 旗下微信矩阵:
旗下微信矩阵:

近日,人工智能领域迎来重大技术突破,云知声正式推出Unisound U1-OCR文档智能基础大模型。作为行业*工业级文档智能基座,该模型凭借“性能SOTA、可信可验、开箱即用、高效部署、强适配”五大核心优势,彻底打破了传统文档处理的技术边界。这不仅标志着AI文档处理从单纯的“字符感知”正式迈向深层的“文档认知”新阶段,更被视为云知声在通往AGI(通用人工智能)道路上的关键里程碑。
首创OCR 3.0,实现“文档认知”质变
文档智能的发展经历了从OCR 1.0到2.0的演进。传统OCR 1.0(以CRNN为代表)仅能识别文字;新一代OCR 2.0(以VLM为代表)虽具备版面理解能力,但仍停留在表面。而Unisound U1-OCR的问世,正式开启了OCR 3.0时代——它在理解版面的基础上,进一步洞察文档深层语义,实现自动分类与业务级信息抽取。
在技术架构上,U1-OCR采用ViT + LLM架构,视觉编码器部分采用NaViT架构,模型参数规模控制在3B量级,*兼顾了计算效率与语义理解能力。其核心创新在于首创“语义驱动+动态聚焦”策略:不同于传统模型死板的顺序扫描,U1-OCR能像人类一样先构建文档的“语义地图”,梳理目录、标题的层级关系,再按需提取内容。此外,模型引入Multi-Token Prediction(MTP)技术,在预测当前Token时同步考虑未来多个Token的概率分布,配合全任务强化学习策略,使推理阶段生成效率提升了80%以上,并有效遏制了“定位幻觉”,确保了输出结果的物理可信度。
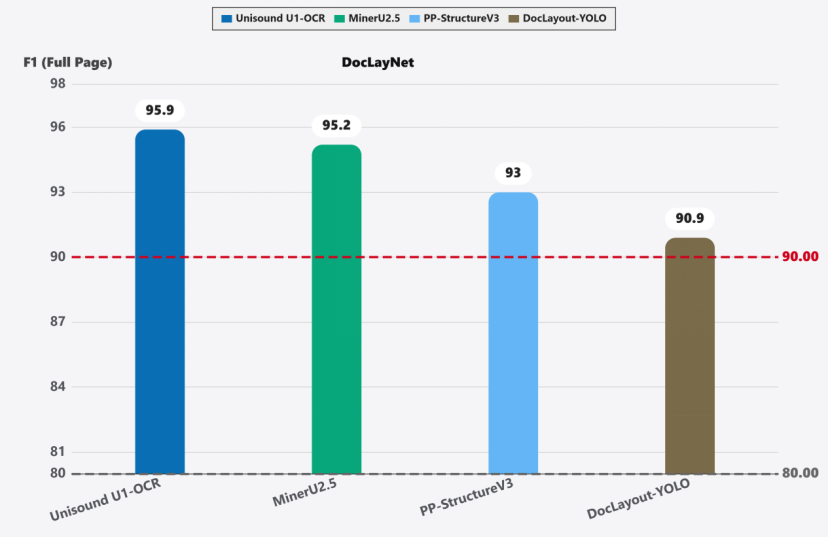
多项权威评测全球*梯队,小参数大能量
凭借深厚的技术积累,Unisound U1-OCR在多项国际权威评测中展现出业界*(SOTA)水平,甚至以3B的中小参数规模击败了众多超大参数模型。
