 旗下微信矩阵:
旗下微信矩阵:

“我们新一批的国产算力卡到货了,我了解到的理论算力很强,性价比不要太高,赶紧从英伟达切过来。”
作为技术负责人,你满怀期待地在公司的 AI 应用上大展拳脚。然而,现实却迅速泼来一盆冷水:之前跑得好好的模型,现在要么直接报错,要么速度慢如蜗牛;多卡并行时系统频繁崩溃;最糟糕的是,有些模型的输出结果竟然出现了肉眼可见的偏差。
这并非虚构的场景,而是今天许多企业在适配国产算力时面临的真实困境。一个残酷的现实摆在眼前:将大模型推理从“纸面算力”成功落地到“业务价值”,中间隔着四堵看不见却异常坚固的高墙。这些挑战最终汇成四个让决策者夜不能寐的难题:跑不通、跑不快、跑不稳、跑不准。
《2025-2030 年中国算力芯片行业发展趋势及竞争策略研究报告》中指出,“2026 年推理算力需求占比将超 70%,算力芯片行业将迎来需求结构重塑与国产化深化的双重变革。”为了更好地把国产芯片用起来,用得好,我们需要直面并彻底拆解掉这“四堵墙”。
本文将带你逐一拆解每堵墙所面临的“技术挑战”和“业务影响”,希望能为所有走在国产算力落地路上的探索者,提供一份解惑指南。
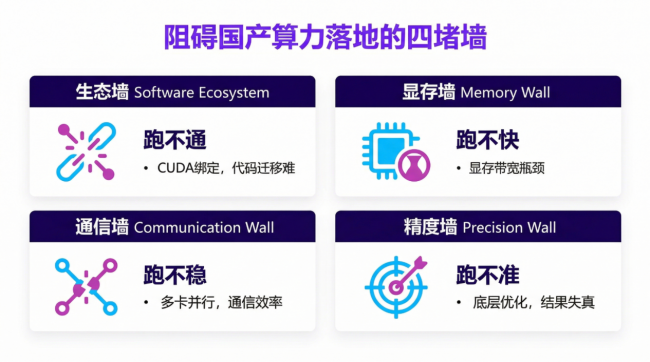
四大挑战:国产算力落地的“四堵墙”
要理解为何理论算力无法直接兑换为业务性能,我们必须认识到,大模型推理早已不是单纯的数学计算,而是一个涉及软件生态、硬件架构、通信协议和底层优化的复杂系统工程。这“四堵墙”正是横亘其中的核心障碍。
• 生态墙 (Software Ecosystem) → 跑不通:主流 AI 框架与 NVIDIA CUDA 深度绑定,代码迁移困难重重。
• 显存墙 (Memory Wall) → 跑不快:推理任务受限于显存带宽,而非计算能力,这是速度的核心瓶颈。
• 通信墙 (Communication Wall) → 跑不稳:多卡并行的效率和稳定性,被卡间互联速度和通信库成熟度死死扼住。
• 精度墙 (Precision Wall) → 跑不准:缺乏针对性的底层优化和对新数据格式的完善支持,导致结果失真。
接下来,我们将逐一击破这四堵墙。
生态墙:跑不通的“软件天堑”
这是所有挑战中最直接、*遇到的门槛。如同你无法在安卓手机上直接运行 iOS 应用,当前几乎所有主流大模型开源社区(如 HuggingFace)、推理框架(如 vLLM)和优化框架(如 DeepSpeed)都构建在 NVIDIA 的 CUDA 生态之上,这构成了一堵难以跨越的生态墙,这种差异主要体现在两个方面。
1. CUDA 代码强耦合
• 挑战:大量关键的推理优化代码,例如 PagedAttention 是直接“写死”(Hard-coded)为 CUDA Kernel 的,而FlashAttention 是基于 NVIDIA GPU 的 SRAM 大小和 Bank 架构定制的*优化。国产芯片都有自己的软件栈(如华为昇腾 CANN、海光 DTK、摩尔 MUSA),但往往需要进行代码转译或重写。
• 影响:如果照搬开源代码会导致切块策略失效,速度或许不升反降。虽然存在一些自动转译工具(如 CUDA-to-ROCm 或 CUDA-to-CANN),但其生成的代码性能往往远不如原生手写的。这意味着,为了让模型“跑起来”,企业需要投入巨大的工程资源进行底层代码的重写和调试。这不仅是技术成本,更是宝贵的时间成本。
