
不知经常往旧金山城里跑的小伙伴,有没有在路边见过这样的广告:
“按周、天或小时租用H100芯片。
3.2TB/s InfiniBand高速网络,k8s / Slurm开源系统,就是这种东西。”
下面还写了一排官网地址给你“撕”。
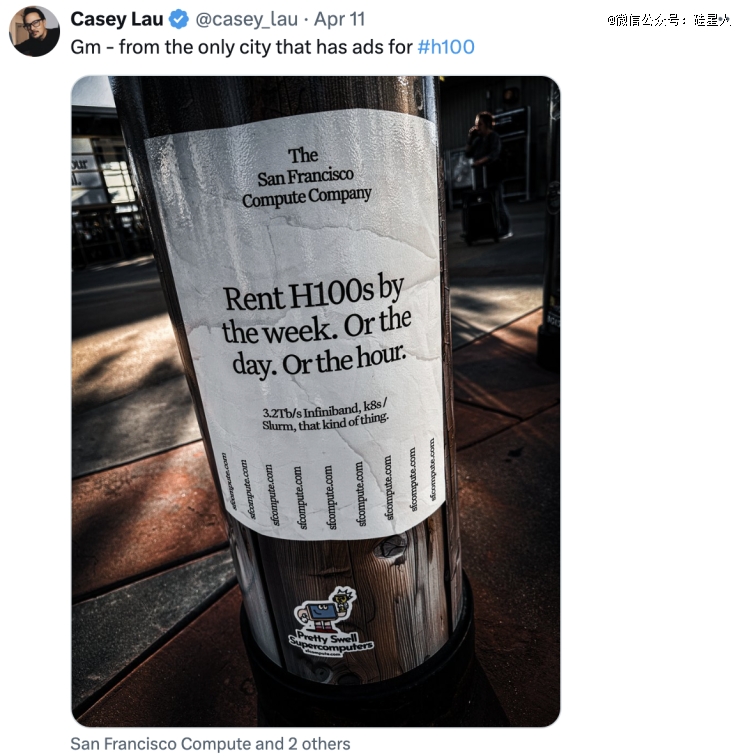
作为全世界生成式人工智能的火热据点,旧金山街道遍布的各类AI广告早已成为它的“城市特色”。可即便如此, 这个“出租算力”的概念仍然很酷,而且是把高高在上的英伟达H100变得如此接地气,在AI圈内引起了一阵小波澜。
半年多过去,这家做算力生意的初创公司「San Francisco Compute」从名不见经传的“Underdog”来到台前。上周,Sam Altman亲弟弟Jack Altman主理的Alt Capital领投其1200万美元种子轮融资,让它的估值来到约5亿人民币(7000万美元)。
AI算力市场的“Airbnb”
我们知道,能否及时获取足量计算资源可能会决定一家AI初创公司的成败。而通常只有规模*、资金最充足、关系最广的大公司才能确保获得所需算力。高性能AI芯片不仅成本高昂,还需要签订长期合同,这对资金有限、业务需求多变的中小企业构成了巨大障碍。
SF Compute就是为了解决这个难题而生。它专注于为早期公司提供经济实惠、短期灵活的超级计算资源访问权限,帮助它们更高效、更经济地开发和训练AI模型。有点类似Airbnb在住宿领域的做法:通过共享和按需租赁,让用户以较低成本获取所需资源,短时间内使用大量计算能力。
具体是通过以下两种服务模式:
1. 短期计算资源租赁
与需要签订长期合同(通常为1-3年)的传统提供商不同,SF Compute提供按周、按天、甚至按小时计费的短期算力租赁服务。同时具备可扩展的集群,让用户根据实际需求来动态调整其计算资源使用量,完全实现“GPU定制自由”。
你可以租768个H100使用一周,也可以借8个H100运行2小时。SF Compute还为 512 - 4096个GPU 的大规模预订提供有竞争力的定价。例如租赁512个H100两周只需50万美元,远低于在其它提供商那里一年1200万美元的花费。
这种以实惠价格“爆发式”访问巨大算力的灵活选项,特别适合需要高性能计算但不想承担长期财务负担的用户。包括资金有限、业务可能快速变化的AI初创公司,以及实验室或研究员需要强大算力支持的短期项目等。
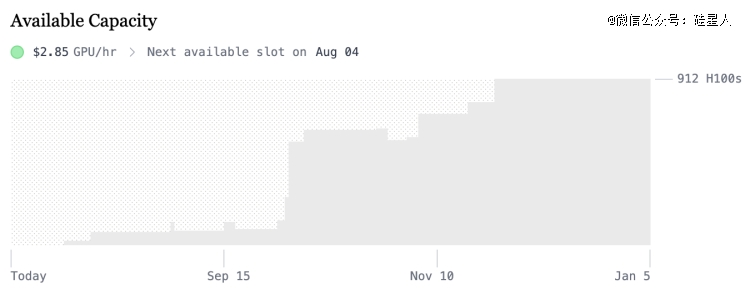
根据SF Compute官网信息(下图):当前 GPU 使用价格为2.85 美元/小时,下一个可用时间段是 8 月 4 日。从现在到明年1月5日的可用容量在逐步增加,到年底达到912个H100 GPU。
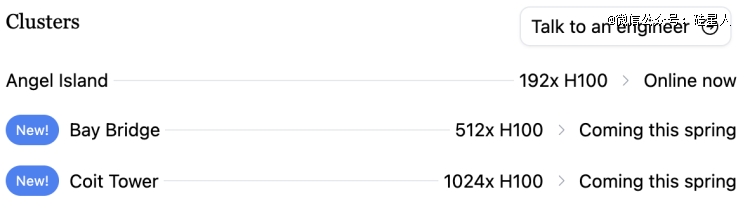
目前三个公共算力集群部署中:Angel Island 集群有192 个 H100 GPU,于去年11月上线。Bay Bridge 和 Coit Tower分别有 512 和 1024 个 H100 GPU,计划明年春季上线。
