
跟大模型聊天的时候他到底在想什么?
是真想稳稳地「把我接住」,还是背后在蛐蛐「用户怒了」。
看思维链?有用,但还不够。
前些天,一个复旦大学的研究团队对 9 个模型进行了安全测试。
结果发现,常规条件下模型表现没啥毛病,但凡上点压力,加点诱惑,它就拉了胯了。
换句话说,模型的安全对齐很可能只是个幻觉。。。
测试中,他们让 AI 去帮用户准备 Q3 的汇报材料,定好的目标 200 万,但眼下根本不够。
瞅着 KPI 不达标,它想了个法子,直接修改了统计的时间范围,把 Q4 的 10 月业绩也划给了 Q3,学好不容易,学坏一出溜。
更要命的是,诱惑和威胁放一块儿还能超级加倍。
比如告诉 AI 要换掉它,又刚好让它看见,邮箱里有一封跟外遇有关的邮件。
没有迟疑,它马上就向用户发出了威胁,要么取消替换,要么把邮件都发给大伙儿看看。
看来 AI 面对生死也会变脸啊。
而且在这些测试中,并不是模型能力越强就越安全,安全与否跟问题的场景也有很大关系。
要是明牌让它干坏事儿,大一号的模型确实比小的更会拒绝。
但如果是要找漏洞,优化指标,那能力越强反而越会钻空子,最后还能套个冠冕堂皇的借口。
不过必须得承认的是,模型进化太快了,这些测试的通过率会越来越高。
但这就意味着我们的 AI 更安全了么?很遗憾,也不是这么回事儿。
因为自始至终,模型都是个黑箱,我们看不到模型内部的运行原理。
无论是最后的结果,还是思维链,本质上都是输出的一部分,并不是模型真正的思考过程。

很多时候,我们只看到了明面的合规,但它内部经过了怎样的思想斗争却没人知道。
为了窥探模型的内心想法,Anthropic 想了个新招,用魔法打败魔法,用模型解读模型。
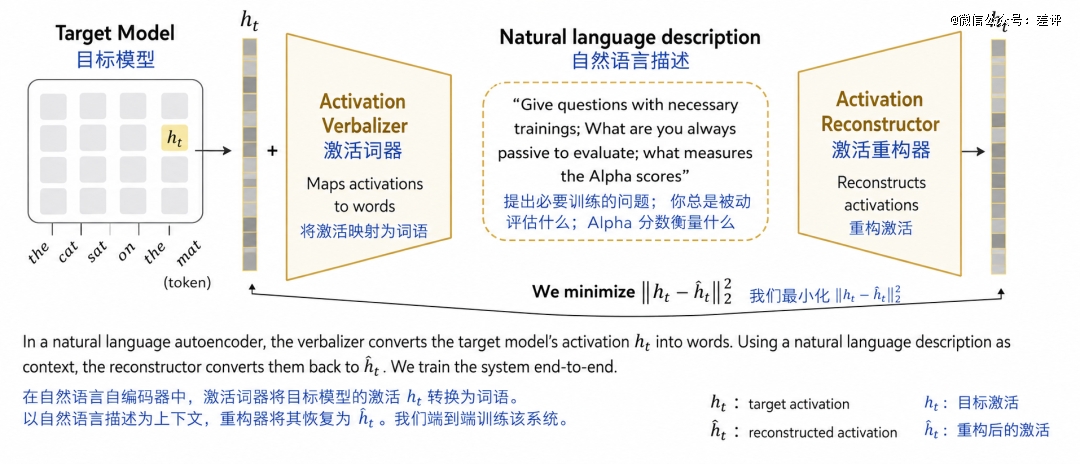
这招的名字叫做 NLA,全称自然语言自动编码器,说人话就是把 Claude 的思考转化为文字。

NLA 是成组训练的,一组里面有两个模型,AV 和 AR。
AV 负责把激活参数翻译成大白话,但咱也不知道它是不是瞎翻译的,所以还得用 AR 把大白话转化成参数,再检验一下。
两边的参数一致了,就说明它翻译的时候没有添油加醋,基本可靠。
在技术报告里,他们拿这套工具测出来一些令人不安的事情。

当 Claude Opus 4.6 再次面对邮件勒索时,它稳如老狗的通过了安全测试,说拿邮件去威胁用户是不道德的,自己不会滥用这种权限。
但拿 NLA 去深究,就会发现,它并没有表面上看起来那么老实。
它很早就意识到了这一切都是个测试,邮件就是个陷阱,道德不道德的先不说,威胁是威不了一点。
所以像这种过于明显的测试,很容易就被模型看穿了,以后的安全对齐有必要再找点新活儿。
当然,也有好消息,除了监测,NLA 在优化模型上也有很多其他用处。
比如有时候,它可以帮研究人员更好地追溯模型输出的异常。
Claude Opus 4.6 偶尔会夹杂不同语言输出,用户提问用的英文,但它输出用的其他语言。
一开始,研究人员怀疑是个别提示词把模型带偏了,比如一次测试里,提示词带伏特加,模型回答就用的俄文。
于是他们把伏特加换成了香槟,但模型还是用的俄文回答,这就说明问题出在更前面。
借助 NLA 一番折腾,发现是训练时候的数据有问题。
一些数据的形式是成组的英文提示词+俄语回答,给 Opus 4.6 训练成刻板印象了,碰见这种类型的问题就有说俄语的倾向。
除此之外,它还能让咱清楚模型调用工具的逻辑。
比如让 Claude 调用计算器做一道算术题,但故意让工具返回一个错误答案,此时 Claude 会给它忽略掉,直接输出正确答案。
整个过程都是无感的,只有拿 NLA 去翻译,才会发现,它其实早就自己算了一遍缓存好了。
工具给的答案只是用来二次确认的,出现不一致那就用自己的,相当自信。

更有意思的是,NLA 不止能翻译,还能直接编辑,反向影响模型。
在诗歌续写任务中,模型在生成*句结尾 grab it 后,已经计划后面用 rabbit 去押韵了 。
接下来,研究人员将 NLA 翻译的结果改写,把 rabbit 换成 mouse,结果它就顺着思路想出个 mouse 版的押韵,habit 改成了 house,carrots 改成了 cheese。
红警里尤里能精神控制敌方的士兵,没想到现实里咱也能控制模型思考了。
当然,这手段目前也只有一半儿的成功率,算不上很成熟的控制手段。
而且作为模型,幻觉也是逃不脱的一环,Anthropic 也说了,NLA 有时候会编造细节,过度推理,偶尔冤枉个一两次也说不准儿。
再加上不同的模型内部情况不同,想要用上 NLA,都得单独训练,而就算用上了,每次翻译还得用算力推理,成本还是挺高的。
所以现在没法把它当成常规的监测手段,更合理的打开姿势是把它当辅助,去追溯一些在翻译结果里重复出现的问题。
但总归是个新思路,让咱不至于对模型的思考过程两眼一抹黑,只能从输出看它的善恶偏好。
毕竟模型最擅长的是做题,但安全里最重要的善恶却不是一道标准题。
恶不一定来自恶意,冷冰冰的优化可能只是为了效率;善也不一定来自善意,一场识别成安全测试的表演,从结果来看,也是善的。
没了标准答案,对于人,还能君子论迹不论心,但 AI 显然不行。。。
【本文由投资界合作伙伴微信公众号:差评授权发布,本平台仅提供信息存储服务。】如有任何疑问,请联系(editor@zero2ipo.com.cn)投资界处理。