2. 算子缺失的“最后一公里”
• 挑战:大模型技术迭代速度极快,几乎每个月都有新的模型结构或优化方法出现,例如混合专家模型(MoE)中的 Grouped GEMM 算子,或是某种新的激活函数。NVIDIA 凭借其庞大的生态和研发实力,总能*时间在其算子库(cuDNN)中提供支持。而国产芯片的算子库更新往往存在滞后性。
• 影响:当遇到一个国产算子库不支持的新算子时,系统可能会选择“回退执行”(Device-to-Host Copy),使整个推理流程支离破碎,导致严重的推理延迟。
显存墙:跑不快的“内存瓶颈”
在投入大量人力解决了生态问题后,模型终于跑起来了。但新的问题接踵而至:为什么速度这么慢?答案就藏在“显存墙”背后。
一个核心认知:大模型推理,本质上是 Memory-Bound(受限于访存带宽)的任务,而非 Compute-Bound(受限于计算能力)的任务。
打个比方来说,这就好比一位世界*厨师(计算单元),他一秒钟可以切好 100 盘菜,但食材(模型参数)运输员每秒只能从冷库(显存)里搬运 10 盘菜的原料。那么,厨师的效率瓶颈就不再是他的刀工,而是运输员的速度。
我们从“带宽”和“容量”两个维度来分析显存瓶颈。
1. 带宽瓶颈
• 挑战:NVIDIA H100/A100 拥有极高带宽内存(HBM),传输速率可达 3TB/s 以上。对比来看,部分国产芯片受限于供应链和先进封装工艺(CoWoS),HBM 带宽通常较低。
• 影响:在模型生成 Token 的解码阶段(Decode Phase),计算单元往往在“等数据”。显存带宽越低,每秒生成的 Token 数量(TPS)就越低。
2. 容量瓶颈
• 挑战:除了带宽,容量同样关键。早期国产单卡显存容量普遍较小,比如 32G/64G,尽管持续有更大尺寸的产品推出,但是面对像 72B/671B 这样的大模型,单卡依然无法承载,必须进行多卡切分。
• 影响:一旦需要多卡协作,数据必须在卡与卡之间频繁传输,就不可避免地引入了卡间通信开销。计算等通信,推理延迟直线飙升,并发受限。
这直接将我们引向了下一堵高墙——通信墙。
通信墙:跑不稳的“协作难题”
此时,我们就进入了“分布式推理”的深水区。决定系统整体性能甚至稳定性的,不再是单卡的计算或访存能力,而是多张卡之间的“沟通效率”,卡间互联的速度决定了推理服务生死。
1. 互联带宽差距
• 挑战:NVIDIA 的 NVLink/NVSwitch 技术,实现高达 900GB/s 的双向通信带宽。相比之下,国产芯片通常依赖 PCIe Gen5(约 128GB/s)或各自的私有互联协议(如华为的 HCCS),在带宽上还存在一定差距。
• 影响:在进行 Tensor Parallel (TP) 多卡并行推理时,因通信较慢,通信耗时可能超过计算耗时,导致“加卡不加速”,多卡推理扩展性差。
2. 通信库的“成熟度考验”
• 挑战:NVIDIA 的集合通信库(NCCL)历经多年迭代,在各种极端负载下都表现得非常成熟稳定。而国产通信库(如 HCCL、CNCL)仍有优化空间,比如在极端并发下的鲁棒性仍需打磨。
• 影响:面对高并发请求,存在通信抖动、死锁、丢包、建链失败等故障发生的概率,可能导致推理服务出现莫名的超时或波动,支撑核心在线业务存在风险。
