
生成式人工智能即将到来,它将改变世界。自从 ChatGPT 席卷全球并激发了我们对人工智能可能性的想象力以来,我们看到各种各样的公司都在争先恐后地训练人工智能模型并将生成式人工智能部署到内部工作流程或面向客户的应用程序中。不仅仅是大型科技公司和初创公司,许多财富500强非科技公司也在研究如何部署基于LLM的解决方案。
当然,这需要大量的 GPU 计算。GPU 的销量像火箭一样猛增,而供应链却难以满足对 GPU 的需求。公司正在争先恐后地获得 GPU 或云实例。
即使 OpenAI 也无法获得足够的 GPU,这严重阻碍了其近期路线图。由于 GPU 短缺,OpenAI 无法部署其多模态模型。由于 GPU 短缺,OpenAI 无法部署更长的序列长度模型(8k 与 32k)。
与此同时,中国公司不仅投资部署自己的LLM,还在美国出口管制进一步收紧之前进行储备。例如,据新闻报道,中国公司字节跳动据称从 Nvidia 订购了价值超过 10 亿美元的 A800/H800。
虽然数十万个专门用于人工智能的 GPU 有许多合法的用例,但也有很多情况是人们急于购买 GPU 来尝试构建他们不确定是否有合法市场的东西。在某些情况下,大型科技公司正试图赶上 OpenAI 和谷歌,以免落后。对于没有经过验证的商业用例的初创公司来说,有大量的风险投资资金。我们知道有十几家企业正在尝试利用自己的数据训练自己的LLM。最后,这也适用于沙特阿拉伯和阿联酋今年也试图购买数亿美元的 GPU 的国家。
尽管 Nvidia 试图大幅提高产量,但*的 Nvidia GPU H100 直到明年*季度仍将售空。Nvidia 每季度将增加 400,000 个 H100 GPU 的出货量。

Nvidia 的 H100 采用 CoWoS-S 上的7-die封装。中间是H100 GPU ASIC,其芯片尺寸为814mm2 ,周围是 6 个内存堆栈HBM。不同 SKU 之间的 HBM 配置有所不同,但 H100 SXM 版本使用 HBM3,每个堆栈为 16GB,总内存为 80GB。H100 NVL 将具有两个封装,每个封装上有 6 个活跃的 HBM 堆栈。
在只有 5 个激活 HBM 的情况下,非 HBM 芯片可以使用虚拟硅,为芯片提供结构支撑。这些芯片位于硅中介层的顶部,该硅中介层在图片中不清晰可见。该硅中介层位于封装基板上,该封装基板是 ABF 封装基板。
GPU Die和 TSMC晶圆厂
Nvidia GPU 的主要数字处理组件是处理器芯片本身,它是在称为“4N”的定制台积电工艺节点上制造的。它是在台积电位于台湾台南的 Fab 18 工厂制造的,与台积电 N5 和 N4 工艺节点共享相同的设施,但这不是生产的限制因素。
由于 PC、智能手机和非 AI 相关数据中心芯片的严重疲软,台积电 N5 工艺节点的利用率降至 70% 以下。英伟达在确保额外的晶圆供应方面没有遇到任何问题。
