
AI领域的Killer App(杀手级应用)出现了。
国产DeepSeek-R1模型发布不到一周,就让发布不到12天的DeepSeek App冲到了苹果APP store国区和美区免费总榜的*名。
DeepSeek也引爆了海内外的社交网站,相比DeepSeek-R1刚发布时的大量技术分析和圈内讨论,这次更多是用户的实际使用体验——DeepSeek破圈了。
游戏科学创始人、CEO,《黑神话:悟空》制作人冯骥直呼:“DeepSeek,可能是个国运级别的科技成果。”
 图片来源:冯骥 微博账号
图片来源:冯骥 微博账号
微软CEO萨提亚·纳德拉(Satya Nadella)在X上发帖称:“随着人工智能越来越高效,越来越容易获得,我们将看到它的使用率急剧上升,成为我们用之不尽的商品。”而网友则直接给他留言:“这要归功于DeepSeek。”
 图片来源:Satya Nadella X账号
图片来源:Satya Nadella X账号
我们跟很多人聊过Killer App,也设想过Killer App产生的条件和场景,从*性原理来说,Killer App的出现离不开模型能力的爆发。
但模型能力爆发后,如果普通人用不到也很难称之为Killer App,比如需要付费才可使用接入了OpenAI o1模型的ChatGPT。DeepSeek-R1对标的就是OpenAI o1,而DeepSeek-R1开源、免费。
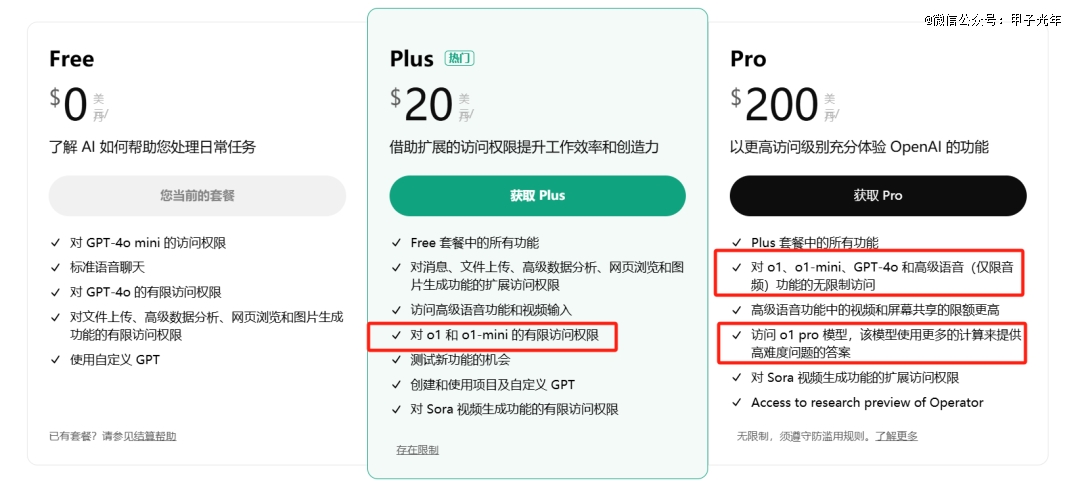 ChatGPT收费机制,图片来源:OpenAI
ChatGPT收费机制,图片来源:OpenAI
DeepSeek的爆火告诉所有人,一个会思考、够聪明、易使用且免费的AI应用就是Killer App。
