
近年来,半导体工艺水平的不断提升使芯片性能得到显著增强,但是摩尔定律正在逐渐逼近物理极限。同时,随着CPU、GPU、FPGA等高性能运算芯片性能的持续提升,AI、5G、云计算等应用相继兴起,各类应用场景对高带宽、高算力、低延时、低功耗的需求愈发强烈。
高昂的研发费用和生产成本,与芯片的性能提升无法持续等比例延续。为解决这一问题,“后摩尔时代”下的芯片异构集成技术——Chiplet应运而生,或将从另一个维度来延续摩尔定律的“经济效益”。
Chiplet也称作“芯粒”或“小芯片”,它是将原本一块复杂的SoC芯片,从设计时就按照不同的功能单元进行分解,然后每个单元选择最适合的制程工艺进行制造,再通过先进封装技术将各个单元彼此互联,就像“乐高积木”一样封装为一个SoC芯片。

Chiplet的优势可以归结为几个方面:
1)大幅提高大芯片良率。近年来,随着高性能计算、AI等方面的运算需求,集成更多功能单元和更大的片上存储使得芯片不仅晶体管数量暴增,芯片面积也急剧增大。芯片良率随着芯片面积的增大而下降,掩模尺寸700mm²的设计通常会产生大约30%的合格芯片,而150mm²芯片的良品率约为80%。因此,通过Chiplet设计将大芯片分成更小的芯片可以有效改善良率,同时也能够降低因为不良率而导致的成本增加。
2)降低设计的复杂度和设计成本。因为如果在芯片设计阶段,就将大规模的SoC按照不同的功能模块分解为一个个的Chiplet,那么部分Chiplet可以做到类似模块化的设计,而且可以重复运用在不同的芯片产品当中。这样不仅可以大幅降低芯片设计的难度和设计成本,同时也有利于后续产品的迭代,加速产品的上市周期。
3)降低芯片制造成本。一颗SoC中有不同的计算单元,同时也有存储、各种I/O接口、模拟或数模混合元件,这其中主要是逻辑计算单元通常依赖于先进制程来提升性能,而其他的部分对于制程工艺的要求并不高,有些即使采用成熟工艺,也能够发挥很好的性能。所以,将SoC进行Chiplet化之后,不同的芯粒可以根据需要来选择合适的工艺制程分开制造,然后再通过先进封装技术进行组装,不需要全部都采用先进的制程在一块晶圆上进行一体化制造,这样可以极大的降低芯片的制造成本。
简而言之,Chiplet旨在将芯片性能与芯片工艺解耦,从而解决芯片设计中面临的复杂度大幅提升问题,以及先进制程中面临的高成本、低良率问题。
在多种优势因素及市场趋势驱动下,AMD、台积电、英特尔、英伟达等芯片巨头以及众多国内外相关企业嗅到了市场机遇,近年来开始纷纷入局Chiplet。
在这个过程中,互连成为Chiplet走向的决定因素之一。
Chiplet互联现状
多年来,业内一直在寻找一种“真正的互连”,以便在芯片组中实现从裸片到裸片(Die-to-Die)的通信,更好的完成数据存储、信号处理、数据处理等丰富的功能。如何让芯粒之间高速互联,是Chiplet技术落地的关键,也是全产业链目前面临的一大全新挑战。
芯片设计公司在设计芯粒之间的互联接口时,首要保证的是高数据吞吐量。另外,数据延迟和误码率也是关键要求,还要考虑能效和连接距离。
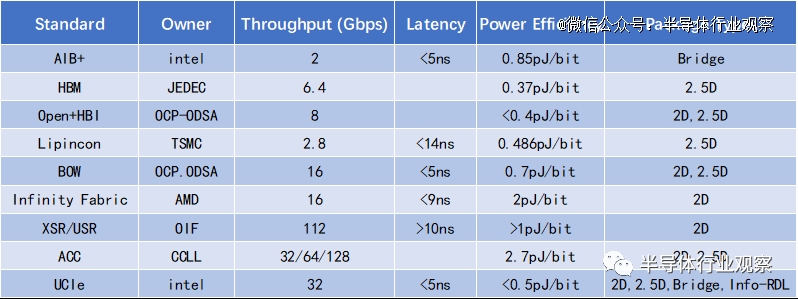
到目前为止,已经成功商用的Die-to-Die互连接口协议多达十几种,主要分为串行接口协议和并行接口协议。串行接口及协议有LR、MR、VSR、XSR、USR等SerDes串行互连技术,PCIe、NVLink,用于Cache一致性的CXL、CCIX、TileLink、OpenCAPI,以及中国Chiplet产业联盟(CCLL)推出的ACC接口标准等;并行接口及协议有AIB/MDIO(Intel)、LIPINCON(TSMC)、Infinity Fabric(AMD)、OpenHBI(Xilinx)、BoW(OCP ODSA)、INNOLINK(Innosilicon),以及用于存储芯片堆叠互联的HBM接口等...