事实上,Nvidia 已经订购了大量用于 H100 GPU 和 NVSwitch 的晶圆,这些晶圆立即开始生产,远远早于运送芯片所需的晶圆。这些晶圆将存放在台积电的芯片组中,直到下游供应链有足够的产能将这些晶圆封装成完整的芯片。
基本上,英伟达正在吸收台积电的部分低利用率,并获得一些定价优势,因为英伟达已承诺进一步购买成品。
Wafer bank,也被称为die bank,是半导体行业的一种做法,其中存储部分处理或完成的晶圆,直到客户需要它们为止。与其他一些代工厂不同的是,台积电将通过将这些晶圆保留在自己的账簿上几乎完全加工来帮助他们的客户。这种做法使台积电及其客户能够保持财务灵活性。由于仅进行了部分加工,因此晶圆库中保存的晶圆不被视为成品,而是被归类为 WIP。只有当这些晶圆全部完成后,台积电才能确认收入并将这些晶圆的所有权转让给客户。
这有助于客户修饰他们的资产负债表,使库存水平看起来处于控制之中。对于台积电来说,好处是可以帮助保持更高的利用率,从而支撑利润率。然后,随着客户需要更多的库存,这些晶圆可以通过几个最终加工步骤完全完成,然后以正常销售价格甚至稍有折扣的价格交付给客户。
HBM 在数据中心的出现:
AMD 的创新如何帮助 Nvidia
GPU 周围的高带宽内存是下一个主要组件。HBM 供应也有限,但正在增加。HBM 是垂直堆叠的 DRAM 芯片,通过硅通孔 (TSV) 连接并使用 TCB进行键合(未来更高的堆叠数量将需要混合键合)。DRAM 裸片下方有一颗充当控制器的基本逻辑裸片。
通常,现代 HBM 具有 8 层内存和 1 个基本逻辑芯片,但我们很快就会看到具有 12+1 层 HBM 的产品,例如 AMD 的 MI300X 和 Nvidia 即将推出的 H100 更新。
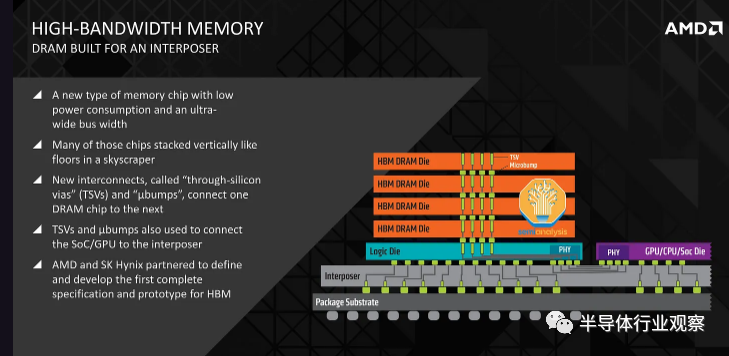
有趣的是,尽管 Nvidia 和 Google 是当今使用量*的用户,但 AMD 率先推出了 HBM。2008 年,AMD 预测,为了匹配游戏 GPU 性能而不断扩展内存带宽将需要越来越多的功率,而这些功率需要从 GPU 逻辑中转移出来,从而降低 GPU 性能。AMD 与 SK Hynix 以及供应链中的其他公司(例如 Amkor)合作,寻找一种能够以更低功耗提供高带宽的内存解决方案。这驱使 SK 海力士于 2013 年开发了 HBM。
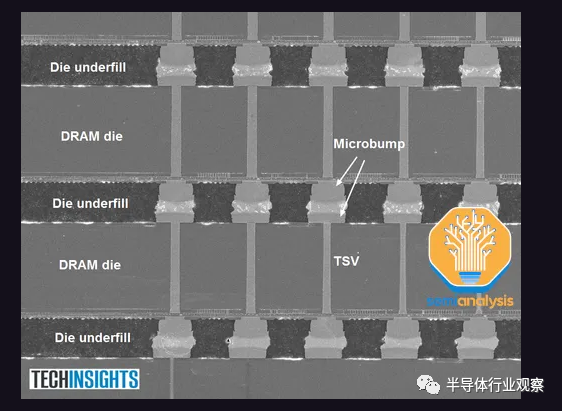
SK Hynix 于 2015 年首次为 AMD Fiji 系列游戏 GPU 提供 HBM,该 GPU 由 Amkor 进行 2.5D 封装。随后,他们在2017 年推出了使用 HBM2 的 Vega 系列。然而,HBM 并没有对游戏 GPU 性能产生太大的改变。由于没有明显的性能优势以及更高的成本,AMD 在 Vega 之后重新在其游戏卡中使用 GDDR。如今,Nvidia 和 AMD 的*游戏 GPU 仍在使用更便宜的 GDDR6。
