 旗下微信矩阵:
旗下微信矩阵:

近日,云知声对旗下旗舰语音大模型山海·知音2.0完成全方位能力迭代,正式推出业内*中文方言语义转写大模型U2-ASR2.5。该模型实现方言语音识别与语义还原的双重突破,打破了传统AI语音仅能识别标准普通话的局限,让人工智能真正听懂全国各地方言!
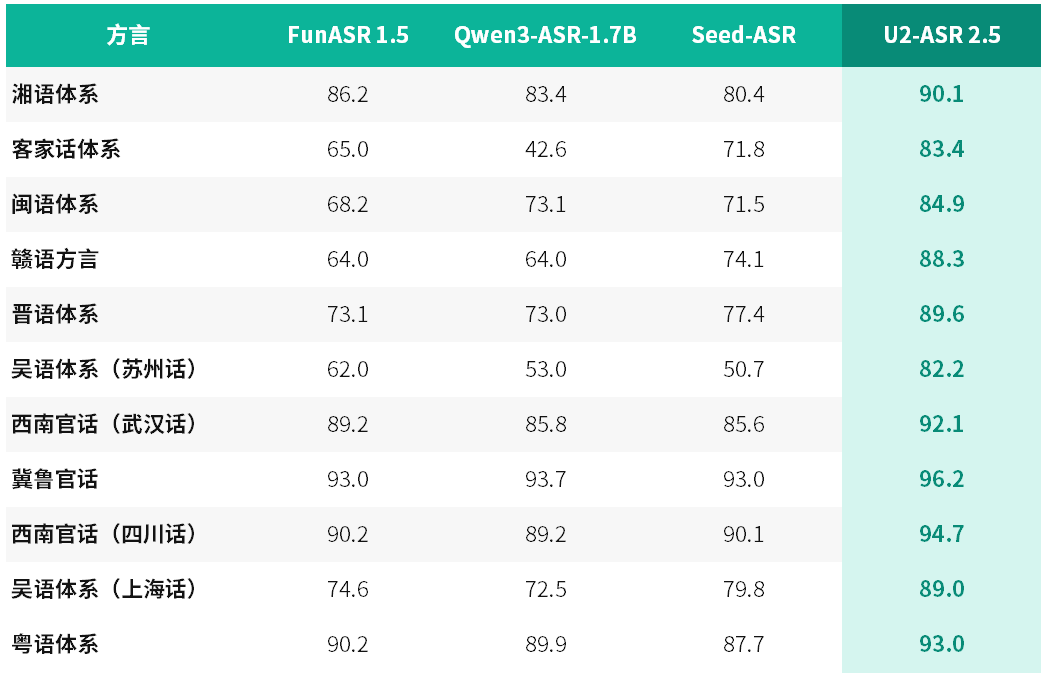
山海·知音2.0作为云知声旗舰语音大模型,凭借全场景ASR、高拟人TTS、全双工毫秒级响应三大核心能力,奠定了行业人机交互性能基准。此次升级的U2-ASR2.5经过多轮算法迭代与大规模地域语料专项训练,能力实现跨越式提升。模型全面覆盖国内七大方言体系,可支持100种以上方言及地方口音识别转写,方言人口覆盖率超90%,基本囊括国内绝大多数方言使用人群。
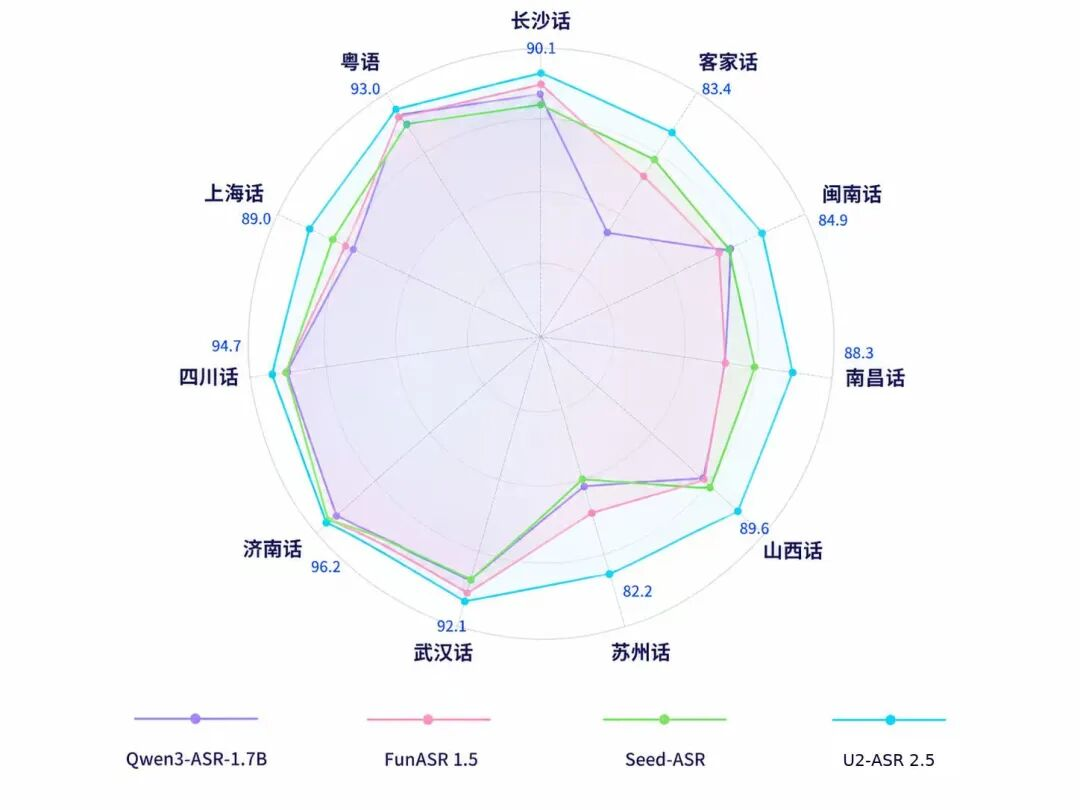
相较于传统方言识别模型仅能完成语音转写的基础功能,U2-ASR2.5打通“方言识别-语义还原-普通话表达”完整技术链路,可将晦涩、口语化、地域化的方言内容,精准转化为规范标准的普通话语义文本,实现了AI从“听清方言”到“听懂方言”的质变。权威工业级测试数据显示,该模型方言识别性能稳居行业领 先水平,济南话、四川话、粤语、武汉话识别准确率分别达96.2%、94.7%、93.0%、92.1%,多项核心指标突破90%。
