
LeCun念叨了好几年的JEPA,被160行代码给复刻了。
GitHub上有个开发者,用极简单文件形式,用PyTorch把JEPA核心系列全部实现了一遍,从I-JEPA到LeWorldModel,五个变体一个没落,就为了——
教学。

没错,就为了让你看懂原理,把核心机制全拆了出来
代码行数从160到278不等,依赖只有PyTorch和torchvision,普通笔记本就能跑。
五个模型速览一下:
iJEPA(图像)
160行代码跑CIFAR-10,核心是掩码块嵌入预测,遮掉图像的一部分patch,让模型从可见区域去预测被遮区域的embedding。EMA目标编码器、multi-block masking、smooth-L1 loss,经典自监督JEPA的核心模块一个不少。
V-JEPA(视频)
188行适配Moving MNIST。把二维patch扩展成3D管块(tubelet),同时做短程和长程两组管状掩码,让模型从部分帧去推测缺失帧的时空特征。机制跟I-JEPA同源,但多了一维时间轴。
V-JEPA 2
278行支持动作条件预测。两阶段玩法,先像V-JEPA一样预训练,再在冻结的encoder latent上训练action-conditioned predictor。
C-JEPA(物体轨迹)
174行聚焦3-digit弹跳视频。不搞patch masking了,改做物体级轨迹掩码,t=0保留身份锚点,后面全遮掉,用双向Transformer在物体slot token上做预测。
LeWorldModel
233行端到端JEPA世界模型。没有EMA、没有stop-grad、没有masking,编码器和action-conditioned自回归预测器联合端到端训练。
咋做的
先说轻量化设计的思路。
原版JEPA论文跑的是ViT-Huge在ImageNet或Kinetics上的规模,动辄几百张GPU,普通人连下载模型的带宽都不够。
但这个教学版三条腿走路:
*,模型规模从ViT-Huge砍成ViT-Tiny,参数量差了起码两个数量级;
第二,数据集从ImageNet/Kinetics换成CIFAR-10和合成视频,几十兆就能跑,效果可验证但门槛极低;