在甲辰龙年的末尾,DeepSeek给AI行业添上了画龙点睛的一笔。
但英伟达CEO黄仁勋的年怕是过不好了,截至美东时间1月27日上午11点,英伟达股票一度下挫超过13%,市值蒸发约4650亿美元,创了美股市值蒸发纪录。

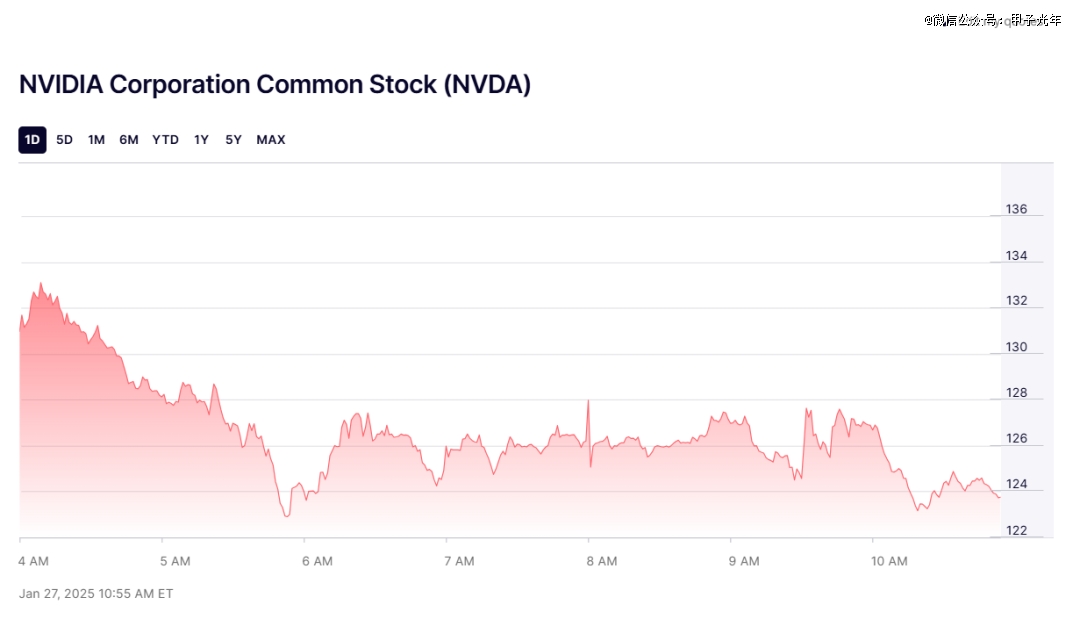 英伟达股票走势,图片来源:Nasdaq
英伟达股票走势,图片来源:Nasdaq
DeepSeek的技术特点「甲子光年」在一文中有过分析。其实在性能和开源之外,DeepSeek更让硅谷震惊的,是其R1模型通过重新设计训练流程,在保持高准确性的同时显著降低了内存占用和计算开销,仅用了少量的低端GPU(以A100为主)就实现了高端GPU(以H100为代表)才有的性能,这为原来以算力为核心逻辑驱动的大模型行业开辟了新的道路。
硅谷科技圈反应过来了,X上不少网友惊呼:DeepSeek是在戳美股泡沫啊,是在革英伟达的命啊!
一位名为Kakashiii网友发表暴论:“英伟达的一切都将开始瓦解。”目前,该帖文阅读量已超过130万次。
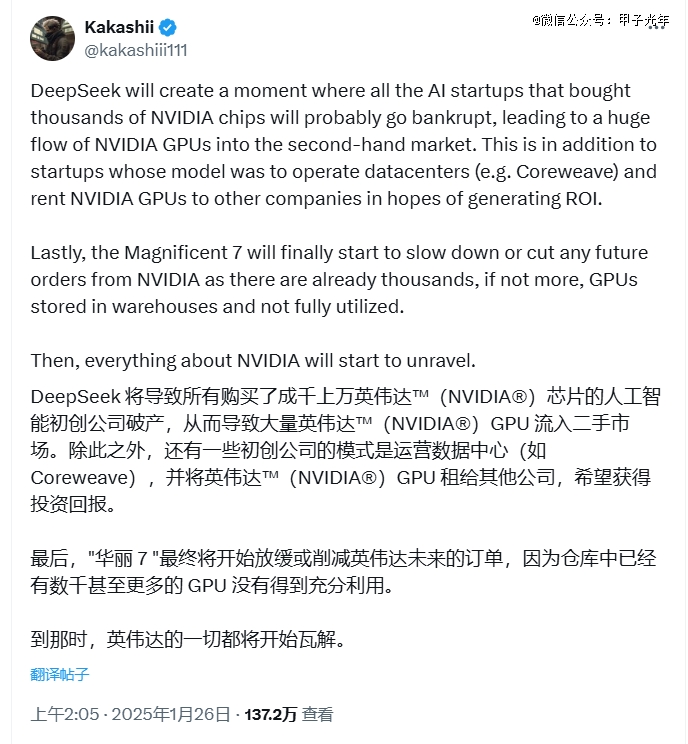 备注:Magnificent 7指的是Apple、Amazon、Microsoft、Alphabet、Meta、Tesla、NVIDIA这七大巨头,图片来源:@kakashiii111 X账号
备注:Magnificent 7指的是Apple、Amazon、Microsoft、Alphabet、Meta、Tesla、NVIDIA这七大巨头,图片来源:@kakashiii111 X账号
一旦大模型企业不再囤卡,不再搞算力的军备竞赛,英伟达的“壁垒”还会牢固吗?
