
开源社区灯塔,“真·OpenAI”——Meta抛出了目前最强的开源大模型Llama 3。
当地时间4月18日,Meta 发布两款开源Llama 3 8B与Llama 3 70B模型,供外部开发者免费使用。Llama 3的这两个版本,也将很快登陆主要的云供应商。

按照Meta的说法,Llama 3 8B和Llama 3 70B是目前同体量下,性能*的开源模型。
Llama 3 8B在某些测试集上性能比llama 2 70B还要强!
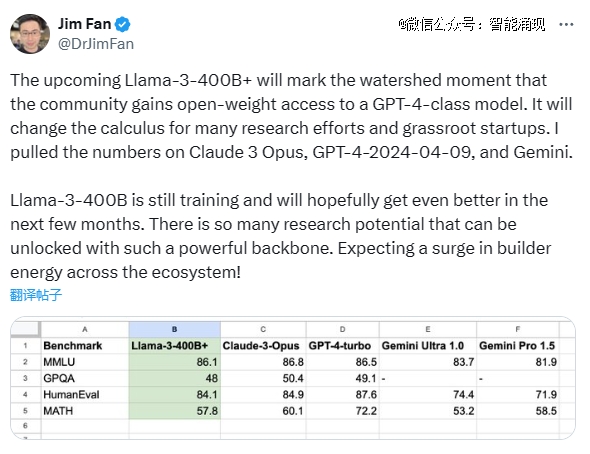
而且在未来几个月内,Meta还会推出更多的版本。英伟达高级科学家Jim Fan认为之后可能会发布的Llama 3-400B以上的版本其将成为某种“分水岭”,开源社区将能用上GPT-4级别的模型。
传奇研究员,AI开源倡导者吴恩达表示:Llama 3的发布是自己这辈子收到过的*的礼物,谢谢你Meta!

在Llama 3发布后,小扎向外媒表示,“我们的目标不是与开源模型竞争,而是要超过所有人,打造最*的人工智能。”
具体来说,Llama 3的亮点和特性概括如下:
基于超过15T token训练,大小相当于Llama 2数据集的7倍还多;
训练效率比Llama 2高3倍;
支持8K长文本,改进的tokenizer具有128K token的词汇量,可实现更好的性能;
在大量重要基准测试中均具有*进性能;
增强的推理和代码能力;
安全性有重大突破,带有Llama Guard 2、Code Shield 和 CyberSec Eval 2的新版信任和安全工具,还能够比Llama 2有更好“错误拒绝表现”。
根据Meta AI的工程师Aston Zhang透露,Llama 3的诞生始于去年夏天,团队攻克了数据集,预训练等方面的一系列难题。

他还进一步透露,Llama 3之后还会解锁新的能力——更长的上下文,支持多模态,性能更强的400B版本。
现在,感兴趣的用户已经可以在HuggingChat上体验了。
1、*了,但不多
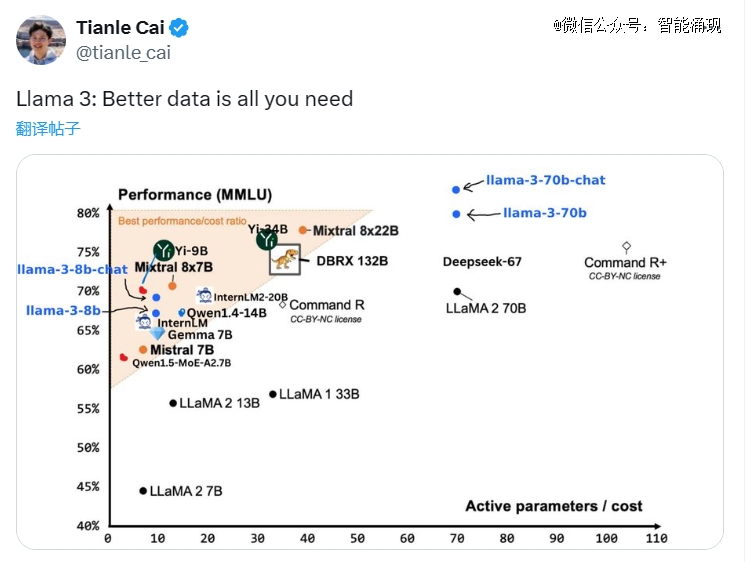
Llama 3确实优于其他开源模型,但优势不大。
Meta展示的基准测试结果包括MMLU、ARC、DROP、GPQA(生物、物理、化学相关的问题集)、HumanEval(代码生成测试)、GSM-8K(数学应用测试)、MATH(同为数学相关基准测试)、AGIEval(问题解决的测试集)以及BIG-Bench Hard(常识推理测试)。
在下图可看到,Llama 3 8B的成绩在九项测试中*同行。但Mistral 7B(2023年9月发布)和Gemma 7B已经不算最前沿的开源模型。并且在引用的一些基准测试里,Llama 3 8B的得分,还只比这两位高一点点。
在MMLU、HumanEval和GSM-8K上,Llama 3 70B击败了Gemini 1.5 Pro。尽管无法与Anthropic性能最强的模型 Claude 3 Opus媲美,但 Llama 3 70B的性能,已经优于Claude 3系列的中杯模型Sonnet。
在Meta组织的人类反馈评分中,Llama 3 70B打败了Mistral、OpenAI、Claude发布的对应产品。
这个人类反馈测试更贴近用户实际的使用体验,包括了最常见的大模型使用场景:头脑风暴、创意写作、角色扮演、复述、推理、总结等。