在OmniDocBench V1.5评测中,U1-OCR以95.1分的高分取得SOTA表现,力压GLM-OCR、Deepseek-OCR2、Gemini-3-Pro以及GPT-5.2等主流大模型,实现了精度与泛化能力的双重突破。在D4LA评测中,其F1分数达到90.8,大幅领 先DocLayout-YOLO(87.3)和PP-StructureV3(86.0),且无需微调即可高精度解析学术论文、财务报表等11类高复杂度文档。在DocLayNet评测中,F1分数更是高达95.9,超越MinerU 2.5和PP-StructureV3,在表格识别、跨页关联等高难任务上表现出极强的鲁棒性。
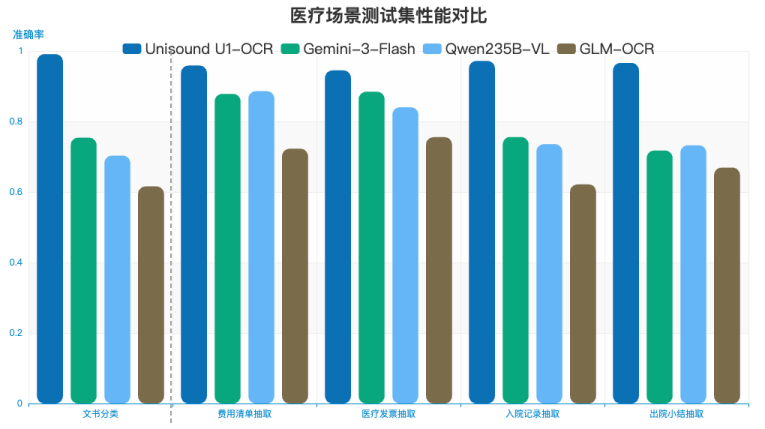
尤为值得一提的是在业务场景测试中,面对医疗入院记录、出院小结等强专业领域,U1-OCR以3B参数规模取得了优于Gemini-2.5-Flash、Qwen-235B-VL等更大规模通用VLM的评测性能,真正实现了“小而精”的工业级应用。
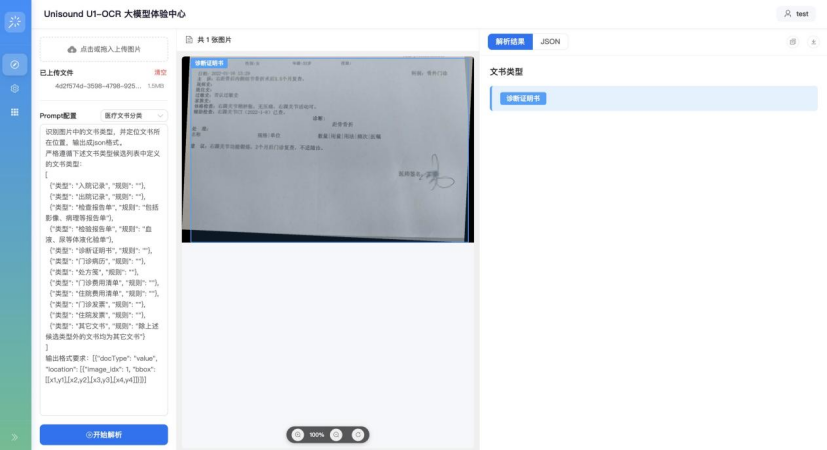
多项核心能力赋能千行百业
立足工业级场景需求,Unisound U1-OCR打造了“可信可查”与“业务融合”两大核心壁垒。模型*“坐标-文本-语义”融合架构,实现像素级精准定位与完整证据链构建,点击抽取结果即可高亮原始位置,让审核全透明、可追溯。同时,模型融入了云知声在医疗、金融等领域的行业知识积累,支持基于业务逻辑的多字段关联校验,在内部测试中,面向50余种常见业务文书的分类准确率超过99%,真正实现了“开箱即用”和Agent Ready。
真实场景的验证进一步彰显了其实力。在医疗费用清单抽取中,模型能自动兼容不同医院的写法差异,将“总计”“合计金额”统一映射至“总费用”字段,并精准剔除干扰项,实现数据直接入库;在复杂版式识别中,模型能像人一样自动判断段落承接关系,精准梳理内容流,并智能消除水印、校正扭曲版面。即便是跨行、跨列的复杂表格,也能完整保留原始行列逻辑,无需二次调整。
Unisound U1-OCR的发布,标志着AI从单纯“识字”跃迁至“理解业务逻辑”。未来,云知声将以多模态文档为知识入口,赋予机器自主推理与证据溯源能力,推动AI从感知走向认知,致力于构建能像人类一样阅读、思考并解决复杂问题的通用智能体。