比较而言,串行接口一般延迟比较大,而并行接口可以做到更低延迟,但也会消耗更多的Die-to-Die互连管脚,而且因为要尽量保证多组管脚之间延迟的一致,所以每个管脚不易做到高速率。
可以看到,这些芯片巨头们在积极探索Chiplet技术,但同时大家又各自为战,推动自己的高速互联协议标准。
目前市面上部分现有互联标准对比如下:
有观点指出,不同工艺、功能和封装的芯片之间没有统一的通信接口,会造成严重的资源浪费。
对此,清华大学交叉信息研究院助理教授、北极雄芯创始人马恺声向笔者表示,在不同应用场景中Chiplet的组合形式可能是多样化的,例如需要传输的数据形态及特点、对延迟/误码等指标的容忍度、对封装的要求、量产成本的考虑等可能均有所不同,因此Die to Die接口作为芯粒之间实现数据传输的“桥梁”,可能在不同应用场景中亦有不同的优化方向。
他指出,我们看到业界所谓“各自为战”的状态,其实更本质反映的是不同产品场景互联的差异化需求;比如苹果在M1/M2 Ultra上自研的Ultrafusion方案、英伟达的NVLink方案等等都是芯片厂商与封装厂商共同深度研发的成果,但目前也均以满足自身产品性能需求为首要目的。不同的互联标准,在信号模式、传输速率及带宽、封装规格等方面均有所不同,背后均体现了在特定领域优化的方向。
在众多互联标准中,Intel提出的通用Chiplet互联标准UCIe成为行业中比较受关注的焦点。
UCIe旨在芯片封装层面确立互联互通的统一标准,以帮助在整个半导体行业建立一个开放的小芯片生态系统。
UCIe是一种分层协议,它指定了物理层、die-to-die适配层和协议层:
UCIe标准的推出旨在助力Chiplet从“清谈”向“实操”迈进,从“各家各户自说自话”向“组队厮杀迈进”。希望巨头们合力搭建起统一的Chiplet互联标准,让终端使用者打造SoC芯片时,可以自由搭配来自多个厂商生态系统中的小芯片,加速推动开放的Chiplet平台发展。
但从目前实际进展来看,几乎所有基于Chiplet设计的共同点是它们都是在一家公司内完成的。这与每个人都希望能够从小芯片商店(Chiplet store)的货架上挑选他们想要的小芯片,然后通过SiP封装来工作的理想情况相差甚远。
从行业现状来看,无论是UCIe,还是其他互联方案,仿佛都未能承担起Chiplet互联接口标准化“桥梁”的角色,小芯片商店的梦想还很遥远。
北极雄芯在接受笔者采访时也表示,UCIe标准协议推出的现时意义在于两个方面:一是众多一线大厂的入局推动后摩尔时代技术路线的走向,二是为众多芯片设计厂商在Chiplet架构上带来了一个可选的方案。初期的助力效应是明显的,我们已经看到一些企业从UCIe接口IP、封装方案等不同维度开始投入研发,但产业生态的成熟需要历经必不可少的周期迭代。
同时,基于UCIe依赖先进工艺、互连距离约束大等限制因素,UCIe可以在小圈子、限定场景内有一定的统一性,但难以直接适用于整个Chiplet生态上。
马恺声指出,从目前现状来看,业界围绕UCIe开展的工作少之又少,基本还是处于“各自为战”的状态,一方面是目前没有成熟的IP,就算有也是部分海外IP厂商只有5nm和3nm现成的IP;另一方面本来做Chiplet的公司也不多,就算是Intel自家的服务器芯片Sapphire Rapids,也是内部闭源的并口,以及今年在Hot Chips上展示的硅光互连芯片,与共封装的光接口互连是基于他们内部更成熟的AIB方案。
可见,无论是基于什么标准,我们下一步需要看到可用的接口方案逐步推出,以及越来越多的芯片设计公司把这些标准下的接口用起来,才能真正形成行业互联规范。
Chiplet技术的关键除了互连,还在于封装。
随着Chiplet技术的发展终究会使小芯片间的互联达到更高的密度,要应对先进封装功能和密度的不断提升,散热、应力和信号传输等都是重大的考验。目前头部的IDM厂商、晶圆代工厂以及封测企业都在积极推动不同类型的先进封装技术,以抢占这块市场。
在芯片尺寸不断增大、架构变得复杂的情况下,封装结构由原先的二维发展至三维。按封装介质材料和封装工艺划分,Chiplet的实现方式主要包括以下几种:MCM、2.5D封装、3D封装。目前台积电拥有CoWoS/InFO、英特尔拥有EMIB、Fovores 3D等,Chiplet使用的先进封装多种多样,且新的封装形式和结构还在不断演进。
但是在高性能、短距离互连领域,一般要通过Interposer(中介层)或者Silicon Bridge(硅桥)进行互连,封装成本比较高。