然而,AMD 的最初预测在某种程度上是正确的:扩展内存带宽已被证明是 GPU 的一个问题,只是这主要是数据中心 GPU 的问题。对于消费级游戏 GPU,Nvidia 和 AMD 已转向使用大型缓存作为帧缓冲区(large caches for the frame buffer),使它们能够使用带宽低得多的 GDDR 内存。
正如我们过去所详述的,推理和训练工作负载是内存密集型的。随着人工智能模型中参数数量的指数级增长,仅权重的模型大小就已达到 TB 级。因此,人工智能加速器的性能受到从内存中存储和检索训练和推理数据的能力的瓶颈:这个问题通常被称为“内存墙”。
为了解决这个问题,*的数据中心 GPU 与高带宽内存 (HBM) 共同封装。Nvidia 于 2016 年发布了* HBM GPU P100。HBM 通过在传统 DDR 内存和片上缓存之间找到中间立场,以容量换取带宽来解决内存墙问题。通过大幅增加引脚数以达到每个 HBM 堆栈 1024 位宽的内存总线,可以实现更高的带宽,这是每个 DIMM 64 位宽的 DDR5 的 18 倍。同时,通过大幅降低每比特传输能量 (pJ/bit) 来控制功耗。这是通过更短的走线长度来实现的,HBM 的走线长度以毫米为单位,而 GDDR 和 DDR 的走线长度以厘米为单位。
如今,许多面向HPC的芯片公司正在享受AMD努力的成果。具有讽刺意味的是,AMD 的竞争对手 Nvidia 作为 HBM 用量*的用户,或许会受益最多。

HBM市场:SK海力士占据主导地位
作为HBM的先驱,SK海力士是拥有*进技术路线的*。SK 海力士于 2022 年 6 月开始生产 HBM3,是目前*一家批量出货 HBM3 的供应商,拥有超过 95% 的市场份额,这是大多数 H100 SKU 所使用的。HBM 现在的*配置为 8 层 16GB HBM3 模块。SK Hynix 正在为 AMD MI300X 和 Nvidia H100 刷新生产数据速率为 5.6 GT/s 的 12 层 24GB HBM3。

HBM 的主要挑战是存储器的封装和堆叠,这是 SK 海力士所擅长的,他们过去在这方面积累了最强大的工艺流程知识。
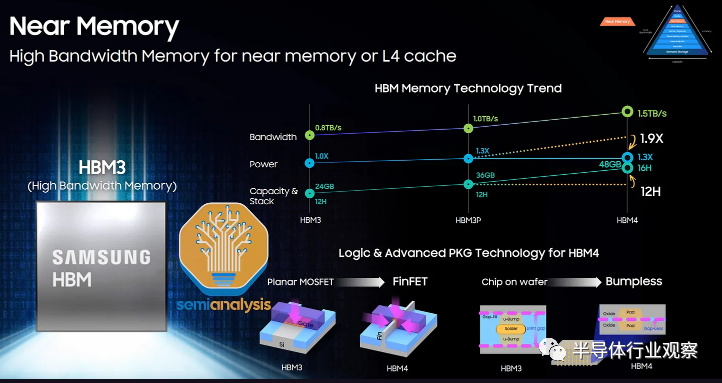
三星紧随 Hynix 之后,预计将在 2023 年下半年发货 HBM3。我们相信它们是为 Nvidia 和 AMD GPU 设计的。他们目前在销量上与 SK 海力士存在很大差距,但他们正在紧锣密鼓地前进,并正在大力投资以追赶市场份额。三星正在投资以追赶并成为 HBM 市场份额*,就像他们在标准内存方面一样。我们听说他们正在与一些加速器公司达成优惠协议,以试图获得更多份额。
