
当我们惊叹于万亿参数级别的大模型如GPT-4、文心一言、通义千问等带来的语言理解、生成能力时,AI背后隐藏的“燃料危机”正逐渐显现。数据,这个曾被认为是触手可得、取之不尽的资源,如今正成为AI发展的隐形天花板。
如果将AI比作一部高速运行的机器,算力是它的“心脏”,算法是它的“灵魂”,而数据就是它的“血液”。曾经,数据被视为“信息大爆炸时代”的自然馈赠,但随着AI模型规模的快速增长,这种“血液”正以惊人的速度被耗尽。不仅如此,低质量数据、数据偏见、行业数据孤岛等问题正在加速这一“血液枯竭”的进程。
当下,算力和算法的瓶颈逐渐被技术进步所突破,但数据的稀缺性和难以快速扩展的特性,正在为AI发展设置一道新的关卡。无论是国外的OpenAI,还是中国的百度、阿里、智谱清言等厂商,都在面临同样的挑战:AI未来的真正突破,可能不再是算力,也不再是算法,而是如何突破数据瓶颈。
01 AI在耗尽什么?
数据是AI的“燃料”,但现在,这场技术革命正面临一场无声的饥荒。
GPT-4已经榨干了互联网的“金矿”。维基百科、社交媒体、开源代码,这些看似无穷无尽的资源,如今不过是干涸的河床。国内的大模型如文心一言、通义千问,也陷入了同样的困境:数据不是不够,而是几乎被用光了。
问题不仅仅是“数量”,互联网数据看似浩瀚,实则多是低质量的“沙砾”。偏见、冗余、虚假信息充斥其中,让模型无法真正站稳在“知识”的基石上。社交媒体的喧嚣,更多是噪声而非智慧。
高质量的数据集也捉襟见肘,ImageNet、COCO,这些曾让AI从“婴儿”走向“少年”的标志性数据集,如今对万亿参数级模型来说已经无济于事。它们是AI的过去,而不是未来。
更大的讽刺在于,最有价值的数据被封锁在行业的铁门之后。医疗数据能够挽救生命,金融数据可以预测经济,但它们被隐私和安全法规紧紧锁住,成为AI触碰不到的禁果。在中国,医疗数据的潜在价值高达数万亿,却依然沉睡在法律的禁区中。
即使打开铁门,问题也远未解决。低质量数据是毒药,而不是养料。OpenAI不得不投入巨资清洗数据,但代价高昂;DeepMind尝试依赖结构化数据,却发现难以大规模扩展。国内企业如蚂蚁集团开发智能清洗技术,但只能在细枝末节上做微调,难以改变整体格局。
数据标注,也是一场徒劳的赛跑。人工标注成本高昂,效率低下,而AI辅助标注依然难以替代人类的专业判断。更重要的是,行业数据标注需要高度专业化知识,这让扩展标注能力成为一场无解的挑战。
最严重的,是数据短缺对模型发展逻辑的限制。参数越多,需求越高;而数据越少,回报越低。大模型就像拥有饥饿大脑的巨人,却没有足够的粮食来养活它。
AI的血液正在流失,而大模型的未来,可能就在这条路上逐渐枯竭。
数据短缺,不只是一个技术问题,而是正在瓦解大模型扩展逻辑的系统性危机。大模型越大,需求越高,而可用数据的增长却远远跟不上这种膨胀。这场不对称的对抗,正在暴露AI发展的脆弱底牌。
没有数据,规模再大的模型也不过是一个空壳。
大模型的本质,是从多样化的数据中提取规律、生成知识。如果数据量不足,或者缺乏深度和多样性,模型便会陷入过拟合的泥沼,变得只能重复历史,而无法创新预测。更重要的是,高质量行业数据的匮乏,让许多模型始终无法突破专业化场景的壁垒。
02 如何重新定义AI的数据资源?
