
高性能计算(High performance computing),是一种利用超级计算机或计算机集群的能力实现并行计算,以处理标准工作站无法完成的数据密集型计算任务的技术,常见的应用领域有仿真模拟、机器学习和深度学习等。
或许有人没有听过HPC,但是一定听过超级计算机,它就是HPC的主要实现方式之一。数据显示,高性能计算系统的运行速度比商用台式机或服务器系统快一百万倍以上。原因在于高性能计算能够让整个计算机集群为同一个任务工作,以更快的速度来解决一个复杂问题。
HPC提供了超高浮点计算能力解决方案,可用于解决计算密集型、海量数据处理等业务的计算需求,如科学研究、气象预报、计算模拟、军事研究、CAD/CAE、生物制药、基因测序、图像处理等,大量缩短计算时间,提高计算精度。
此前,HPC由于其专业度极高的特点被局限在科研实验室、大型企业和特定的学术组织研究中。不过随着近两年AI技术与IoT应用之间的互相驱动,数据量和计算需求暴涨,5G将数据传输管道大大拓宽之后,同样给了数据囤积量进一步拓展的空间,HPC也逐渐变得日益重要。
目前,国产高性能计算机已经取得了不错的成绩。
01
中国高性能计算机成绩斐然
2023 年 6 月,最新一期超级计算机 TOP500 榜单公布,从TOP500 榜单中就可以读出中国在*超级计算机研发上的努力已经凸显出来。
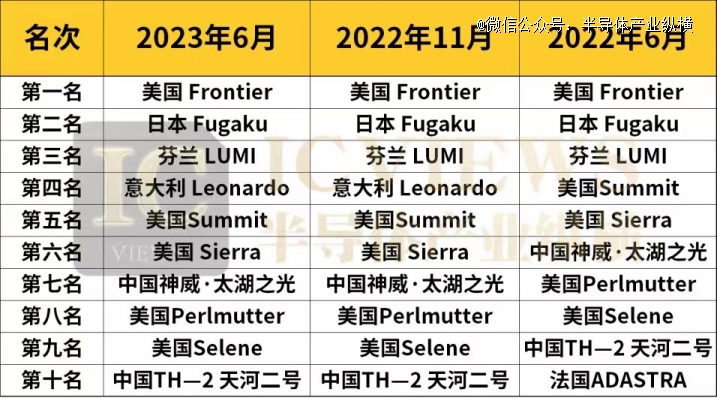
在61期全球超级计算机 TOP500 榜单中*的是美国的Frontier、第二名为日本的Fugaku、 第三名芬兰的LUMI、第四名意大利Leonardo、第五名美国Summit、第六名美国Sierra、第七名中国神威·太湖之光、第八名美国Perlmutter、第九名美国Selene、第十名TH—2 天河二号。
历年来,中国高性能计算机屡屡登榜 TOP500。神威·太湖之光超级计算机甚至曾连续获得top500四届冠军,该系统全部使用中国自主知识产权的处理器芯片。天河二号也曾6次蝉联冠军,天河二号采用麒麟操作系统,目前使用英特尔处理器,将来计划用国产处理器替换。
不只是排名*,在上榜数量上,中国的高性能计算机也有实力“扛大梁”。
根据 2023 年 6 月公布的最新 TOP500 榜单,美国为超级计算机上榜数量最多的国家,共上榜 150 套,占比 30%; 中国以 134 套上榜数量紧随其后,占比 26.8%; 除中 美两国之外,德国、日本、法国、英国、加拿大均有 10 套及以上进入 TOP500 榜单的超级计算机系统。
中国初步形成的高性能计算产业链由上、中、下游构成,以上所述企业均为中游企业,他们的角色是负责对上游的资源进行整合,提供强大的超算资源。
看到此处想必已有不少人开始疑惑,中国CPU的发展之路道阻且长,那么中国高性能计算机又是如何取得今日这番成绩的呢?其上下游的发展现状又如何了?