他们展示了 12 层 HBM 以及未来的混合键合 HBM。三星 HBM-4 路线图的一个有趣的方面是,他们希望在内部 FinFET 节点上制作逻辑/外围设备。这显示了他们拥有内部逻辑和 DRAM 代工厂的潜在优势。

美光科技在HBM方面排名垫底。
他们在混合存储立方体 (HMC) 技术上投入了更多资金。这是与 HBM 竞争的技术,其概念非常相似,大约在同一时间开发。然而,HMC周围的生态系统是封闭的,导致围绕HMC的IP很难开发。此外,还存在一些技术缺陷。HBM 的采用率要高得多,因此 HBM 胜出,成为 3D 堆叠 DRAM 的行业标准。
直到 2018 年,美光才开始从 HMC 转向 HBM 路线图。这就是美光科技落在最后面的原因。他们仍然停留在HBM2E(SK海力士在2020年中期开始量产)上,他们甚至无法成功制造HBM2E。
在最近的财报电话会议中,美光对其 HBM 路线图做出了一些大胆的声明:他们相信,他们将在 2024 年凭借 HBM3E 从落后者变为*者。HBM3E 预计将在第三季度/第四季度开始为 Nvidia 的下一代 GPU 发货。
“我们的 HBM3 斜坡实际上是下一代 HBM3,与当今业界生产的 HBM3 相比,它具有更高水平的性能、带宽和更低的功耗。该产品,即我们行业*的产品,将从 2024 年*季度开始销量大幅增加,并对 24 财年的收入产生重大影响,并在 2025 年大幅增加,即使是在 2024 年的水平基础上。我们的目标也是在 HBM 中获得非常强劲的份额,高于行业中 DRAM 的非自然供应份额。”美光首席商务官Sumit Sadana说。
他们希望在 HBM 中拥有比一般 DRAM市场份额更高的市场份额的声明非常大胆。鉴于他们仍在努力大批量生产* HBM2E,我们很难相信美光声称他们将在 2024 年初推出*的 HBM3,甚至成为*个 HBM3E。在我们看来,尽管Nvidia GPU 服务器的内存容量比英特尔/AMD CPU 服务器要低得多,但美光科技似乎正在试图改变人们对人工智能失败者的看法。
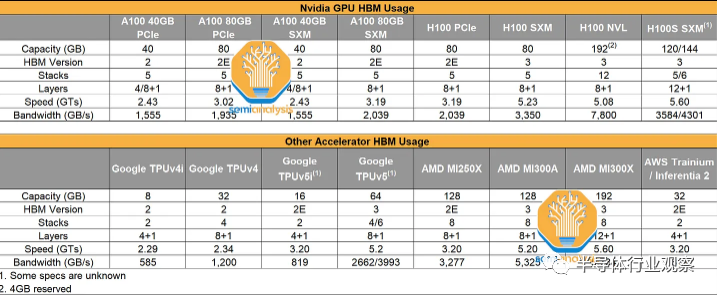
我们所有的渠道检查都发现 SK 海力士在新一代技术方面保持最强,而三星则非常努力地通过大幅供应增加、大胆的路线图和削减交易来追赶。
真正的瓶颈 - CoWoS
下一个瓶颈是 CoWoS 产能。CoWoS(Chip on Wafer on Substrate)是台积电的一种“2.5D”封装技术,其中多个有源硅芯片(active silicon)(通常的配置是逻辑和 HBM 堆栈)集成在无源硅中介层上。中介层充当顶部有源芯片的通信层。然后将中介层和有源硅连接到包含要放置在系统 PCB 上的 I/O 的封装基板。