数据瓶颈并非不可逾越,但这需要我们重新审视数据的获取、流通与利用方式。当前的关键在于激活沉睡的数据、利用技术突破限制,并探索新的数据来源。数据的稀缺,正在倒逼AI行业重新定义它的资源逻辑。
激活“沉睡的数据”:共享、计算与交易
在全球范围内,高价值数据被深锁于行业孤岛之中。医疗记录、金融交易、工业生产线,这些蕴藏着巨大潜力的资源却因为隐私、合规和利益问题而停滞不前。破解这种僵局的关键,是通过技术与机制激活沉睡的数据。
隐私计算、密态计算、机密计算等新技术,为这种激活提供了可能。以联邦学习为代表的技术,使得数据可以“可用不可见”,即数据本身不必离开所有者的服务器,就能被算法训练所利用。腾讯安全的开源联邦学习框架已经在多个医疗试点中实现了“数据不出医院”的安全协作,而蚂蚁密算科技公司进一步通过密态计算,在金融场景中推动跨机构的数据协作。这些技术的背后,是对隐私与数据价值的双重保护。
与此同时,数据交易也开始成为一种可能的解决方案。深圳数据交易所正在尝试通过结合区块链技术,实现对数据使用路径的追踪和透明化,以降低企业共享数据的阻力。这些平台的目标不仅是释放数据价值,更是建立一种可信任的流通机制。医疗和保险领域可能是最早受益的行业,有预测表明,仅隐私计算在这些领域的应用,就可能释放数万亿元的市场潜力。
自动生成与数据增强
当真实数据匮乏时,AI自己生成数据成为一种有力的补充。OpenAI和DeepMind已经在数据增强技术上投入巨大,比如通过生成对抗网络(GANs)创造逼真的模拟数据,以补充训练数据的多样性。
国内企业同样在发力。例如,光轮智能公司专注于为自动驾驶和具身智能领域提供合成数据解决方案,该公司通过生成式AI与仿真技术相结合,尝试构建3D高物理真实度的数据场景,以解决传统数据采集成本高、效率低的问题;
群核科技旗下的Coohom Cloud(群核云),是合成数据服务平台的代表。该平台可以将效率提升10倍,基于GPU集群并发渲染优势,每日可合成20万组数据,大大降低训练成本。
然而,生成数据并不是*的。没有真实世界的验证,这些数据可能加剧模型偏差。比如,基于模型生成的模拟病患数据,若未经过足够的真实性校验,可能在医疗决策中带来误导性风险。
生成数据是短期止渴,但绝不是长久之计。自动生成只能在真实数据的基础上作为补充,而不能取代真实世界的复杂性。
小数据与精细标注
与其追求海量的“大数据”,不如精炼“小数据”的质量。
少量高质量数据,往往能产生比海量数据更高的边际效益。一个拥有500例高质量标注的医疗数据集,可能比拥有数百万未标注的病患记录更有价值。这不仅让模型更精准,也能让它们在特定场景中具备更强的解释性和适用性。
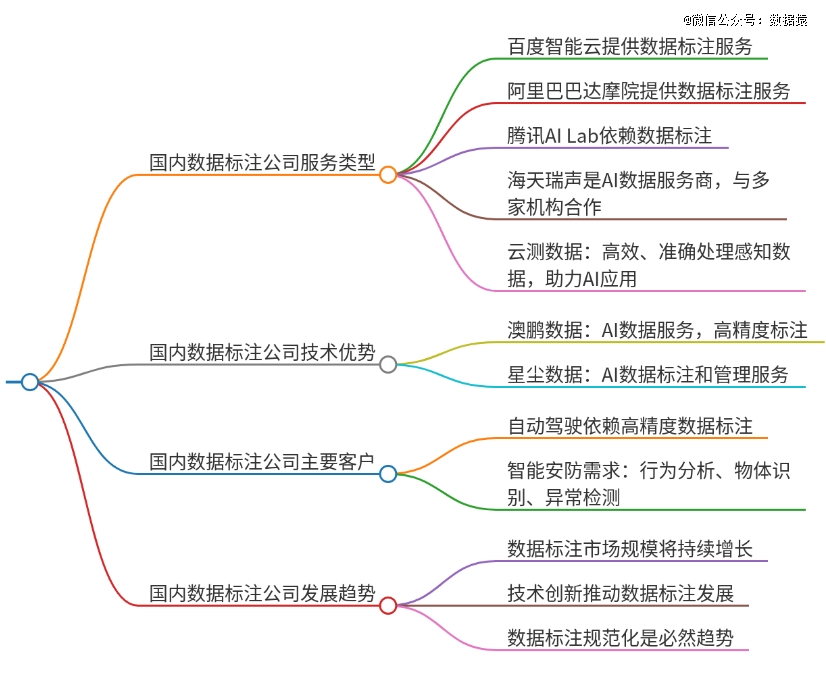
国内有一大批专注于数据标注的公司,例如:
海天瑞声,提供多语言、跨领域、跨模态的数据服务,成功交付数千个定制项目。近期,其将智能化标注与大模型开发结合,提高数据标注的效率与精准度;
云测数据提供处理大规模感知数据的能力,标注准确度高达99.99%,综合效率提升200%。云测数据还推出了面向垂直行业的大模型数据解决方案,帮助实现行业数据标注;
澳鹏数据专注于AI数据服务,提供高精度数据标注平台和大模型智能开发平台,其自主研发的预标注通用模型和交互式算法在数据标注任务中能产生显著效率提升;
星尘数据提供AI数据标注和数据管理服务,平台可以处理100多种主流采集和标注场景。
数据挖掘的新方向:多模态与非传统数据源
突破传统数据来源的限制,多模态数据和非传统数据源可能是AI的未来。
