
“Sora最快今年内开放公测。”
在一场访谈中,OpenAI CTO Mira Murati亲自透露了这一消息。
短短10分钟里,Sora技术细节、进展、规划等当下最热议的问题,都有了更进一步解答:
生成20秒的720P视频只需几分钟
计算资源远超ChatGPT和DALL·E
目前正在进行正在进行红队测试
未来版本有望支持视频声效
而且还向外界传递了一层重要信息:
OpenAI在考虑发布这项技术时,抱有非常谨慎的态度。
“我们希望电影界人士和世界各地的创作者都能参与进来,与我们共同探索如何进一步推动这些行业发展。”
加上前几天,Sora的三名研发主管——Tim Brooks、William Peebles和Aditya Ramesh,也参与了一场16分钟的播客访谈。
综合两场对话,关于Sora背后的秘密,也有了更多蛛丝马迹可以探寻。
1、Sora背后还有多少秘密?
关于Sora,人们最关心也最期待的,可能就是什么时候才能上手体验了。
对此,Mira表示Sora正在进行红队测试,以确保工具的安全性,并且不会产生偏见或其他有害问题。
对于具体的时间,Mira也立下了flag——今年年内让Sora与广大用户正式见面。
此外,两场对话中谈到的其他话题,可以分为技术细节、项目规划和未来展望三个部分。
揭开更多技术细节
技术方面,三人团队表示,Sora更像是介于Dall·E这类扩散模型和GPT之间。
训练方式类似于Dall·E,但架构上更像GPT系列。
训练数据是不方便说滴(doge),大致就是公开数据和OpenAI已获授权的数据。
不过他们专门cue了一个点:通常图像、视频模型都是在一个固定尺寸上进行训练,而Sora使用了不同时长、比例和清晰度的视频。
具体方法之前的技术报告已经有了说明,就是用“Patches”来统一不同的视觉数据表现形式。
然后可以根据输入视频的大小,训练模型认识不同数量的小块。通过这种方式,模型能够更加灵活学习各种数据,同时也能生成不同分辨率和尺寸的内容。
性能方面,Mira和三人组的说法则略有不同:
三人组透露,有一次给Sora布置好任务后,出去买了杯咖啡,结果回来之后视频还没做好。
而Mira这边的回答则是,Sora生成720P分辨率、长达20秒的视频内容,只需要几分钟就能完成。
当然,具体消耗的时间,还要取决于任务复杂程度等多种因素,不能简单一概而论。
不过Mira这边表示,在正式发布之前将继续努力优化算法,以降低所需的算力。
这些问题还需解决
而针对Sora存在的不足,他们的回答也很坦诚,表示其还存在无法*处理手部的生成,渲染复杂的物理过程也存在一定难度等一系列问题。
除了这些bug型的缺陷之外,Sora不能给视频添加声音也算一个美中不足之处,对此三人组给出了这样的回应:
很难确定什么时候能有这样的功能,但这并非一个技术问题,而是目前有优先级更高的问题需要解决。目前,Sora还是更关注视频本身的生成,研究重点是提高视频的画质和帧率。所以,能够加入声音当然是更好的,但现在的当务之急,还是要把视频能力先搞上来。
而Mira对此的回答则更像是给人们吃了一颗定心丸——未来版本有望支持视频声效,增强用户体验。