例如,在片间互连中的高线密度可能要求使用支持高线密度的基板或桥接技术。高带宽存储器(HBM)的启用可能是这一趋势的*证明——因为HBM只能与ASIC集成在同一个封装中,而且此时只能在2.5D的硅中间层配置中集成。
虽然硅基封装技术已经发展为批量制造解决方案,但成本和复杂性可能会阻止它们成为大多数低端应用的解决方案。
Chiplet互连技术,迎来新突破
迄今为止,业界*的小芯片互连需要先进封装和昂贵的硅中介层。
而Eliyan凭借其Nulink技术,可以为die-to-die互联在各种封装衬底上提供功耗、性能和成本的优势方案。因为这种PHY接口可以让不同的裸片直接在有机衬底上实现高速互联,而不必采用CoWoS、EMIB或硅中介层等昂贵的先进封装方式,在降低成本的同时加速产品制造周期。
左边是当今常见的使用硅中介层的Chiplet互连方法;右边是Eliyan的NuLink技术,可以以*的带宽实现小芯片互连,而无需硅中介层。
可见,NuLink通过简化系统设计降低了系统成本。更重要的是,Eliyan可以增加芯片之间的距离,对于生成式AI,NuLink为每个ASIC提供更多的HBM内存,从而提高了配备HBM的GPU和ASIC的内存密集型应用程序的性能。
Eliyan最近还展示了其NuLink PHY的*个工作芯片,该芯片采用5nm标准制造工艺实现,可以让Chiplet与不同工艺的裸片实现混搭,不需要硅中介层等先进封装技术。
该芯片符合现有的UCIe规范,并且能够超越当前规范的范围,以40Gbps的速度运行,在标准有机封装上以130um节距提供超过 2.2Tbps/mm的带宽,同时满足严格的功耗和面积要求目标。高面积效率的NuLink PHY受到凸块限制,一旦在可用的标准封装技术上以更精细的凸块间距实现,利用其创新的干扰消除技术,可以提供高达3Tbps/mm的传输速度。
Eliyan CEO Farjadrad指出:“如今业内的一大需求是能够获得足够大的中介层,这样就可以构建越来越大的GPU或TPU,并带有大内存。”
有业内人士表示,硅中介层的*尺寸约为3300mm2,考虑到处理技术的尺寸限制,现在每个SoC只能使用6个HBM3块。而Nulink有机基板的尺寸可以达到原来的三四倍,同时提供相同或更好的功率效率和带宽。这导致成本更低、制造速度更快,每个封装的计算能力更强。
例如,NVIDIA可以提供具有40GB和80GB HBM两种型号的A100 GPU,并表明较大的内存可提供3倍的性能优势。利用NuLink可将HBM数量增加两倍,达到160GB。假设AI训练中的内存优势呈线性扩展,采用NuLink的性能将再次提高三倍。
与此同时,NuLink还为HBM DRAM提供*的散热性能,消除了HBM-ASIC之间的热串扰,允许ASIC时钟速度提高20%,以及更简单/低成本的冷却。
总结来看, Eliyan消除了对先进封装的需求,例如小芯片设计中的硅中介层尺寸有限、成品率低、成本高、难以冷却、供应链有限等所有相关限制和复杂性。NuLink技术能够实现DRAM扩展、节约材料成本、提高产量并缩短芯片上市时间等优势。
Eliyan认为,其小芯片互连产品可以超越英特尔和台积电等芯片巨头的先进封装技术,或者有望成为英特尔、台积电的*选择,从而实现下一波高性能芯片架构。NVIDIA、Intel、AMD和Google等公司可以授权NuLink IP,或从Eliyan购买NuGear小芯片,以消除硅中介层尺寸限制带来的性能瓶颈,使他们能够实现更高性能的AI和HPC SoC。
目前Eliyan已从英特尔投资和美光资本等投资者那里筹集了4000万美元的A轮融资,用于开发和提高NuLink芯片间互连技术的产量。
北极雄芯对于Eliyan的创新技术表示认同,从大趋势来说,这个技术是很直观且正确的方向之一,由于带宽=线数×线速,当线的速率较高时,就可以减少对互连线密度的需求,从而可以从2.5D的封装要求切换到2D上。北极雄芯的D2D互连也是这样的出发点。
但马恺声也强调:“针对Eliyan的方案也还是有额外的考虑。HBM传统是下图的方式:基于HBM PHY,然后在Interposer上与HBM Stack互连,互连具体位置在HBM Stack底部的一颗Base Die,上面有HBM PHY与SoC芯片的PHY互连。由于互连线数多达1024根线,所以在HBM方案诞生时就采用Interposer 2.5D的封装来提供40μm级别的互连密度。而当采用2D封装,必然需要增大线速来换取更低的线密度需求。但速率的增加对于PHY的设计会引入显著的额外延时和能耗。”