精度墙:跑不准的“细节魔鬼”
跨越了前面这三堵墙,我们的系统终于能以“还行”的速度稳定运行了。但当我们仔细检查输出结果时,却可能发现新的“魔鬼”——结果不准。这背后,和底层优化与精度支持不足有关,这一层是“这就叫专业”的分水岭。
1. FlashAttention 深度适配缺失
FlashAttention 依赖于对 GPU SRAM(片上缓存)的精细控制。不同国产芯片的 SRAM 大小、架构与 NVIDIA 完全不同。如果只是生搬硬套 FlashAttention 的算法逻辑,而没有针对特定芯片的 SRAM 大小进行 Tiling(切块)参数调优,性能可能不升反降。
2. 精度缺失
英伟达原生支持 BF16/FP8,国产芯片以支持 FP16 为主,部分芯片对 BF16 的硬件加速支持还不够完善,多使用 FP16,导致推理时需要进行 Cast 操作,或面临精度溢出风险,模型输出乱码或服务直接崩溃。
3. INT4 缺失
W4A16(4bit 权重 16bit 激活)是目前的趋势(如 Marlin Kernel),业界通过 W4A16 提升推理速度。从目前行业实践来看,多数国产芯片对 INT4 的硬件加速支持尚在完善中,部分场景下可能无法实现预期提速。
结语:跨越四堵墙,从“能用”到“好用”
回顾这四堵高墙,我们不难发现,国产算力落地大模型推理,是一场对企业技术战略、工程能力和生态耐心的全面考验。它要求我们必须从过去“买来就用”的采购者心态,转变为“共同构建”的参与者心态。
对于正在这条路上探索的技术决策者,以下几点思考或许能提供帮助:
1. 场景匹配,务实切入:并非所有业务都需要最*的性能。对于延迟不敏感、模型迭代较慢的任务,国产算力是当下*性价比的选择。找准切入点,积累经验,远比一步到位更重要。
2. 投资人才,锤炼内功:真正的护城河,是拥有一支能够深入硬件底层、进行 Kernel 优化、玩转分布式通信的硬核团队。这部分人才的价值,在未来会愈发凸显。
3. 拥抱协作,共同成长:国产芯片适配需要多环节打磨,向外生态协作,比如协同芯片厂商、MaaS 平台等,共同解决问题,形成正向飞轮。以硅基流动的私有化 MaaS 平台为例,在国产芯片适配与加速提效上已经积累了丰富的实践经验,可以很好地支持异构算力统一纳管与调度,支持多架构、多品牌算力资源的接入与智能调度,实现算力资源集中管理与高效利用。
国产算力的崛起之路注定充满挑战,但这四堵墙并非无法逾越。每一次代码的重写、每一次算子的优化、每一次通信的调试,都是在为未来的坦途铺路。真正的赢家,将属于那些最早看清挑战、并以最坚定的耐心和智慧去克服它们的先行者。
您的企业有部署国产算力吗?在推理服务落地的过程中遇到过以上的挑战吗?您是怎么解决的?欢迎分享宝贵经验。
【内容来源:硅基流动】硅基流动深耕 AI 基础设施领域,公司定位为“Token 工厂”,致力于通过自研推理加速引擎,让开发者实现“Token 自由”,让模型像水电一样能按需使用。其私有化 MaaS 大模型服务平台,一站式为企业客户提供从异构算力纳管、模型训练、推理部署到场景落地的闭环解决方案。帮助客户以更低成本、更快速度、更高性能、更强稳定性,安全可靠地规模化落地大模型应用,满足从研发到生产的全链路需求。