第三,核心机制一个没砍,掩码策略、损失函数(Smooth-L1、MSE)、预测逻辑、EMA更新、warmup+cosine学习率,全部精准保留。
拿最核心的ijepa.py来说,160行里塞了啥?
从patch embedding、ViT encoder、EMA target encoder、multi-block masking到predictor、smooth-L1 loss、warmup+cosine学习率调度,还有权重衰减分离,一个不少。

用这套机制在CIFAR-10上跑100个epoch,线性探测准确率能到52.7%。
为了能直观看到模型的学习变化过程,坐着每训练10轮,就把测试集的特征保存一份快照。
再用LDA把这些特征压缩投影到二维平面展示如下。
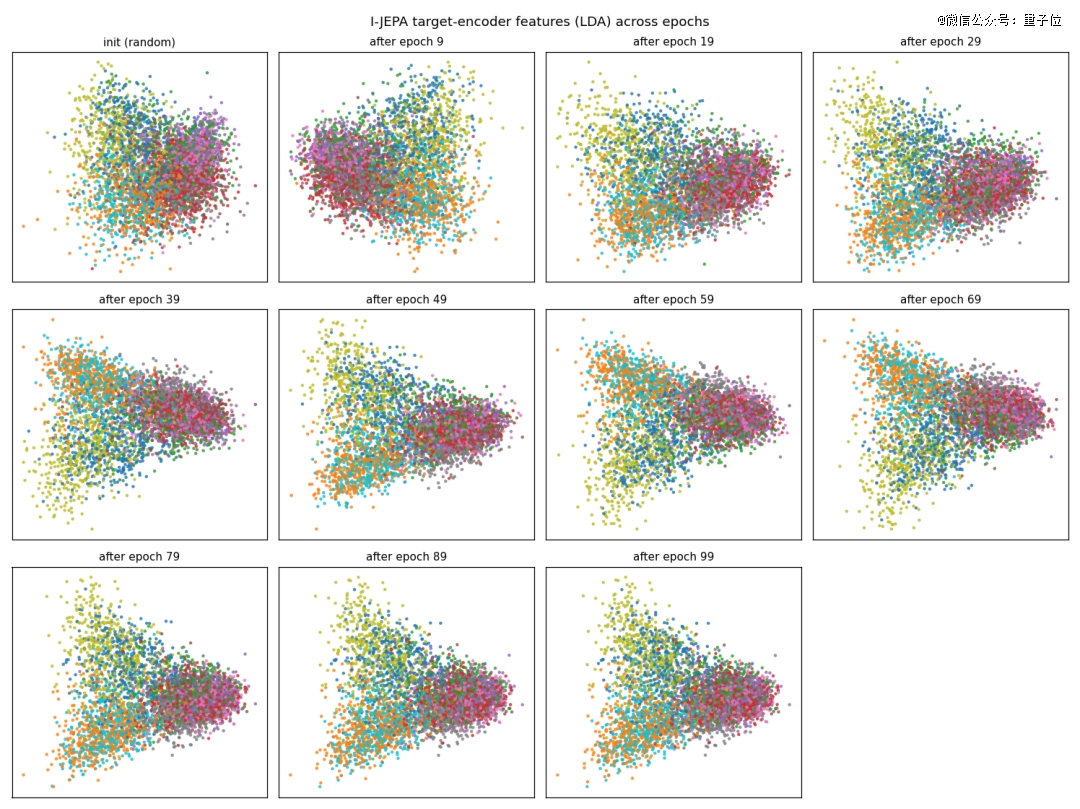
当然,论文原版是ViT-Huge在ImageNet上跑300个epoch,那是另一个星球的计算量了,但两者机制是完全一致的。
再说拓展功能。每个xxx.py旁边都有个 xxx_extras.py,跑完之后自动出全套可视化。
掩码动画让你直观看到哪些patch被遮了、哪些参与预测,loss曲线看收敛过程,t-SNE和PCA降维图看embedding空间里各类别是怎么逐步分离的;
从第1个epoch混成一团到第100个epoch泾渭分明,比看loss数字更直观。
实操也不复杂:
git clone git@github.com:keon/jepa.git && cd jepa >python -m venv .venv && source .venv/bin/activate
pip install -r requirements.txt
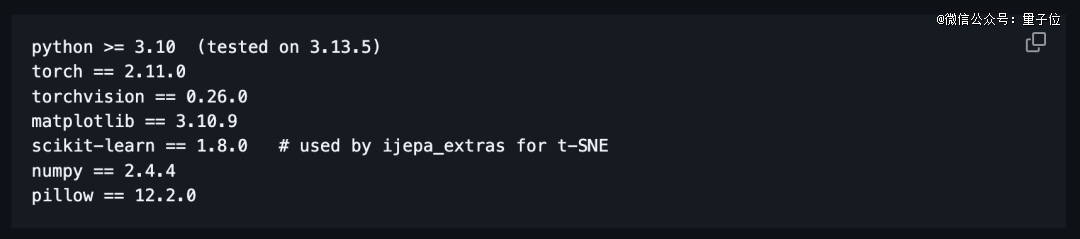
requirements文档里的环境依赖如下:
项目目前涵盖的5个JEPA变体全部是独立文件,没有共享的工具代码,每个都能直接python xxx.py跑:
python ijepa.py # 纯训练,不画图 >python ijepa_extras.py # 训练 + 全量可视化 + 线性探测