1.进击的DeepSeek

kakashiii的话并不是危言耸听。
一直以来,Scaling Law(规模法则)都是大模型发展的核心定律,大厂之间算力的军备竞赛也从未停止。微软、谷歌、Meta、亚马逊等大厂分别拥有几十到上百万块H100,马斯克也多次表示算力决定生死,为旗下的xAI搭建了10万卡的训练集群。
但是DeepSeek展现了“神秘的东方力量”,其在最近的一个月内接连发布了DeepSeek-V3基座模型和DeepSeek-R1系列推理模型。
其中,DeepSeek-V3仅用2048块英伟达H800 GPU和557.6万美元的成本,便完成了6710亿参数模型的训练,而同等规模的GPT-4训练成本高达10亿美元;
DeepSeek-R1则通过重新设计训练流程、以“少量SFT数据+多轮强化学习”的办法,在提高了模型准确性的同时,也显著降低了内存占用和计算开销——百万输入 tokens 1 元(缓存命中)/ 4 元(缓存未命中),每百万输出tokens 16元,大约是 OpenAI o1运行成本的三十分之一。
可以说,算法结构的优化,让DeepSeek实现了完全的“降本增效”,直接对AI行业“堆砌算力”的既有模式发起了冲击。
「甲子光年」分析,这一技术路径的革新将带来两大影响。
AI初创企业生存模式将会转变。一些依赖高价GPU集群的AI企业可能因成本劣势破产,导致二手市场GPU供给激增,中小AI企业将会更倾向去购买更便宜的低端GPU。
硬件需求也将迎来结构性转移。从去年开始,以训练为主导的算力需求就在向推理侧转移,而今后,这种趋势还将继续,大量中小AI企业将不再训练基座模型,转而投向DeepSeek这样的开源模型的怀抱。英伟达在训练市场的地位也将面临价值重估。
2.跃跃欲试的AMD
DeepSeek的技术突破意外成为AMD挑战英伟达的“杠杆”。
1月25日,AMD宣布在其Instinct MI300X GPU上集成了全新的DeepSeek-V3模型,并与SGLang集成。这意味着AMD将联合DeepSeek共建ROCm开源框架,通过优化推理性能和英伟达争夺市场份额。
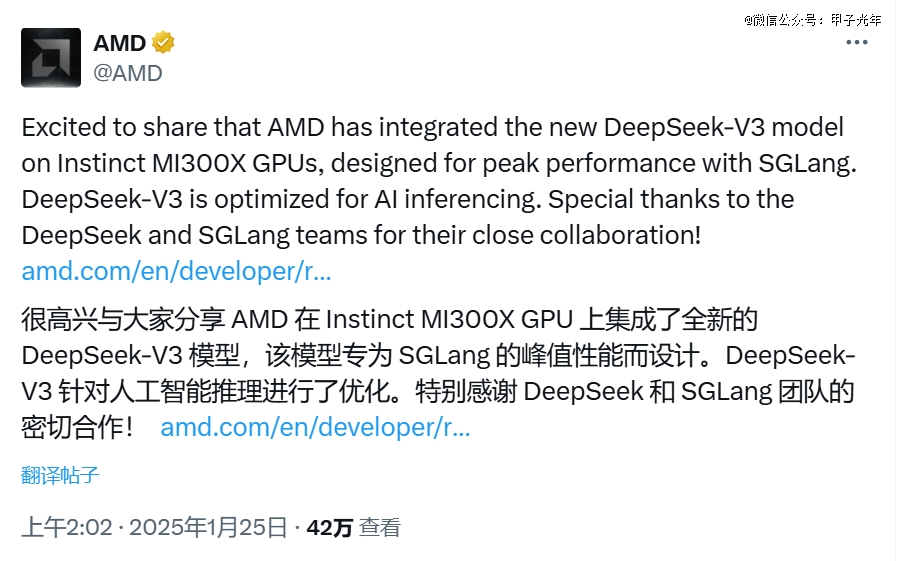 图片来源:AMD X账号
图片来源:AMD X账号
ROCm(Radeon Open Compute Platform)是AMD开发的一个开源软件平台,旨在为高性能计算(HPC)、人工智能(AI)和机器学习(ML)提供支持。它允许开发者在AMD的GPU上运行并行计算任务,类似于NVIDIA的CUDA平台。
此前,美国初创云基础设施企业TensorWave就与AMD的合作,通过利用AMD的硬件和ROCm软件平台,为AI用户提供更为便捷和高效的计算解决方案。
