 旗下微信矩阵:
旗下微信矩阵:

近日,记忆张量联合商汤大装置宣布,在国产 GPGPU 上率先跑通业内*以「记忆—计算—调度」一体化为核心的 PD 分离商用推理集群。相比传统仅依赖硬件隔离的方案,本次落地将 PD 分离与记忆张量旗下核心产品 MemOS(以下简称 MemOS)的激活记忆体系深度耦合,使 Prefill 批量化可调度、Decode 前台低抖动成为可能。
集群在真实 C 端负载下实现单卡并发效率提升 20%、吞吐提升 75%,综合推理性价比达到同代 NVIDIAA100 的 150%。这一成果标志着国产算力体系在大模型商业化路径上首次具备「体系级」竞争力,为高性能模型的大规模落地打开了全新的降本增效空间。

MemOS与 PD 分离深度耦合,打破性能上线
过去一年中,「PD 分离」几乎成了大模型推理优化里最热的技术关键词之一,但一个被反复忽略的现实是:如果只在算力层面做 PD 分离,而不去重构上层业务路径,那么它能带来的收益其实是有天然上限的。
随着 DeepSeek-R1 等高性能模型从 B 端试水走向 C 端大规模落地,「记忆」已经成为 C 端产品体验与成本结构的核心变量。只有当 PD 分离与记忆结构深度耦合,重构「记忆—计算—调度」整体体系,它才有机会真正超越传统意义上的性能上限。
MemOS 作为业内*一个以记忆为中心,覆盖从底层推理、到记忆模型,再到应用工程进行系统设计的记忆基础设施,它将大模型的认知结构划分为三类记忆:参数记忆、激活记忆、明文记忆。这三类记忆形成了一条跨时间尺度的调度链路,可以进行精细地决策:哪些计算应该前移到 Prefill,哪些必须留在 Decode,以及任务的保留、降级或淘汰等。
显然,MemOS 更适合和 PD 分离进行结合——它拥有一整套可以「决定如何用这条通道」的调度逻辑,从而把 PD 分离原本有限的收益空间尽可能压榨到*。
正因此,本次记忆张量与商汤大装置在某国产 GPGPU 上的解决方案,真正跑出一版带完整业务语境的 R1 满血推理集群——不仅在单机和小规模集群实验中有效,而且在严格 SLA 约束下,可以在 12 台 4P8D 架构的商用集群上稳定运行,将 PD 分离变成「可以被商业化复现的工程范式」。
结构共振,让 PD 分离从优化技巧走向推理范式
在本次联合方案中,商汤大装置提供了让 MemOS 三层记忆结构拥有物理载体的顶层系统级基础设施。依托大装置 IaaS的高效算力池、智能算力调度等为模型推理提供稳定的基础设施支撑;并借助Ignite 框架提供多后端推理适配、KVCache 管理优化、关键算子加速、跨节点通信调优等性能增强,形成体系化的推理优化链路;同时,商汤万象 MaaS 平台的统一调度策略确保 Prefill 与 Decode 服务在高并发场景下始终稳定运行。
集群的底层算力方面,则由算丰信息提供核心支撑,算丰信息在此次集群中承接管理了所有高性 GPGPU 计算资源、大规模文件对象存储以及高速互联网络服务,为 PD 分离架构的高效稳定运行提供了不可或缺的鼎力支持。
在商汤大装置的某国产 GPGPU 集群上,MemOS 的记忆结构被映射成了非常清晰的物理分工:
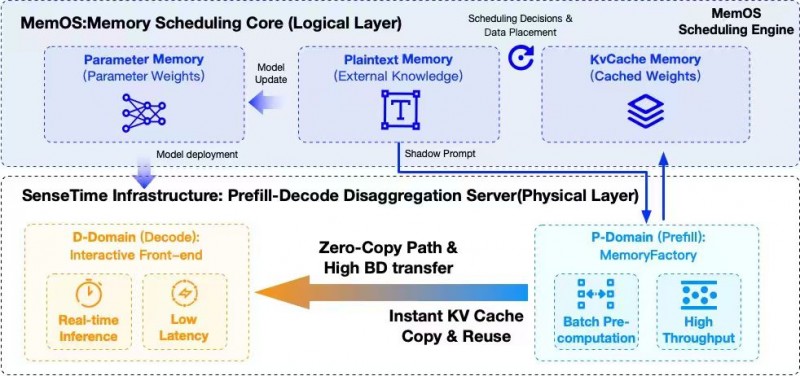
▪ P 域(Prefill Domain)变成真正的「记忆工厂」,集中承载影子上下文的预测与 KV Cache 的批量预生成,这些任务通常对吞吐敏感、对时延容忍度高,因此可以在 P 域以高并行、高利用率的方式运行,而不再与前台交互抢占资源;
▪ D 域(Decode Domain)则被打造为纯粹的「实时交互前台」,专注处理真实用户请求的解码过程,在保持超低 TTFT 的前提下,承担起 R1 这一类大模型在 C 端场景的连续输出与稳定响应;
▪ 跨节点 KV Cache 则通过高带宽互联与零拷路径实现「即产即用」,MemOS 的激活记忆机制与商汤大装置在某国产 GPGPU 上打磨出的通信能力形成天然互补,使 Prefill 产生的 KV Cache 不再成为传输瓶颈,而是以极低开销进入 D 域的解码流程中。