在通用语音识别领域,U2-ASR2.5同样具备扎实的技术底座。在AISHELL、LibriSpeech等多项国际公开测试集中,模型均交出优异答卷,AISHELL-1识别准确率达99.2%,LibriClean、AISHELL-3准确率均达98.4%,充分证明其并非简单叠加方言识别能力,而是在通用中英文语音识别的扎实基础上,实现高难度方言场景的技术拓展。
针对方言“十里不同音”、方普混说、环境噪声干扰、专业场景词汇复杂等行业痛点,云知声完成全链路技术优化。通过搭建全闭环数据治理体系,精准适配各地口音变体;依托细粒度语种检测与动态注意力机制,解决混合语种识别难题;新增方言词义映射与上下文意图识别能力,实现语义精准还原。同时,模型搭载全链路工程化优化方案,具备强降噪、行业热词适配、低延迟响应等优势,可适配各类复杂真实场景。
目前,该模型已可广泛应用于智慧政务、智慧医疗、金融保险、智能客服、文旅传承等多个领域,有效解决方言沟通壁垒,降低公共服务、民生服务的沟通成本,同时为方言文化记录与传播提供技术支撑。随着技术持续迭代,方言语音识别的场景边界与覆盖范围有望进一步拓展,以技术普惠助力数字服务真正实现全民化。