在这之前首先要了解的是,高性能计算机的发展历程。
02
高性能计算机的发展历程
1975年,中国开始研制*台超级计算机。1983年,“银河1号”面世,之后又研制出曙光系列超算。2009年,“天河1号”超算诞生,这是我国第1台千万亿次级超算。2010年,经过升级之后的“天河1号”位居全球计算机500强*位。2013年,“天河2号”再次名列超级计算机500强排行榜世界*,并蝉联多年。
值得注意的是,当时中国所有的超级计算机都采用了英特尔的芯片,中国多次在全球超级计算机TOP 500强榜单中夺冠的天河二号使用的就是英特尔的Xeon众核处理器+Xeon Phi加速卡。
随后2015年,美国政府禁止本国企业向中国出口与世界上最快的超级计算机相关的技术,国家超级计算长沙中心、广州中心、天津中心和国防科技大学四家国家超算中心被列入出口管制名单。
不过,管制并不能阻碍中国高性能计算机发展的步伐。2016年6月20日,在法兰克福世界超算大会上,“神威·太湖之光”超级计算机系统震撼亮相,登顶榜单之首,不仅速度比第二名“天河二号”快出近两倍,其效率也提高3倍。“神威·太湖之光”共有40960块处理器,全都采用了中国自研架构的“申威26010”众核处理器。
并且除了“神威”系列,“天河”系列和“曙光”系列超级计算机也都自研了芯片,像“天河”系列超级计算机已经全面掌握“五大”自主核心技术,即具有自主知识产权的四大芯片和自主操作系统。
接下来再看,高性能计算机与CPU的“命数不同”。
03
高性能计算机与CPU“命数不同”
众所周知,一台普通电脑一般只有一颗 CPU(GPU 同理),每颗 CPU 内一般只有2~8 个物理核心,而一般的超级计算机有成千上万颗 CPU,每颗 CPU 内一般有几十个物理核心。
比如2010年,位居全球超级计算机500强排行榜榜首的“天河一号”,其思路采用“CPU+GPU”的设计思路,结合了大约7000个英伟达GPU和14000个英特尔CPU,将GPU用于超级计算机,起到了“CPU加速器”的作用。尽管“天河”的主要部件仍来自英特尔与英伟达两个美国制造商,但互联芯片则完全是中国自主研发,“天河”安装有由中国自主研发的“飞腾1000”芯片,部分取代了进口芯片。
“天河2号”有16000个计算节点,每个节点由2片英特尔的E5 2692和3片Xeon PHI组成,共使用了32000片英特尔的E5 2692和48000片Xeon PHI,属于CPU+众核芯片。正在升级的“天河2号”则将美国的Xeon PHI换成了自主研发的矩阵2000,属于CPU+DSP。
神威·太湖之光超级计算机安装了40960个中国自主研发的申威26010 众核处理器,该众核处理器采用64位自主神威指令系统,峰值性能为12.5亿亿次每秒,持续性能为9.3亿亿次每秒,核心工作频率1.5GHz。
对于普通家用的电脑来说或许需要一个性能更高的CPU来为整机提供更好的调度能力,然而对于超级计算机来说并非如此。超级计算机的算力大小并不依赖狭义上的CPU,超级计算机需要的是浮点算力,此外超级计算机还要看能耗,所以靠堆砌堆上去的单核心性能,对于超算系统未必合算。另外还有散热问题、单核心的能耗比也是需要考量的因素。也就是说,超级计算机比拼的是超算架构、调度算法、并行度等等。
所以单个CPU综合算力并不是决定性因素,高性能计算机也并非简单的堆料。CPU要完成单核性能的冲刺需要面临底层指令集以及生态等因素的束缚,而对于高性能计算机来说,更强的芯片协同工作能力或能带来不菲的效果,这也正是中国的强项。
04
CPU+GPU国产势力大增
多年来,Intel、AMD两大巨头领跑通用CPU(桌面与服务器CPU)市场;不过随着国家的大力支持引导,国产CPU也开始奋力追赶,并且有所成绩。
国产CPU的优秀企业有走X86技术授权路线的海光和兆芯,ARM指令集授权路线的华为鲲鹏和飞腾,以及自研指令集路线的龙芯和申威。
