AI 机器人来直接作弊;上海大学借助腾讯云TI平台将大模型探索应用在咨询和问答场景,能为学生提供咨询、问答,以及跨模态检索等能力。
诚然,也有很多大模型业内人士认为,将数据/算力/服务全部交由一家公司来完成的私有化部署模式,等于将用户数据与模型的产权/源代码都被「垄断」,可能会导致人工智能发展过于中心化,但就目前的情况而言,已经达到能够商用程度的开源大模型选择仍然不多,以及在构建成本高昂的数据中心面前,尽可能地降低大模型的使用成本,或许才是很多企业应该优先考虑的事。
在傅盛与朱啸虎的朋友圈辩论中,傅盛认为,ChatGPT 本身固然有其巨大商业价值,但如果 ChatGPT 本身占据了 99%(的价值),那整个 AI 生态也完全无从谈起。不同于目前的 MaaS 模式,大模型应用商店更像是现在手机中的 App Store,最终能与其中的所有应用,共同将大模型商用市场拓展至更多场景。
在商业模式上,ChatGPT 目前已经依靠订阅制(GPT4)、付费 API,探索出一条行之有效的盈利模式,同时也积累了海量来自 C 端用户的语料等关键数据,但这并不代表「大模型应用商店」,能够在如今的大模型商用领域再一次成功。想要让 ChatGPT 在商业化取得更多成功,摆在 OpenAI 面前的问题仍然棘手:不同大模型之间涉及到的版权/数据问题如何解决,以及更加实际的安全/道德问题。
但毋庸置疑,目前的大模型商业化生态中,MaaS 已经作为一种成熟的应用模式,出现在了市场中,「开箱即用」的模式已经吸引了很多行业用户前来试水,进而借助这个契机,改变越来越多行业。
【本文由投资界合作伙伴电厂授权发布,本平台仅提供信息存储服务。】如有任何疑问,请联系(editor@zero2ipo.com.cn)投资界处理。