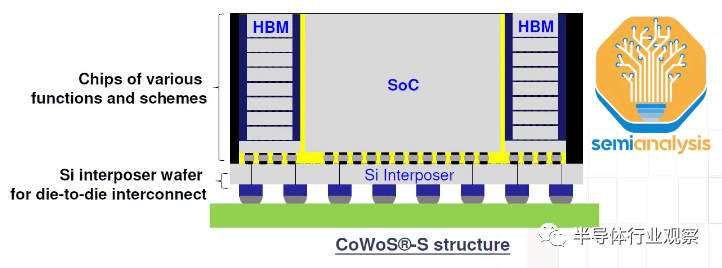
HBM 和 CoWoS 是互补的。HBM 的高焊盘数(high pad count)和短走线长度要求需要 CoWoS 等 2.5D 先进封装技术来实现 PCB 甚至封装基板上无法实现的密集、短连接。CoWoS是主流封装技术,能够以合理的成本提供最高的互连密度和*的封装尺寸。由于目前几乎所有 HBM 系统都封装在 CoWoS 上,并且所有高级 AI 加速器都使用 HBM,因此,几乎所有*的数据中心 GPU 都由台积电在 CoWoS 上封装。百度确实有一些先进的加速器,三星的版本也有。
虽然台积电 (TSMC) 的 SoIC 等 3D 封装技术可以将芯片直接堆叠在逻辑之上,但由于散热和成本的原因,这对于 HBM 来说没有意义。SoIC 在互连密度方面处于不同的数量级,并且更适合通过芯片堆叠扩展片上缓存,如 AMD 的 3D V-Cache 解决方案所示。AMD 的 Xilinx 也是多年前 CoWoS 的*批用户,用于将多个 FPGA 小芯片组合在一起。
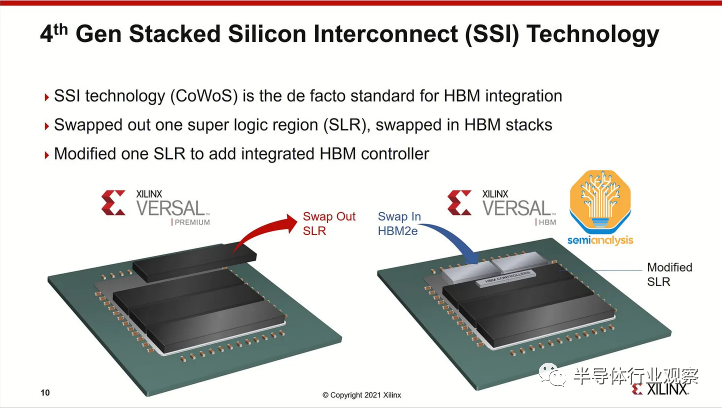
虽然还有一些其他应用使用 CoWoS,例如网络(其中一些用于网络 GPU 集群,如 Broadcom 的 Jericho3-AI )、超级计算和 FPGA,但绝大多数 CoWoS 需求来自人工智能。与半导体供应链的其他部分不同,其他主要终端市场的疲软意味着有足够的闲置空间来吸收 GPU 需求的巨大增长,CoWoS 和 HBM 已经是大多数面向人工智能的技术,因此所有闲置产能已在*季度被吸收。随着 GPU 需求的爆炸式增长,供应链中的这些部分无法跟上并成为 GPU 供应的瓶颈。
“就在最近这两天,我接到一个客户的电话,要求大幅增加后端容量,特别是在 CoWoS 中。我们仍在评估这一点。”台积电首席执行官C.C Wei早起那说。
台积电一直在为更多的封装需求做好准备,但可能没想到这一波生成式人工智能需求来得如此之快。6月,台积电宣布在竹南开设先进后端Fab 6。该晶圆厂占地 14.3 公顷,足以容纳每年 100 万片晶圆的 3D Fabric 产能。这不仅包括 CoWoS,还包括 SoIC 和 InFO 技术。有趣的是,该工厂比台积电其他封装工厂的总和还要大。虽然这只是洁净室空间,远未配备齐全的工具来实际提供如此大的容量,但很明显,台积电正在做好准备,预计对其先进封装解决方案的需求会增加。
稍微有帮助的是晶圆级扇出封装产能(主要用于智能手机 SoC)的闲置,其中一些产能可以在某些 CoWoS 工艺步骤中重新利用。特别是,存在一些重叠的工艺,例如沉积、电镀、背面研磨、成型、放置和RDL形成,这将趋势设备供应链发生了有意义的转变。