因此,Eliyan的方案是维持了带宽的性能,但是牺牲了HBM低延时、低能耗的优势。此外,它这种方式需要重新设计HBM的Base Die,这对于方案的推广也是存在难题。
综合来看,无论是哪种互联技术,都各有优劣,都需要根据实际需求来进行设计和选择。因为在实际应用领域中,不同场景的数据传输特点带来对所采用接口技术及封装技术的较大需求差异。例如:
CPU等通用计算场景中,数据传输具有随机性高、数据流结构差异大、缓存一致性要求高等特点,因此在CPU Chiplet集成中往往极为重视对延迟等指标的优化,采用并口传输方案,大规模走线较为依赖先进封装技术的配套支持。
在GPGPU等面向服务器领域的通用并行计算场景中,数据传输具有单次量大、数据流结构可预知性高、可提前搬运预载等特点,因此在Chiplet集成中需要重点对带宽等指标进行优化,可采用并口或串口方案,对先进封装亦有较高的依赖。
而在特定AI加速场景中,又需综合考虑成本敏感度、作业环境等各方面要求,采用不同的接口技术及封装方案以满足终端用户的差异化的需求:如以智能驾驶领域为例,先进封装方案往往并不满足车规要求,而且量产成本也较高,在采用Chiplet异构集成时往往需考虑在成熟封装方案基础上反过来优化相应的D2D技术。
马恺声强调,Chiplet互联技术应当基于场景需求及供应链成熟度去不断迭代升级,并不一定是追求一个大一统的标准。Chiplet发展的过程中,产业里面会有不同的公司从芯粒设计、标准开发、封装技术等角度参与进来,最终需要真正解决下游商业痛点问题,又能兼顾性能、成本等各方面因素,自然就成为了行业标准。
而在这个过程中,也给国内企业带来了新的发展机遇,近年来也有厂商在此展开动作。
比如:芯动科技推出了国产自主标准的INNOLINK Chiplet IP和HBM2E等高性能计算平台技术,支持高性能CPU/GPUINPU芯片和服务器;为了让IP更具象、更灵活的被应用在Chiplet里面,芯原提出了IP as a Chip (laaC) 的理念,旨在以Chiplet实现特殊功能IP从软到硬的"即插即用”,降低较大规模芯片的设计时间和风险。
此外,早在2020年北极雄芯即与国内上下游共同发起了“中国Chiplet产业联盟”,联盟在2023年初推出了基于国产封装供应链优化的《芯粒互联接口标准》,旨在为GPU、AI、大型SoC等高性能异构集成芯片提供高性能、低成本的互联方案,目前*接口已经回片测试成功。
对于国内企业应该如何更好地参与Chiplet产业生态,北极雄芯认为,国内企业应基于国内较大的市场需求,立足于“自主可控”供应链的Chiplet商业落地模式更加符合现实客观环境。在产业上下游共同推动国内Chiplet产业生态的建立,而在这个链条中Chiplet芯片设计公司的作用至关重要。设计公司最贴近下游客户的需求,能够综合考虑下游场景的性能、功耗、成本敏感度等因素,准确的定义各类“芯粒”产品,从而反过来与上游IP厂商、晶圆厂商、封装厂商、基板厂商共同推动供应链迭代升级,实现“自主可控”的国内Chiplet产业生态,更具有现实意义。
结语
据Gartner数据统计,基于Chiplet的半导体器件销售收入在2020年仅为33亿美元, 2022年已超过100亿美元,预计2023年将超过250亿美元,2024年将达到505亿美元,复合年增长率高达98%,市场空间巨大。
基于Chiplet的异构集成芯片技术代表了“后摩尔时代”复杂芯片设计的研制方向。Chiplet这种将芯片性能与工艺制程相对解耦的技术为集成电路技术的发展开辟了一个新的发展路径。
但作为一种新兴技术,Chiplet当前正处于发展阶段,能否成为一种新的IP产品和商业模式,甚至拯救摩尔定律的救星,关键就在于业界能否达成统一的Chiplet互联标准,建立起来一个开放和标准化的Chiplet生态。
在这个过程中,中国Chiplet学术界和产业界应抓住机会,在技术研发和标准制定方面加大投入,尽快掌握核心技术。此外,芯片行业参与者需要避免单打独斗,应注重生态建设,早日建立业界接受的基于Chiplet的异构集成技术标准,以便在未来国际竞争中占据一席之地。
【本文由投资界合作伙伴微信公众号:半导体行业观察授权发布,本平台仅提供信息存储服务。】如有任何疑问,请联系(editor@zero2ipo.com.cn)投资界处理。