而除了这些产品本身的问题之外,为Sora生成的视频加入溯源信息,以防出现造假,也是OpenAI当下的一项重要任务。
同时,负责人和Mira都表示,团队始终在收集来自各界的用户反馈,三人组还举例说有用户希望能加入提示词以外,更精细、直接的控制方式,团队将此作为了重点考虑的一个方向。
Sora,未来可期
最后,针对Sora的未来,负责人给出了很高的预期,并表示其将不仅仅在视频创作方面发挥作用。
我们的世界充满了视觉信息,其中有很多无法仅通过文本来传达。所以,虽然像GPT这样的语言模型已经对世界有了深刻的理解,但如果它们无法像人类一样“看”到视觉的世界,对世界的认识就会有所缺失。
因此,负责人对Sora及未来可能在其基础上开发的其他AI模型充满了期待——通过学习视觉信息的方式理解这个世界,在未来能够更好地帮助人类。
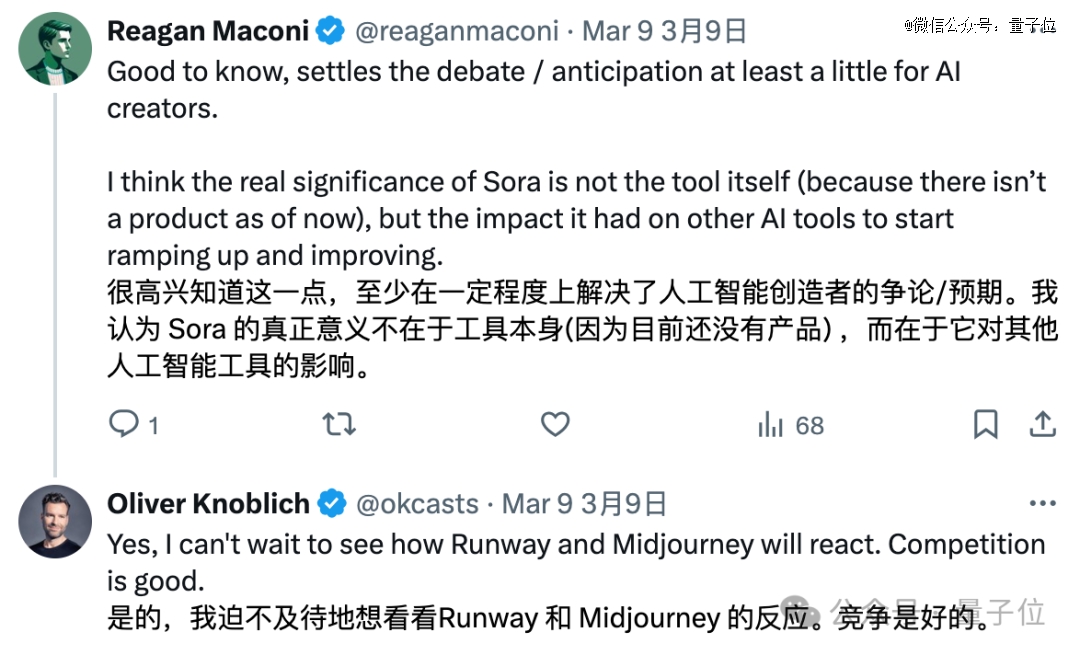
对此有网友表示,这的确是个好消息,Sora的意义不仅在于其本身,而且还会对其他AI产生影响。
另一边,已经有人在期待Runway等前任*对此的反应了。
不过,虽然团队自己说Sora在未来能够理解人类世界,但它到底能不能真的算世界模型,还存在不小的争议。2、Sora是世界模型吗?
针对这个问题,正反双方各执一词,支持者的主要理由,是认为从Sora生成的视频中能看出其对物理世界的理解。
而反方则不认同Sora是世界模型,代表人物是图灵奖得主、Meta首席AI科学家LeCun。
近期,LeCun点赞了一篇澳大利亚学者的万字长文,文章的核心观点就是认为Sora不是世界模型。

其中最核心的原因,是Sora并没有物理引擎来运行前向时间模拟,而且训练过程是端到端完成的,数据中并没有物理规律信息。
即便是抛开训练和生成过程,单从表现上看,Sora的输出也出现了违反重力、碰撞动力学等物理规律的情况。
所以,作者认为,将Sora称为世界模型是缺少充分依据的。
而人们比较关心的另一个问题,是Sora的训练过程,是否使用了虚幻引擎(Unreal Engine)5。
不过作者也没有给出确切结论,只表示这只是猜测,目前并没有确切的证据表明Sora确实使用了UE5进行训练。
而要想进一步揭开这些问题,或许要OpenAI再次自己出来公布,或者直接开源了。3、One More Thing
虽然两场访谈的确透露出了不少干货,但针对人们同样广为关心的训练数据来源问题,无论是三人团队还是Mira,说法都十分模糊——
Sora的训练过程中使用的是公开可用和已获得授权的数据源。
但对于YouTube、Instagram和Facebook上的视频是否被用作训练数据,Mira则是顾左右而言他:
我不知道,但如果这些数据是公开可用的,他们也许是(训练)数据(的一部分)……我不确定
不过,这个说法的可信度先放下不谈,即便真的如Mira所说,也有网友并不认账:
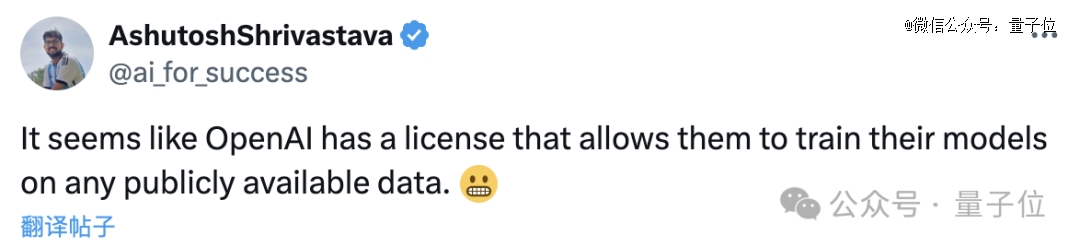
OpenAI好像觉得,只要是公开的数据就可以随便用,呵呵
【本文由投资界合作伙伴微信公众号:量子位授权发布,本平台仅提供信息存储服务。】如有任何疑问,请联系(editor@zero2ipo.com.cn)投资界处理。