目前,龙芯中科是目前中国CPU企业中自主程度最高的企业之一,近日龙芯发布的基于龙架构的新一代4核心8线程处理器龙芯3A6000流片成功,龙芯称综合相关测试结果,龙芯3A6000处理器总体性能与Intel公司2020年上市的第10代酷睿四核处理器相当。3A6000流片成功也代表了中国自主桌面CPU设计领域的最新里程碑成果。
申威主要面向军用等对安全性要求极高的特种领域,为其提供CPU处理器及其相关解决方案。在神威、太湖之光中使用的SW26010芯片,在服务器领域,浮点运算算力相比于同期国外处理器毫不逊色。
海光也是CPU市场的优秀标的,其CPU主要面向数据中心的服务器,产品兼容x86 指令集以及国际上主流操作系统和应用软件,软硬件生态丰富,性能优异,安全可靠。
此外,鲲鹏、飞腾和兆芯都是国产CPU的佼佼者。
鲲鹏 920已实现通用计算最强算力,性能优于其他厂商的同类型芯片。有测试结果显示,48核心的鲲鹏 920可以与Intel至强8180媲美,64核心的鲲鹏920甚至超过Intel至强8180。兆芯掌握自主通用处理器及其系统平台芯片研发设计的核心技术,全面覆盖其微架构等关键领域,构建了较为完整的知识产权体系。飞腾面向各类应用场景,已构建了1000多个从端到云自主可信的行业联合解决方案,芯片交付累计超过600万片,在国产CPU市场上占据了半壁江山。
再看GPU。国内优秀的GPU芯片公司有寒武纪、华为昇腾、沐曦科技、海光信息、壁仞科技、阿里平头哥、燧原科技、天数智芯、景嘉微等。据悉,思元即将推出的590整体算力综合性能大约是A100的70%。华为昇腾910算力强悍,在实际应用过程中,昇腾910的处理速度比业界同类产品快80%以上。
沐曦科技即将推出的MXC500是对标A100/A800的算力芯片,FP32浮点性能可达15TFlops,作为对比的是A100显卡FP32 性能19.5 TFLOPS。
壁仞科技的BR100 发布时,凭借其超高的参数与性能引起了强烈的轰动。BR100系列基于7nm制程工艺打造,拥有770亿个晶体管。由壁仞科技自主原创的芯片架构开发,采用Chiplet(芯粒)、2.5D CoWoS等先进的设计、制造与封装技术,可搭配64GB HBM 2E显存,超300MB片上缓存,支持PCIe 5.0、CXL互联协议等。
阿里在2019年就推出了“含光800”,阿里曾表示,“含光800”是当时全球最强的AI芯片,性能和能效比均为*,1颗“含光800”的算力相当于10颗GPU。此外,燧原科技、天数智芯、景嘉微也都推出了各家优秀的GPU产品。
05
HPC成国际芯片龙头争夺要地
HPC 诞生于内部数据中心,拥有高速处理数据和执行复杂计算。为了做 HPC 领域的*,英伟达、AMD、英特尔在 HPC 应用领域也是进展不断。
英伟达:全面拥抱HPC
迄今为止,英伟达已推出了面向 HPC 和 AI 训练的 Volta、Ampere、Hopper 等架构,并以此为基础推出了 V100、A100、H100 等高端 GPU。其中 Hopper H100 采用台积电 4 nm 工艺,具有 800 亿个晶体管,在性能、效率上远超 Ampere A100,是英伟达专为超级计算机设计的产品。
近日英伟达还发布新一代GH200 Grace Hopper 超级芯片平台,是一款为大规模AI和高性能计算(HPC)应用量身打造的加速芯片。这款超级芯片在处理海量数据时,性能可提升高达10倍。由 72 核的 Grace CPU 和 GH100 Hopper 计算 GPU 组成。可以看到,英伟达已经做了充足的准备,全面迎接加速计算和生成式 AI 时代的到来 。
AMD:到 2025 年,AMD EPYC、AMD Instinct 能源效率提高 30 倍