多模态数据的融合正在重新定义AI的边界,文本、图像、音频、视频的数据结合,可以为模型提供更全面的理解能力。例如,自动驾驶技术正在将视觉、雷达和地理数据结合,构建多维度的场景感知模型。这种结合不仅提升了模型的能力,也让AI能处理更复杂的任务。
物联网和边缘设备的数据流,则是另一个值得关注的领域。传感器生成的实时数据、智能家居设备的用户交互记录,这些动态数据具有鲜活的特性,可以弥补传统静态数据的不足。分布式数据采集也为数据隐私保护带来了新的可能,数据不需要集中化存储,就可以通过边缘计算实现即时的价值提取。
这些新的方向不仅为AI提供了新的燃料,也为数据稀缺问题提供了突破路径。
数据的稀缺正在逼迫AI行业走向创新的边缘,无论是激活沉睡数据、依赖生成增强,还是探索多模态和实时数据,解决数据瓶颈的未来注定不会是单一路径。真正的破局之路,在于技术、数据和场景的深度融合,重新定义AI对数据的依赖逻辑。
03 后数据时代,强化学习崛起
数据瓶颈正在倒逼AI转变路径,而强化学习(Reinforcement Learning, RL)正成为这个后数据时代的重要突破方向。不同于传统依赖海量数据的深度学习,强化学习尝试通过逻辑推导和交互式学习,让AI从“模仿历史”转向“自主探索”,实现从经验主义到逻辑主义的飞跃。
强化学习的核心不再是被动吸收,而是主动发现。它通过试验与反馈,逐步优化自身策略。这意味着,AI可以在数据不足的情况下,通过与环境的互动积累知识,而不再完全依赖预先标注的大量数据。
AlphaGo的成功,是强化学习潜力的*证明。在没有现成数据的复杂棋局中,AlphaGo利用强化学习结合蒙特卡罗树搜索,自主训练数百万局棋局,最终超越了人类*棋手。这种能力的本质在于它跳出了“记住什么”的框架,而是学会了“为什么”和“如何”。
在中国,类似的尝试也正在崭露头角。智谱清言等企业正在探索强化学习在数学推理和代码生成中的应用,通过与任务环境的动态交互,让模型学习更深层次的逻辑规律。例如,在复杂数学证明问题中,强化学习可通过反复试探与验证,逐步构建出严谨的解题路径。这种能力,超越了传统数据驱动方法的局限,为AI注入了新的逻辑力量。
强化学习不仅是一种技术,更是一种范式转变的信号。它表明,AI的未来可能不再局限于简单的数据驱动,而是更多地依赖逻辑驱动。这种转变,不仅为数据瓶颈提供了解决方案,也为AI技术的边界拓展开辟了新路径。
逻辑驱动能够显著降低对数据量的依赖,在数据稀缺的情况下,模型可以通过强化学习与知识的结合,自主生成逻辑链条,而不是依赖直接的数据映射。比如,阿里达摩院正在利用强化学习优化搜索排序算法,甚至尝试在场景不足的情况下,通过逻辑模拟生成高质量的策略。
这种范式转变对AI产业具有深远意义,它不仅缓解了数据稀缺的困局,还为AI的通用性与创造力打开了一扇门。强化学习让AI从“记住过去”转向“构建未来”,这种能力的本质,是让机器真正具备了逻辑思考的雏形。
强化学习,被誉为AI从“模仿”走向“探索”的关键武器。然而,它的光环之下,却潜藏着深刻的矛盾与隐忧。
强化学习消耗资源的胃口,令人咋舌。AlphaGo的成功背后,是数千台TPU支撑的庞大算力,以及数百万次的对弈博弈。这样的成功,更多是豪赌式的胜利,而非普适化的解决方案。对于大多数企业来说,这样的成本无异于高耸的门槛,将强化学习锁在实验室里,难以普及。
高昂的资源需求只是表象,更深层次的问题在于目标的模糊性。强化学习依赖奖励函数,但设计一个“正确”的奖励函数,比完成任务本身更难。稍有不慎,模型就会追求所谓“*解”的捷径,甚至出现荒唐的行为——在游戏AI中,这种“奖励黑客”现象屡见不鲜,模型宁愿重复得分动作,也不愿真正优化策略。