这次合作是一次体系级的结构共振:PD 分离为 MemOS 打开了一条真正意义上的高速算力通道,而 MemOS 则为 PD 分离提供了精细到记忆单元级别的调度逻辑和业务上下文,基于此,PD 分离*次从一个工程团队内部的「性能小技巧」,变成一套可以被完整描述、完整度量、并在生产环境中长期运行的新推理范式。
综合推理性价比达到同代 NVIDIA A100 的 150% 左右
在严格的生产级评测口径下——包括2k 输入、1k 输出、TTFT<2s 的 SLA 约束、72 小时以上稳态运行、统一的限流与负载生成策略——记忆张量与商汤大装置联合打造的国产 GPGPU 集群交出了这样一张答卷:
▪ 集群整体吞吐量提升超过 75%,从 Naive 部署下的 107.85 tokens/s 提升到 189.23 tokens/s,不是因为「卡更强了」,而是 Prefill 与 Decode 真正做到了算/存解耦,流水线气泡被有效压缩,影子上下文的批量预计算也不再造成资源浪费;
▪ 单卡并发能力提升约 20%,从 25.00 并发/卡提升至 29.42 并发/卡,这在 C 端场景下尤为关键,意味着在同等硬件规模下,集群能稳态承载更高的实时会话数,高峰期排队与溢出的风险明显降低;
▪ TTFT 全程稳定小于 2 秒,得益于 Prefill 全量前移和 D 域职责的「单一化」,Decode 不再被一些突发的重 Prefill 任务抢占资源,首字延迟因此从系统层面得到了保障;
▪ KV Cache 在热门场景中的命中率显著提升,可达 70%+,这使得诸如 MemOS-Chat 这一类需要高频、多轮交互的 C 端应用,在热点话题和常见任务上具备了极高的预计算复用率,推理成本被进一步摊薄;
▪ 在统一财务与技术口径下,综合推理性价比达到同代 NVIDIA A100 的 150% 左右,在严格 SLA 与相同负载结构下,某国产 GPGPU 在这一套「记忆原生×PD 分离×业务调度」的框架中,*次实现了对 A100 的体系级正面超越。
这些数字代表着:「国产 GPU 不再只是一个「可以跑大模型」的选项,而是真正具备了承载 R1 级 C 端业务的体系能力。」
行业意义:下一代推理范式被点亮
从行业视角来看,这次联合实践更重要的价值在于清晰地描绘出了一条未来大模型推理架构的可行路线。
首先,PD 分离从「硬件层的算存优化」,升级为「围绕记忆的推理范式设计」:在 MemOS 这样以记忆为核心组织推理流程的系统里,PD 分离可以延伸到行为预测、上下文规划、激活记忆布局等更高维度,从而变成整体架构的一部分,而不再是孤立的工程优化。
其次,C 端场景走向 Memory 推理:现在我们更关注的是:系统在多长时间尺度内能保持一致的人设、风格和偏好;它是否能记住用户的历史行为,并以此给出更智慧、更个性化的反应。在这个意义上,记忆不再是推理链路的外挂,而正在成为推理本身的中心。
未来,国产 GPU 不必也不应该只是在「算力参数」上做对标,而是有机会在体系结构上形成差异化*:通过 MemOS×商汤大装置的联合探索,我们可以看到:当底层架构与上层系统「共同为记忆和 Agent 这种新形态服务」时,国产生态完全可以定义自己的技术话语体系,而不是永远追随「通用加速器+通用框架」的旧范式。
打造记忆原生时代的国产 AI 基础设施新范式
未来,记忆张量与商汤将在这一范式之上继续深化合作:
▪ 一方面,围绕更大规模的国产 GPGPU 集群,构建真正意义上的记忆驱动流水线推理底座,让「影子上下文—激活记忆—PD 分离—多级缓存—AIOps」成为一套可观测、可回滚、可演进的基础设施能力;
▪ 另一方面,在 Prefill 行为预测自治化、多级激活记忆管理、跨任务长时记忆一致性、面向 Agent 的轨迹记忆等方向上持续打磨,让这套范式更能承载未来的伴随式 AI、具身智能体以及更复杂的长周期任务编排。
从更长远的视角看,这次联合实践带来的*改变是:国产算力体系*次拥有了另一条面向未来智能形态的可能「结构性路线」:从参数计算走向记忆计算,从静态推理走向动态流水线,从模型中心走向记忆中心。
可以预见,未来国产 GPGPU 不再只是「跟上来」的参与者,而完全有机会成为下一代推理范式的定义者之一。