TensorWave联合创始人兼CEO达里克·霍顿(Darrick Horton)去年10月告诉科技媒体TechCrunch,AMD MI300X的价格要比英伟达H100便宜得多,而且基准测试显示,MI300X在运行(但不训练)AI模型时性能超越了H100,特别是在Llama 2这样的文本生成模型上。
就在AMD宣布在其Instinct MI300X GPU上集成了全新的DeepSeek-V3模型后,TensorWave官方X账号就转发了AMD人工智能和嵌入式营销负责人布莱恩·马登(Bryan Madden)的评论“如果您想访问MI300X集群,请与我们的朋友TensorWave联系”。
DeepSeek的出现,进一步削弱了硬件绑定效应,再加上DeepSeek以MIT协议开源模型权重,允许开发者自由修改,昇腾、寒武纪、摩尔线程等其他芯片厂商也将有机会将DeepSeek集成到自己的平台中,这些都对英伟达CUDA生态造成了潜在威胁。
更值得一提的是,DeepSeek采取的开源策略正在加速生态分化。通过发布基于Qwen、Llama开源模型的六个蒸馏“小模型”,DeepSeek支持在非CUDA的环境中进行模型微调;HuggingFace还发起了Open-R1项目,进一步推动了技术扩散。
 图片来源:HuggingFace
图片来源:HuggingFace
3.危与机并存的英伟达
Kakashiii发表的“英伟达的一切都将开始瓦解”的观点也遭到了不少人的质疑。
亚马逊云科技零售和消费类电子产品生成式人工智能主管迈克尔·康纳(Michael Connor)就评论道:“强大的显卡在训练和推理中都是必需的,即使使用 DeepSeek。”
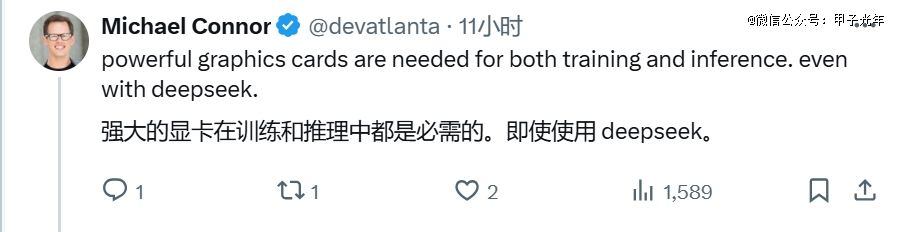 图片来源:Michael Connor X账号
图片来源:Michael Connor X账号
一直比较看好英伟达的花旗分析师阿提夫·马利克(Atif Malik)认为:“虽然 DeepSeek的成就可能是开创性的,但我们质疑的是,如果没有使用先进的GPU对其进行微调或通过蒸馏技术构建最终模型所基于的底层LLMs,DeepSeek的成就就不可能实现。”
马利克同时分析,虽然美国公司在*进AI模型方面的主导地位可能会受到挑战,但美国获得更先进芯片的机会是一个优势,因此他预计*的AI企业不会放弃更先进的GPU。
“因为这些GPU在规模上能提供更具吸引力的$/TFLOPs(一个衡量计算性能性价比的指标) 。”马利克说,“我们认为,星际之门(Stargate)等最近宣布的AI资本支出就是对先进芯片需求的回应。”
Panoptes Group前创始人、人工智能研究员、现牛津大学在读博士JundeWu就表示,很多人担心DeepSeek的低成本训练会冲击显卡市场,但他认为是利好。