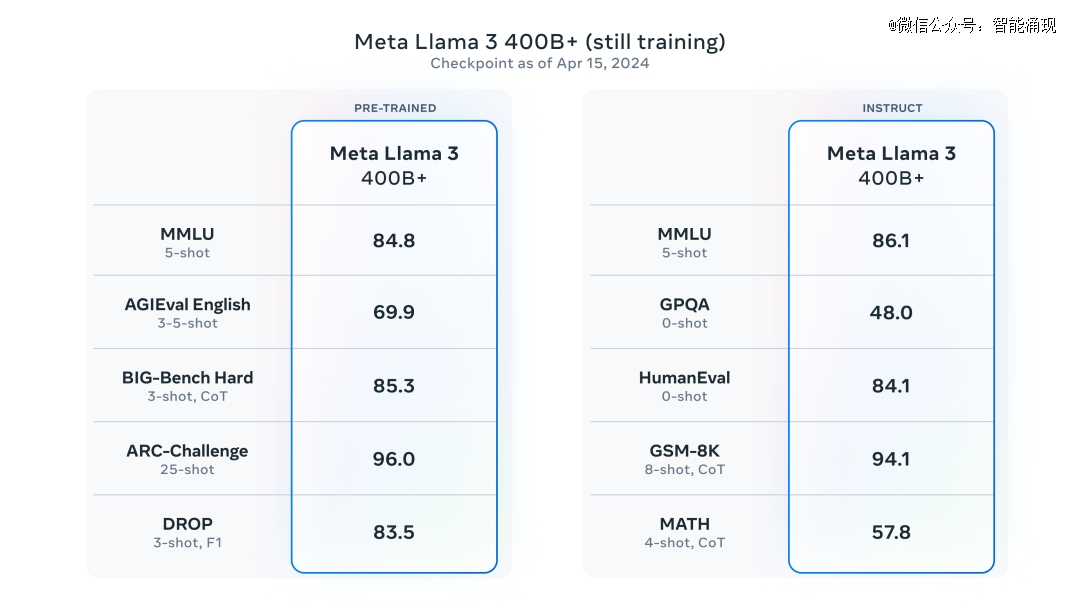
Meta不忘卖个关子,说自己目前*的模型参数,已经超过4000亿(400B),但还在训练。不过据The Verge,Meta 尚未最终决定是否开源400B的版本。
在Llama 2发布后的几个月内,开源社区雨后春笋般地,冒出了很多性能非常强大的开源模型。开源社区的竞争格局,已经有了非常大的变化。
当有人怀疑,Meta还能否继续在激烈地竞争中保持*时,Meta用Llama 3的发布,让自己重新坐回了开源社区的铁王座之上。
2、15万亿token,训练数据量大质量高
Llama 3优越的性能,离不开庞大数据集的训练——15 万亿token,几乎是Llama 2的七倍。
堆量只是*步,Meta在训练时也十分重视数据质量,用上了许多过滤手段。使用合成数据(AI生成的数据)就是一个例子。官网介绍:
我们发现前几代 Llama 非常擅长识别高质量数据,因此我们使用 Llama 2生成训练数据,提供给Llama 3的文本质量分类器,为 Llama 3 提供支持。
在接受“海量投喂”后,新版Llama在回答琐碎问题时应该能更准,在历史、STEM、工科及编程类问题时,也将显得游刃有余。
Meta还提到,Llama 3预训练数据集有超过5%的部分,来自高质量的非英语数据。加入这部分的目的在于,能更好满足各国用户、不同语言背景的使用需求。
不过,针对所用训练数据的来源,Meta依然选择打马虎眼:“收集于公开来源(publicly available sources)”。
而且两个版本的数据截止日期还略微有点不同,8B版本截止日期为2023年3月,70B版本为2023年12月。
Meta因训练数据不足而产生焦虑,4月初时,还曾被无情揭伤疤。
据纽约时报报道,2023年3月到4月期间,Meta高层天天开会,讨论如何把有版权的内容喂给模型训练——有的法子能说,比如收购Simon & Schuster出版社;有的不方便说,比如冒着吃官司的风险,在网上收集有版权的文本
而且值得注意的是,根据外媒的说法,Llama 3使用的训练数据,有很大一部分是AI合成的数据。
看来,用AI训练AI,已经是一件正在发生的事情了。
3、全面优化训练流程,训练效率比Llama 2高出3倍
Meta还分享了在训练模型的过程中,相比自己前2代模型,做出了很多流程上的优化:数据并行化、模型并行化和管道并行化。
在16000个GPU的集群上训练时,实现了每个GPU超过400 TFLOPS的计算利用率。
为了*限度地延长GPU的正常运行时间,Meta开发了一种先进的训练堆栈,可以自动执行错误检测、处理和维护。
Meta还极大地改进了硬件可靠性和静默数据损坏检测机制,并且开发了新的可扩展存储系统,以减少检查点和回滚的开销。这些改进,使总体有效培训时间超过 95%。
综合起来,这些改进使Llama 3的训练效率比Llama 2提高了约三倍。
4、最智能的免费AI助手,秒速文生图
小扎在之前采访中就已经表示过,未来Meta推出的大模型将重塑自家产品的使用体验。