AMD已经在高性能计算领域推出一系列性能*的产品,涵盖了服务器CPU、加速器,桌面CPU、移动CPU等众多领域,全方位覆盖数字经济的高算力需求。此外,充分利用小芯片(Chiplet)技术,用先进的2.5D和3D封装技术,使AMD能够灵活的进行异构计算解决方案系统级优化。
目前 AMD EPYC 在 x86 服务器 CPU 市场的份额已超过 25%;其去年发布的 Instinct 生态系统以及此前的 ROCm 生态系统正在为拥有广泛基础的 HPC 和 AI 客户提供 Exascale 级(百亿亿次级)技术,满足计算加速的数据中心工作负载日益增长的需求。此外 AMD 预计在 2023 年至 2024 年推出 3nm Zen 5 架构处理器。
此外,AMD 还宣布了一项雄心勃勃的计划,目标是到 2025 年,在加速计算节点上运行的人工智能训练和高性能计算应用中,AMD EPYC 系列处理器和 AMD Instinct 计算卡的能源效率将提高 30 倍。
AMD最新发布的Instinct MI200 系列加速器的*性能也可助力高性能计算和人工智能训练。
英特尔:HPC潜力股
作为高性能计算领域的创新引领者和推动者,英特尔近年来推出了英特尔至强处理器,英特尔至强融核处理器(Xeon Phi)、3D XPoint全新非易失性存储技术、英特尔可扩展系统框架(英特尔SSF)以及英特尔Omni-Path架构 (Intel OPA)等众多创新产品和技术。
英特尔基于Xe HPC微架构的数据中心GPU Ponte Vecchio是迄今最复杂的SoC,包含1000亿个晶体管,提供*的浮点运算和计算密度,以加速AI、HPC和高级分析工作负载。而英特尔推出的Ponte Vecchio是为Aurora超级计算机提供动力的处理器,Aurora超级计算机将会成为美国首批突破exaflop障碍的高性能计算机之一。
今年3月,英特尔官方发文表示,它们更新了高性能计算(High Performance Computing,简称 HPC)的路线图,并且宣布取消 Rialto Bridge 和 Lancaster Sound 的开发。英特尔表示 HPC Max 系列的重心将转移到 Falcon Shores XPU,该 XPU 原定于 2024 年推出,不过英特尔宣布推迟到 2025 年上线。
未来计算架构的发展趋势是CPU和GPU融合集成,从而形成互联、互补、互通的融合模式,以缩小计算和存储单元的通信成本。作为在CPU领域引领多年的英特尔,在这一趋势中也有着得天独厚的优势。英特尔GPU的愿景也逐渐清晰:在计算多元化、算力需求爆发式增长的大趋势下,英特尔GPU将成为驱动新兴行业发展的算力基石,同时也将成为英特尔自身业务增长的突破点。
06
未来,HPC与AI将加速融合
如今,以ChatGPT为代表的生成式AI风头正热,ChatGPT的上线或可被视作一次新产业革命的引爆点。而这个引爆点之所以能出现,离不开背后的HPC(高性能计算)与大数据基础设施。当下HPC与AI 正在加速融合之中。
HPC不同于AI。HPC的运算精度是双精度浮点运算,64位甚至128位的,所以加减乘除做得很快,它的应用领域主要有科学和工程计算、天气预报、核聚变模拟、飞行器设计。而AI计算机是半精度的,甚至是定点的,8位的、16位的、32位的。AI更适合进行分类、自然语言处理等工作,多应用在安防、互联网搜索推荐、智能制造等领域。
因此,HPC与AI融合,也就意味着二者的研究模式相结合,这样AI也可以通过HPC方法去做验证,在保证速度的同时,提升精确度。借助HPC基础设施,可见未来AI能得到更好的发挥,两者融合将是未来几年的主流趋势。
【本文由投资界合作伙伴微信公众号:半导体产业纵横授权发布,本平台仅提供信息存储服务。】如有任何疑问,请联系(editor@zero2ipo.com.cn)投资界处理。