他的观点之一是,很多人认为模仿DeepSeek就不需要那么多卡了,但其实DeepSeek-R1的低成本训练方法也是可以Scaling的。在DeepSeek出来之前,其他大模型用PRM(Process Reward Model)的时候,由于需要额外的卡训练PRM模型来监督推理过程,已经观察到Scaling Law失效、边际效应递减了,但是DeepSeek的出现证明了多一张卡、性能就成正比提升,这对显卡市场显然是一种利好。
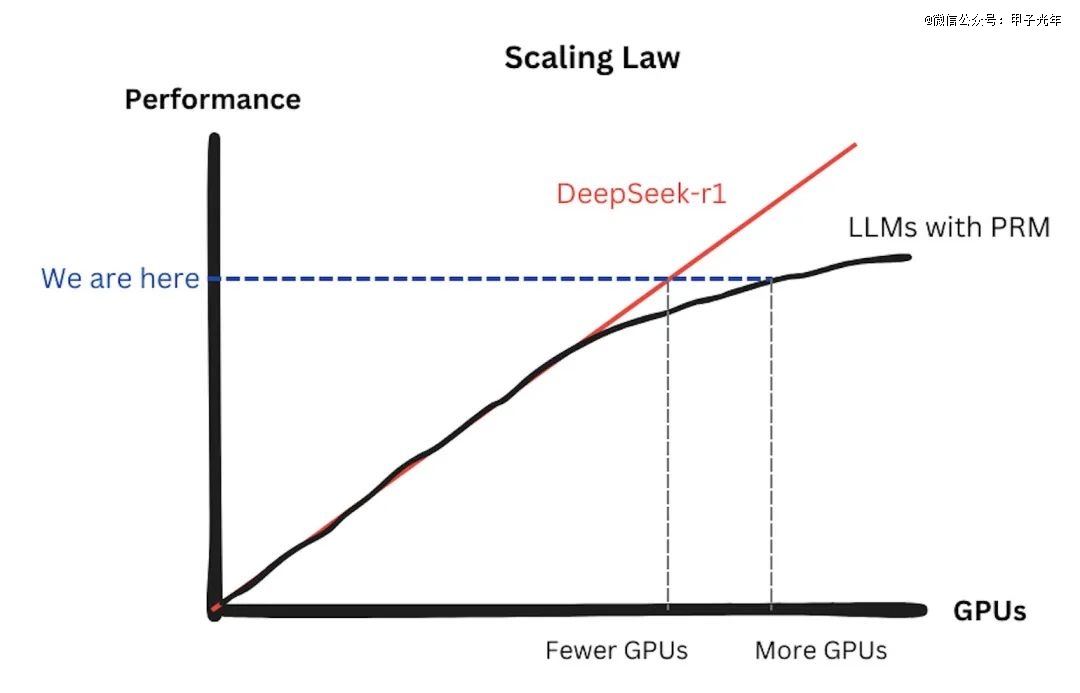 图片来源:JundeWu X账号
图片来源:JundeWu X账号
他的观点之二是,很多人认为DeepSeek做的是推理,但其实DeepSeek-R1是通过后训练,来训练模型有更强的推理能力,这种训练和预训练对显卡的需求没有本质区别。
因此,JundeWu认为,未来对显卡市场和Scaling Law*的威胁不是模型,而是数据。
还有业内人士分析,虽然训练消耗的算力较少,但是由于智能的持续升级和相应的用户需求上升,推理模型也会需要更多的算力;另外,DeepSeek的技术将导致模型能力走向分化,只有那些拥有高端GPU的人才有能力创建更复杂的模型。
除了社交网络上的讨论,在更为私密和专业的小圈子里,对于此次DeepSeek-R1的爆红和其对英伟达生态的影响的讨论则更为理性。
「甲子光年」获得的一份来自“拾象”的《DeepSeek-R1闭门学习讨论》文件纪要中,就有参会者表示,DeepSeek-R1只是站在巨人的肩膀上取得的成功,但探索大模型最前沿的技术需要的时间和人力成本还要高很多,R1的出现并不代表以后的训练成本会同时降低。
「甲子光年」分析,短期内英伟达仍握有三大优势:
高端芯片的统治力:预计2025年英伟达从Blackwell架构产品线获得的收入有可能会超过市场的预期,超过Hopper架构创造的记录,最多可达到2100亿美元的水平,而且大型云厂商的订单已覆盖未来数年产能。
CUDA生态壁垒:90%的AI开发者依赖CUDA平台,迁移成本极高。
供应链控制:台积电CoWoS(一种先进的半导体封装技术)产能优先分配英伟达,2025年预计英伟达占据CoWoS总需求的63%,表明其在采用CoWoS技术方面的领导地位。
DeepSeek掀起的AI算力革命,并不是要替代英伟达,而是迫使行业重新思考算力投入的性价比。
模型进化带来的算力革命,这其中有着太多不确定,但*确定的是:AI算力的“军备竞赛”逻辑,正在被中国公司的算法创新改写。
【本文由投资界合作伙伴微信公众号:甲子光年授权发布,本平台仅提供信息存储服务。】如有任何疑问,请联系(editor@zero2ipo.com.cn)投资界处理。




