 旗下微信矩阵:
旗下微信矩阵:

3月19日,在中信证券举办的2026年春季资本市场论坛活动中,生数科技创始人、清华大学人工智能研究院副院长、ACM/IEEE/AAAI会士朱军教授发表题为《通用世界模型:连接数字世界与物理世界的桥梁》的主题演讲,系统阐述了生成式人工智能从“内容生成”迈向“物理世界”的关键技术路径。
他指出,随着统一模型架构逐步成型、数据范式持续完善,世界模型正迎来关键发展拐点,通用世界模型正在成为通向AGI(通用人工智能)的核心技术方向。
围绕这一方向,生数科技率先布局通用世界模型。于2025年7月和12月,公司联合清华大学相继发布了*基于视频大模型的具身基础模型Vidar和统一架构的通用基座世界模型Motus。相较国际领 先的 VLA 模型 Pi0.5 实现约40%的成功率提升,并率先发现了通用世界模型在多种具身任务上的泛化能力。

会上,朱军系统介绍了生数科技的通用世界模型战略布局。以基座世界模型(Foundation World Model)为核心底层,向上延伸出覆盖数字空间与物理空间的双轨技术体系。
基座世界模型基于全球首创的U-ViT架构,积累视觉、听觉、触觉等多模态信息,构建对世界的统一认知与建模能力,为上层应用提供统一的智能底座。
在数字空间,生数科技基于世界生成模型(WGM)打造视频大模型产品 Vidu。Vidu生成模型聚焦单时点模拟世界,赋能AI在数字世界的生产力。流式生成模型,聚焦多时点模拟世界,实现实时陪伴和交互。Vidu显著提升了数字内容的生产效率,最终实现数字世界的AGI。
在物理空间,生数科技基于世界行动模型(WAM)构建统一世界模型产品Motus。Motus作为真实世界具身智能的“大脑”,致力于解决传统具身智能链路割裂、数据稀缺、泛化能力弱等核心痛点,可实现真实世界下的零样本泛化与跨本体适配,推动机器人从“模块化执行”向“统一智能体”跃迁,最终实现物理世界的AGI。
这一布局贯通了从“理解世界”到“生成世界”再到“行动于世界”的完整路径,使通用世界模型真正成为连接数字与物理世界的桥梁。
生成式AI迈入新阶段:从“生成内容”到“理解世界”
生成式人工智能正在进入新的发展阶段,其核心目标不再局限于内容生成,而是刻画并理解物理世界的复杂分布。
“生成能力本身正成为理解世界的重要基础,如果不能生成,就无法真正理解。”朱军指出。
从概率图模型到深度学习,再到大规模预训练、Transformer与扩散模型的兴起,技术路径不断演进,持续逼近通用人工智能的能力边界。朱军表示,生成式AI的演进,本质上是对世界建模能力的不断增强。

视频:连接数字与物理世界的关键载体
在这一过程中,AI的发展重心正从语言进一步延展至视频。
“相比语言,视频天然包含更丰富的时空信息与物理规律,是连接数字世界与物理世界的关键载体。”朱军指出,“视频不仅是内容形式,更是世界运行规律的记录方式。”
同时,视觉在人的认知体系中占据主导地位,机器要真正理解世界,也必须以视觉为核心进行学习。但仅依赖大语言模型仍难以构建完整的智能闭环。真正的智能系统需要具备从经验中学习、对未来进行预测并执行行动的能力,这一过程依赖与物理世界的持续交互。

数据破局:以视频为核心构建数据金字塔
在数据层面,具身智能长期面临“数据墙”:真机数据稀缺、成本高、难以复用。
针对这一问题,以视频为核心的数据路径正在成为行业共识。通过构建覆盖互联网视频、人类操作视频、仿真数据与机器人数据的多层数据体系,可以系统性挖掘视频中蕴含的物理交互信息。
“视频是目前规模最 大、信息最丰富的数据形态,充分利用视频为主的可扩展、异构数据,是构建通用世界模型最可行的路径”朱军表示。
通过引入“隐动作(Latent Action)”等方法,模型可以将视频中的运动信息映射到动作空间,在缺乏大量真实机器人数据的情况下,依然具备有效的行动能力。
世界模型:从“模块拼接”走向“统一架构”
在上述背景下,通用世界模型正被视为实现通用人工智能的重要路径。
其核心目标是构建统一的智能系统,使AI能够完成从“观察世界”到“预测世界”,再到“在世界中行动”的完整闭环。然而,当前行业技术路径仍较为割裂:VLA模型侧重行为模仿,传统世界模型侧重未来预测,逆动力学模型聚焦动作生成,各自仅覆盖部分能力链路。
“世界模型不应是模块拼接,而需要像人一样,统一架构实现多种认知能力。”朱军表示。通用世界模型就是要在同一模型中融合感知、推理、预测与行动能力,构建类似人类“大脑”的整体智能结构。