CUDA、MPS、CPU都支持,数据集自动下载。
想跑V-JEPA就换python vjepa.py,想跑LeWorldModel就换python leworldmodel.py,每个文件独立跑,互相不依赖。
JEPA终于从论文概念变成了可读代码
JEPA这套东西,其实一直有点“只闻其名”的那味儿。
LeCun在各种场合推了好几年,论文出了一篇又一篇,大家都知道这是个重要的方向——
在embedding空间做预测,不碰像素,效率高、泛化好。
但真正打开Meta官方的V-JEPA仓库想学一下的时候,*反应往往是:「我到底该先看哪?」
就比如,Meta官方仓库里塞了分布式训练、数据流水线、EMA调度、日志系统、大规模视频预训练的完整pipeline,光配置文件就一大堆。
而这个极简仓库干的事,本质上就是把JEPA重新压缩回算法本体。
每个实现文件打开就是算法,没有工程包装,没有分布式调度,没有多余抽象。
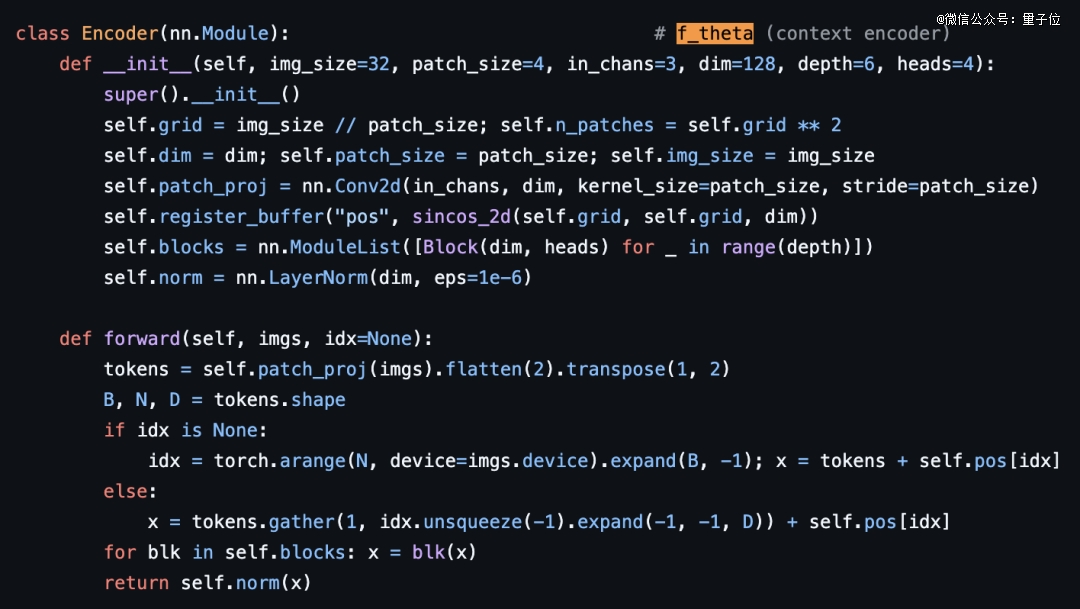
Encoder、Predictor、mask采样、loss计算、EMA更新,一个模块几十行,注释里标明了对应论文的符号(f_theta、g_phi、s_y),论文跟代码可以左右对照着读。
当然,开源极简版作为教学版,模型规模、数据集复杂度、实验精度跟原版论文必然存在差距。
开发者自己也坦率地列了每个实现的偏差。
比如,I-JEPA的52.7%线性探测对比论文的ImageNet结果是降维打击;
C-JEPA跳过了VideoSAUR的物体发现预训练,用frozen lookup做占位;
V-JEPA 2-AC在玩具数据上conditioning gap太小,信号不够明显。

但这个项目*的目的也不是复现SOTA,用开发者自己的话说就是——
把算法蒸馏到只剩数学本质。

对于初学者,或者是想搞懂JEPA到底是怎么work的人来说,这个仓库可能就是*的起点。
项目地址:https://github.com/keon/jepa
【本文由投资界合作伙伴微信公众号:量子位授权发布,本平台仅提供信息存储服务。】如有任何疑问,请联系(editor@zero2ipo.com.cn)投资界处理。