2. 计算能力交易平台
除租赁服务外,SF Compute还在开发一个计算能力交易平台,以使用户更便捷地按需买卖计算资源,进一步降低算力获取难度和成本。通过允许小型 AI 公司与大企业竞争来民主化高性能计算的访问。
据悉,公司已经获得了相当于8000个H100的资源来支持这一计划。刚筹集的1200万元资金也会投入平台建设。
坐标旧金山脑谷,16人团队里三分之二当过创始人
SF Compute总部位于硅谷旧金山,办公室就设在AI公司扎堆密集、被称为“脑谷”的Hayes Valley。2023年由Alex Gajewski(右)和Evan Conrad(左)共同创立。

Alex Gajewski任公司CEO,毕业于哥伦比亚大学数学系。在开始旧金山计算公司之前,Alex曾创立Metaphor,主导训练了一个覆盖十亿页面的大型对比模型和一个神经搜索引擎。他还在公司加速器AI Grant*批项目中发挥了重要作用。职业生涯致力于减少创建*进AI模型的障碍和促进多样化的公司生态系统。
Evan Conrad在科技行业拥有丰富的职业生涯。曾在OpenAI的ChatGPT Enterprise部门短暂工作过,担任过八个月的AI Grant董事。之前联合创立了Quirk和Moder LLC并分别工作近四年。他还担任过Segment软件工程师,有Amazon和AppDetex的实习经历。
两人创立SF Compute的渊源也很有意思。
因成为合租室友而相识后,Alex和Evan本来是打算成立一家AI音乐初创公司。为了扩展音乐生成模型并向潜在投资者展示成果,他们联系了当时的每一家GPU提供商,以寻求1个月的算力访问权限。结果被所有人告知最少购买期限是一年,费用100 万美元起步,而他们根本就拿不出100 万。
“没人愿意只卖一个月的使用权。这很好理解:如果你运营一个大型集群,*是以1到3年的合同出售并预先支付所有费用。这样风险更小,利润更高。为什么要把集群卖给 Junelark 这种几乎没有资金的两人音乐初创公司,况且他们可能在合同结束前就倒闭了?” Evan说,“不幸的是,我们就是 Junelark。我们的朋友也大多数是这种情况。”
“如果你不是那些‘神圣的少数’之一,实际上就被市场定价排除在外。没有重大资金支持,你根本没得选择。”
寻求GPU受挫的两人于是尝试联系其他同样需要计算能力的创始人,认为如果有十几家初创公司一起加入,他们就能共同负担得起一份年度合同。
没想到短短几周内,就吸引来170家AI公司签约。看到这个庞大的市场需求后,两人果断放弃了AI音乐梦想,决定成为一个专门为大规模训练任务提供超级计算资源灵活访问的GPU云供应商。
不仅是“淋过雨后方知给他人撑伞”,在算力民主化、资源共享、扶持小型实体与大企业竞争这些备受硅谷科技社区推崇的理念背后,SF Compute也正中大量AI公司创始人苦于拿不到算力推进项目的痛点。
五个月前Evan Conrad在一次演讲中表示,SF Compute每个月都在把算力卖给学术实验室、研究人员、初创公司,这是其他人永远不会重视的客户。