这次同Llama 3一同推出的,还有基于Llama 3构建的Meta AI。
按照小扎的说法,Meta AI已经是目前最智能的免费AI助手。
总结下来,Meta AI与自家APP生态的兼容性,无疑能让使用体验大大提升——无需切换,即可在Instagram、Facebook、WhatsApp 和 Messenger 的搜索框中畅通使用Meta AI。
手机的聊天窗口中,输入问题+@Meta AI,就能得到想要的答案。“私聊”Meta AI对话也是可以的。
刷Facebook时遇到好玩的事情,突发奇想有个疑问,帖子下面点开直接问!
Meta当然没忘记PC端。登入meta.ai,无需注册登录,即可像GPT一样开启对话。当然,登录后可保存对话记录,便于未来参考。
要知道,OpenAI才刚在4月1日宣布无需注册体验ChatGPT。
文生图功能酷炫至极。由于图像生成速度大大加快,每输入几个字母,图像就会发生变化——所输即所得!
Meta AI生成图片质量高,还能在原图基础上生成GIF动图,与好友进行分享。
据The Verge, Meta AI 助手的*一个集成了 Bing 和 Google 实时搜索结果的聊天机器人——Meta可决定使用哪种搜索引擎来回答prompt提示词。
据介绍,Meta正向美国以外的十几个国家,推出英语版 Meta AI。澳大利亚、加拿大、加纳、牙买加、马拉维、新西兰、尼日利亚、巴基斯坦、新加坡、南非、乌干达、赞比亚和津巴布韦将可以使用 Meta AI。
5、可能是史上最安全的开源大模型
而针对外界关于开源大模型担忧最多的安全性问题,Meta这次看起来也是做了了充足准备。
Meta采用了一种新的系统级方法来负责任地开发和部署Llama 3。他们将Llama 3视为更广泛系统的一部分,让开发人员能够完全掌握模型的主导权。

指令微调在确保模型的安全性方面,也发挥重要作用。
Meta的指令微调模型,已经通过内部和外部进行了红队测试。Meta的红队利用人类专家和自动化方法来生成对抗性提示,试图引发有问题的响应。
他们进行了全面的测试,来评估模型在化学、生物、网络安全和其他风险领域相关的滥用风险。
除此之外,Meta还采用了业内最为先进的大模型安全技术,出生自带Llama Guard 2、Code Shield 和 CyberSec Eval 2的新版信任和安全工具,确保模型不会被轻易越狱,输出有害内容。
看来Meta已经充分吸取了Llama去年意外泄漏的教训,在模型的安全性上下的功夫不亚于对性能的追求。
未来,Meta团队将会公布Llama 3的技术报告,披露模型更多的细节。
而团队成员还表示,Meta官方还会以直播或者博客的形式,让模型开发团队直接与外界进行交流。
总之,Meta没有辜负开源社区对它的期待,继续在大模型开源之路上奋力狂奔!
【本文由投资界合作伙伴36氪授权发布,本平台仅提供信息存储服务。】如有任何疑问,请联系(editor@zero2ipo.com.cn)投资界处理。