更复杂的是,强化学习的成功需要一个高度仿真的训练环境。然而,现实世界的复杂性远非模拟环境能够复刻。自动驾驶的仿真系统,可以生成道路场景,却无法预测真实街道上的突发状况;医疗AI的强化学习系统,可能在仿真患者上表现优异,却在真实病人面前失去作用。训练环境的局限,让强化学习成为高楼上的试验,而非地面上的实践。
相比监督学习,强化学习就像是在黑暗中摸索道路,而非沿着清晰的路径前行。在数据匮乏或环境动态变化的场景中,这种低效表现尤为明显。
而当环境变化时,强化学习的脆弱性暴露无遗。一个在单一工厂训练的机器人,在面对略有不同的工作条件时,可能完全丧失能力。这种依赖特定场景的设计,让强化学习难以跨场景应用,无法满足现实中的动态需求。
更大的隐患在于不可控性,强化学习的探索性让它在一些场景中显得危险。在自动驾驶中,它可能为了试探更高效的路径而冒险;在金融系统中,它可能为了追求回报*化而采取过度风险。这种不可预测的行为,让强化学习在关键场景中的使用始终伴随着巨大争议。
强化学习是AI的一次豪赌,也是一次对未来边界的冒险。它的潜力不容忽视,但它的代价同样惊人。技术的光芒,掩盖不了它的阴影;而如何驾驭这种力量,或许将决定它能走多远。
04 人类才是AI*的数据源
数据的尽头,不是终点,而是入口。
人与AI的交互,正在创造一种全新的数据形态。这些数据不再是传统意义上的“存量资源”,而是实时生成、动态迭代的“活数据”。它们承载着人类的创造力、意图与反馈,成为AI从停滞走向进化的关键燃料。
当用户与ChatGPT、文心一言、通义千问进行每一次对话时,都在无形中推动着AI的成长。用户的输入不仅是问题,更是数据;AI的输出不仅是答案,更是学习的素材。这种交互,不是单向的信息流动,而是一个不断循环的知识生成过程。
这是AI学习的全新范式,就像孩子从与大人的互动中习得语言、理解规则。数据不再是冷冰冰的标注样本,而是鲜活的、充满情感和意图的动态信息。每一次纠错、每一次补充、每一次质疑,都是AI完善自我的一块拼图。
这种变化已经在实践中显现,OpenAI通过用户反馈优化ChatGPT的回答质量,创建了一个用户参与模型迭代的闭环系统。用户的每一次点赞或批评,都成为模型升级的推动力。在中国,Kimi等聊天机器人通过实时学习用户的语境与情感偏好,让对话更加贴近个性化需求。这些互动数据,正在让AI“学会倾听”,而非简单重复。
这不仅是数据量的扩展,更是数据价值的跃迁。传统静态数据只能记录过去,而交互数据承载着当下的人类智慧。这种鲜活的“养料”,为AI提供了超越历史的能力——学习现在,适应未来。
这种情况下,人与AI的关系正在发生质变。我们不再是AI的“使用者”,而是它的“共生伙伴”。
交互数据的意义在于,它让AI的学习不再局限于海量历史数据,而转向实时反馈的动态优化。每一次人类与AI的互动,都是一次协同进化的过程。AI从人类那里获得新知识,人类从AI那里获取新工具。这种双向循环,将“人工智能”提升为“协作智能”。
在专业领域,医生可以通过反复纠正AI的诊断结果,让其逐步优化病情判断的逻辑;法律工作者可以通过反馈案例分析,让AI模型更加精准地适配司法场景。每一次微小的调整,都在塑造一个更加懂得人类需求的智能体。
互动数据的本质,是让AI“变得更像人”。它不再是冷冰冰的算法,而是一个能够感知、响应和适应的动态存在。正如人类通过社交和沟通塑造文明,AI也将在与人类的互动中构建属于自己的智慧蓝图。
数据的尽头,正是智能的起点。人与AI的每一次交互,都是一次智慧的交换与共生。未来的AI,不再是静态的工具,而是动态的伙伴;不再是历史的模仿者,而是当下的理解者,甚至是未来的创造者。交互数据,将为AI打开一扇进化的大门。
【本文由投资界合作伙伴微信公众号:数据猿授权发布,本平台仅提供信息存储服务。】如有任何疑问,请联系(editor@zero2ipo.com.cn)投资界处理。