虽然市场上还有来自英特尔、三星和 OSAT (例如 ASE 的 FOEB)提供的其他 2.5D 封装技术,但CoWoS 是*一种大批量使用的技术,因为台积电是迄今为止最主要的 AI 加速器代工厂。甚至Intel Habana的加速器也是由台积电制造和封装的。然而,一些客户正在寻找台积电的替代品。
CoWoS 拥有几种变体,但原始 CoWoS-S 仍然是大批量生产中的*配置。这是如上所述的经典配置:逻辑芯片 + HBM 芯片通过带有 TSV 的硅基中介层连接。然后将中介层放置在有机封装基板上。
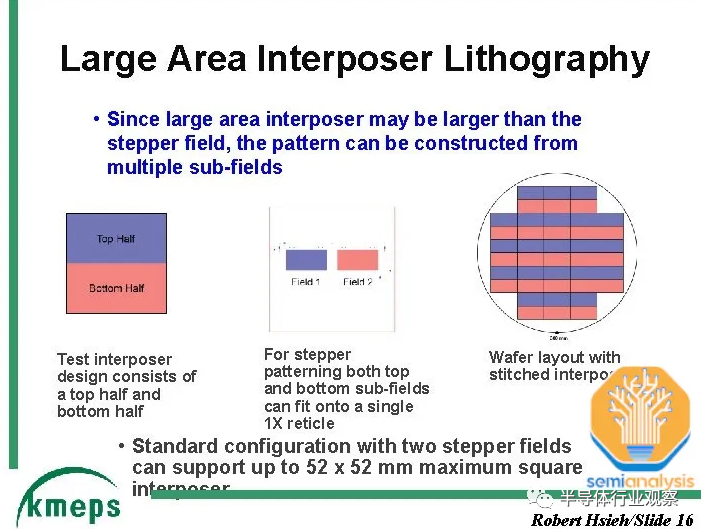
硅中介层的一项支持技术是一种称为“reticle stitching”的技术。由于光刻工具slit/scan*尺寸芯片的*尺寸通常为26mm x 33mm 。随着 GPU 芯片本身接近这一极限,并且还需要在其周围安装 HBM,中介层需要很大,并且将远远超出这一标线极限。TSMC 通过reticle stitching解决了这个问题,这使得他们能够将中介层图案化为标线限制的数倍(截至目前,AMD MI300 最高可达 3.5 倍)。
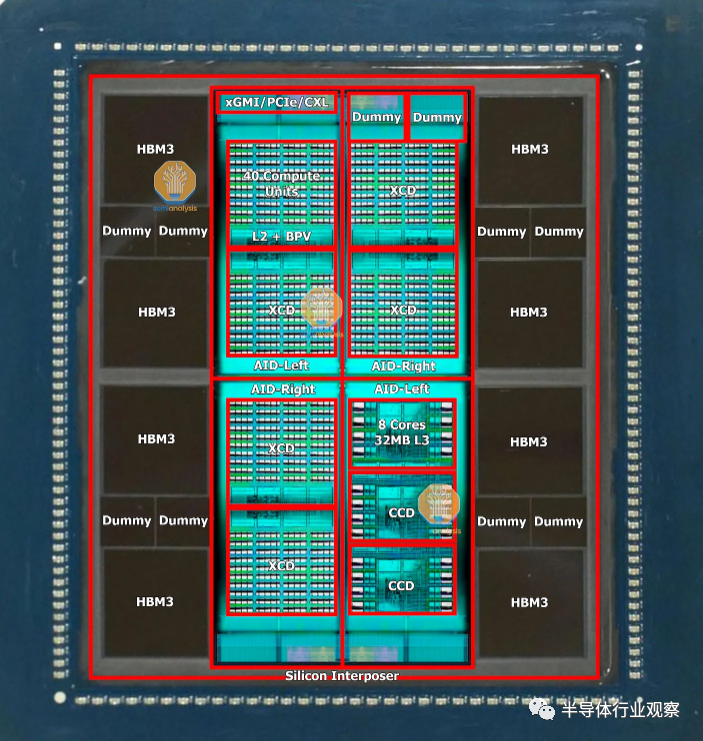
CoWoS-R 在具有重新分布层 (RDL) 的有机基板上使用,而不是硅中介层。这是一种成本较低的变体,由于使用有机 RDL 而不是硅基中介层,因此牺牲了 I/O 密度。正如我们所详述的,, AMD 的 MI300 最初是在 CoWoS-R 上设计的,但我们认为,由于翘曲和热稳定性问题,AMD 必须改用 CoWoS-S。
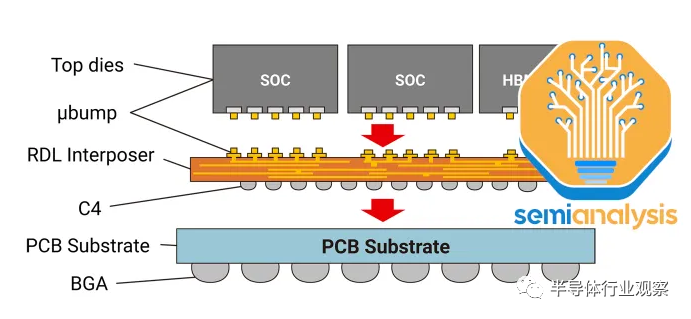
CoWoS-L 预计将在今年晚些时候推出,并采用 RDL 中介层,但包含嵌入中介层内部的用于芯片间互连的有源和/或无源硅桥。这是台积电相当于英特尔EMIB封装技术。随着硅中介层变得越来越难以扩展,这将允许更大的封装尺寸。MI300 CoWoS-S 可能接近单硅中介层的极限。
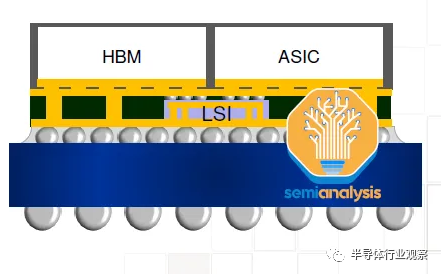
对于更大的设计来说,使用 CoWoS-L 会更加经济。台积电正在开发6x reticle尺寸的 CoWoS-L 超级载具中介层。对于 CoWoS-S,他们没有提到 4x reticle 之外的任何内容。这是因为硅中介层的脆弱性。这种硅中介层只有 100 微米厚,并且在工艺流程中随着中介层尺寸增大而存在分层或破裂的风险。
【本文由投资界合作伙伴微信公众号:半导体行业观察授权发布,本平台仅提供信息存储服务。】如有任何疑问,请联系(editor@zero2ipo.com.cn)投资界处理。