当时他们的运营利润约为100万美元,预计在两个新集群上线后将增加10倍,达到每年1000万美元。公司的早期客户中还包括哈佛大学和普林斯顿大学的研究实验室,以及PlayHT Inc.、Phind和Liquid AI Inc.等初创公司。

目前SF Compute在LinkedIn的关联员工为16个人。Evan在X发文透露,其中有10名员工都是前创始人。他们也正在招聘核心基础设施工程师、机器学习系统工程师和产品工程师职位(有兴趣的可以关注一下)。
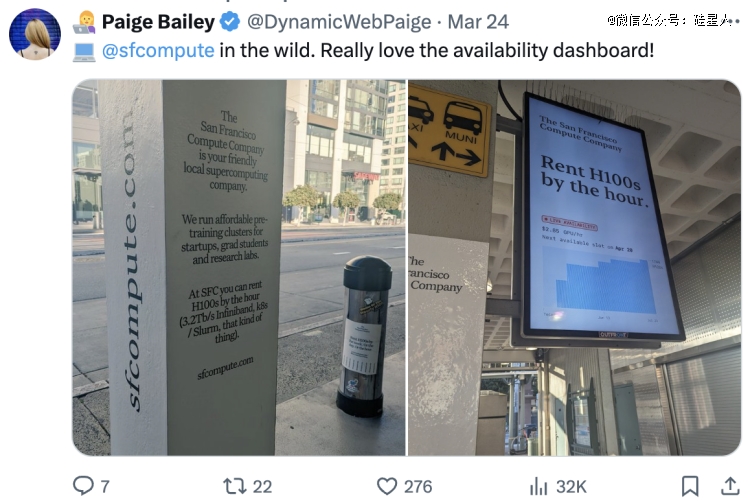
公司风格颇有《硅谷》电视剧里的感觉。员工们编程累了,就会解物理题目来“放松”。也用文章开头那种朴实无华的方式打了许多本地硬广。
再看几个,比如路边公告牌:
候车大厅:
以及下面这条,“为你的下一个H100账单立省2000万美元。”
用户Micheal Black说,“唯在旧金山有这样的sense。做广告的关键是了解你的客户。我在想,是的,我确实想在H100上省2000万!”

硅谷这片科技热土,历来盛产充满冒险精神的创业者和想创业的人们。通常现在一场前沿AI活动的观众里,一半以上都是人工智能相关公司创始人。
这些人对访问大量高性能AI计算资源有着迫切的渴求,却总被财大气粗的成熟企业挤到一边,可能手握出色的想法、技术却无法到现实世界验证和呈现。而今San Francisco Compute的出现,让双方得以互相成就。
市场竞争与未来发展
当然,SF Compute并不是*一家提供部分计算能力访问的公司,在市场中也面对几家颇为强大的同行对手。
例如Lambda Inc,最初是一家面部识别公司,后来转向为包括英特尔公司和国防部在内的*机构提供按需的GPU工作站、服务器和云计算资源。更知名些的有”英伟达小弟“CoreWeave,起初是一家加密货币挖矿公司,也转型成GPU加速云计算服务供应商,专注于支持生成式AI和其他需要高性能计算的任务。最近它完成了11亿美元融资,估值已达190亿美元。另外还有提供低成本算力租赁服务的Vast.ai 公司,和拥有全球分布GPU云及无服务器端点的RunPod公司等。
虽然竞争激烈,但SF Compute在短至小时的租赁时间和集群使用量上的灵活度、更具竞争力的价格和专注中小企业甚至个人等方面,还是拉拢了属于自己的特定客户群体。而未来即将推出的计算资源交易平台,也将成为它下一大制胜优势。
SF Compute称,接下来会把团队主要工程人员翻倍至30人,进一步增强服务能力,提高市场地位。
作为投资人,Jack Altman预计会有越来越多的用例出现:“风险投资公司和其他锁定长期GPU交易的公司都可以利用这个平台来买卖访问权。许多群体可能成为客户。”Jack Altman说,“San Francisco Compute已经展开了许多合作洽谈,我认为这是一个非常值得看好的方向。”
【本文由投资界合作伙伴微信公众号:硅星人授权发布,本平台仅提供信息存储服务。】如有任何疑问,请联系(editor@zero2ipo.com.cn)投资界处理。