统一世界模型Motus:开启具身智能多任务泛化与规模化演进新范式
基于上述数据与架构路径,生数科技联合清华大学开源的统一世界模型 Motus,实现了多模态能力的系统性整合。
在模型架构上,Motus基于 UniDiffuser 统一建模框架,通过跨模态先验融合(Cross-modal Priors Fusion),将视觉语言知识(VLM)、视频动态知识(Video Generation Model)与动作技能知识(Action Expert)整合进同一模型,实现语言、视频与动作的统一表达与生成,构建真正意义上的统一世界模型。
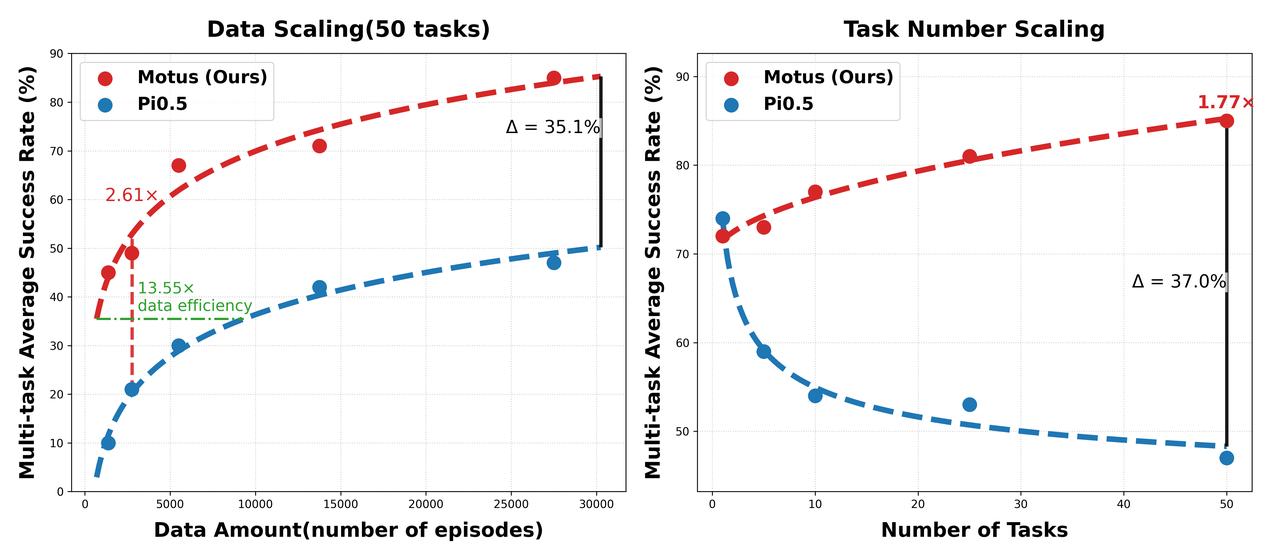
在数据利用与规模扩展方面,Motus展现出显著优势。在数据规模扩展实验(Data Scaling)中,相较国际领 先的VLA模型 Pi0.5,Motus能够从更广泛的异构数据中学习,并有效融合预训练基座模型中的多模态先验能力。在50个任务的平均成功率上,Motus实现了35.1%的*提升,同时在相同性能水平下展现出13.55倍的数据效率。
在任务规模扩展实验(Task Number Scaling)中,随着任务数量增加,Motus的平均成功率持续提升,而对比模型Pi0.5则随任务复杂度提升出现性能下降。最终,Motus实现了37%的*成功率优势,体现出更强的多任务泛化能力。
更值得注意的是,Motus率先揭示了具身智能Scaling的新维度——多任务泛化能力曲线。这一曲线为具身基座模型提供了关键的“北极星指标”,其演进路径与语言模型的发展高度一致,也呼应了 GPT-2 所提出的“Language Models are Unsupervised Multitask Learners”的核心思想,被喻为具身智能的“GPT2”时刻。
在长程、多步骤的复杂真机任务中,Motus 进一步呈现出接近人类水平的决策逻辑与执行稳定性,需要强调的是,这些都不是简单的单步指令,而是典型的长程、多步骤任务,并且由模型端到端完成,而非依赖传统的“快慢双系统”拆分。
拐点已近:通用世界模型能力将持续跃迁
正如图灵奖获得者Richard Sutton 在《苦涩的教训》中所指出的,“利用计算能力的通用方法最终是最有效的,而且优势巨大”。这一判断正在AI发展路径中不断得到验证。
朱军表示,以视频为核心的可扩展异构数据体系,是构建通用世界模型最可行的路径,并逐步形成行业共识。随着统一模型架构、数据范式与训练体系的持续成熟,通用世界模型的技术路径日益清晰,行业正进入由规模驱动的能力跃迁阶段。
在这一趋势下,从视频生成走向世界模型,正成为AI从“理解世界”迈向“改变世界”的关键路径。随着相关技术不断演进,通用世界模型将加速走向物理世界,成为连接数字世界与物理世界的桥梁。
看了这篇文章的用户还看了
- 绿岛风亮相2026上海酒店展!硬核展示全场景酒店健康空气解决方案
- 欢网科技 × 创视科技战略合作 共建跨场景生活圈媒体矩阵
- 智汇云舟亮相2026中关村论坛 联合发起“通智行业大脑”联盟
- 交天下客,锦江酒店商旅伴你行
- AI拍照解题技术新突破,传音相关研究成果入选计算机视觉顶会CVPR 2026
- 锚定“三个第 一” 深化“四个更新” 宝能集团全面启动干部培训整改提升专项行动
- 不止5万赞助:东鹏特饮×张雪机车,WSBK上演最燃的逆袭故事
- 从院内走向消费端,脑动极光携手Tokyo Lifestyle,打开“AI健康+零售”新空间
- 郭广昌亚布力谈舍与得,舍得酒携手亚布力中国企业家论坛扩容“高端朋友圈”
- 从创意到商业,IP赋能+产业护航,构建中部数字文创发展新高地
- 家庭清洁用品代工厂家推荐:广东加茜亚——您值得信赖的“送信人”









