
细菌、真菌、植物和动物产生各种专门的代谢物,也被称为天然产物,它们在复杂的生物间相互作用中起着至关重要的作用。
这些天然产物是药物研发的重要源泉,在历史上作为抗生素、化疗药物、免疫抑制剂和作物保护剂的应用取得了巨大的成功。
由于组合化学和高通量筛选技术的兴起,制药行业天然产物发现项目的受欢迎程度有所下降,但最近,大规模组学数据的可用性促进了这一复兴,使人们能够更深入地了解生物圈中隐藏的化学宝库。
在研究天然产物的领域,人工智能方法正在被开发,以已知生物合成途径及其化学产物的数据为基础,仅根据DNA序列预测BGC(生物合成基因簇)产物的化学结构,这些数据日益标准化并存储在公共数据库中。
因此,基于组学的天然产物发现和计算药物设计领域之间有巨大的潜力,已经有公司在这个交叉领域创业,例如Enveda Biosciences,利用生物圈的巨大化学多样性开发新药。(拓展阅读:)
1、人工智能在天然产物研究中的应用
天然产物基因组和代谢组挖掘
目前已经开发了几种人工智能技术,分别通过序列或光谱数据预测生物合成基因和代谢物结构来加速天然产物的发现。
尽管这些方法在检测已知的生物合成基因簇 (BGC)方面是成功的,但它们在识别新的BGC类型或非聚类途径方面不太熟练。在这些更复杂的情况下,机器学习算法已被证明比基于规则的方法具有显著的优势。
例如,ClusterFinder,深度学习方法DeepBGC, GECCO和SanntiS等,都使用深度学习或支持向量机来识别未使用基于规范规则的注释方法捕获的bgc。
基因组挖掘算法可以挖掘生物合成的潜力,而代谢组学允许直接检测生物合成成分,即使它们的精确结构是未知的。应该开发将基因组挖掘的BGC和基因簇家族与非靶向代谢组挖掘的光谱和预测的分子类别联系起来的人工智能算法。
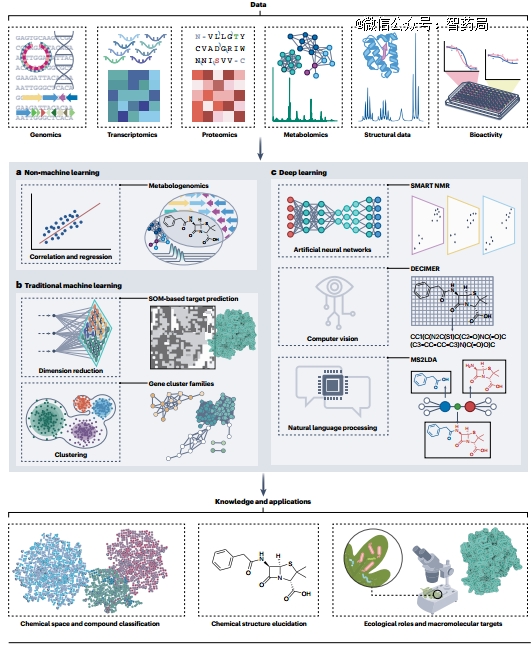
图:人工智能在天然产物和药物发现中的应用
天然产物的结构表征
成功的天然产物药物发现研究需要能够明确地解离化合物的结构。由于自然界中存在的代谢物的化学复杂性,这项任务具有挑战性。结构解析需要收集、分析和编译多种数据类型,通过方法、仪器和计算手段,如基于量子化学的理论计算和基于人工智能的MS和NMR数据结构预测,人们已经做出了重大努力来改善天然产物的结构表征。
同样,人工智能也被用于增强基于核磁共振的结构解析和注释。计算机辅助结构解析(CASE)程序通过生成基于概率的核磁共振数据集所有可能结构的排序来减少错误的结构分配,可以指导结构的确定。
预测靶标和生物活性
药物发现是对天然产物的大分子靶点、相关生物活性和可能毒性的预测。对这些特征的准确预测将为化学空间的哪些领域最有希望发现药物提供直接线索。这将是基因组挖掘潜在成功的关键,目前的结果是候选bgc列表太大,很少有战略可用于针对具有实际制药潜力的天然产物空间的部分。人工智能技术与其他技术相结合,可以帮助解决这一挑战。
天然产物靶标解析
由于缺乏对其靶点的了解,新的天然产物被选为候选药物的进展往往受到阻碍,这阻碍了它们的临床前测试和合理优化。
鉴于代谢物分离和处理的复杂性,由于成本和工作量的原因,对这些分子的作用机制进行大规模实验测定是不可行的。因此,从分子结构中快速预测最可能目标的计算模型是一个活跃的研究领域。几乎所有的计算药物发现方法都已成功地应用于阐明天然产物的靶标,包括对接、聚类、生物活性指纹、药物载体和机器学习。
在某些情况下,这也使人们对已经在临床试验中的天然产物的作用机制有了新的认识。尽管适用性目前有限,但鉴于这一成功和先进机器学习模型的准确性不断提高,预计该领域的进一步发展将导致量身定制和进一步改进的模型。

图:从基因组、代谢组学和表型数据预测生物活性和靶点
经典化学信息学和基于药物团的生物活性预测
依靠使用经典化学信息学和计算机辅助药物发现工具来预测天然产物生物活性的方法是丰富的。
考虑到天然产物的不同化学结构和物理化学性质,最成功的应用使用额外的预处理步骤或依赖于对天然产物和合成化合物的训练数据之间的化学差异进行描述和表示。例如,基于自组织图的SPiDER方法专门用于预测分子的生物活性,并已成功地应用于预测大环天然产物和片段状天然产物的生物活性。
生物活性预测的其他成功应用已经使用了表征,如生物活性特征的3D药效团匹配与深度神经网络相结合。这样的模型无需直接使用经典的化学指纹图谱就能捕获分子的基本特性,并且能够预测合成化合物halicin和abaucin的杀菌活性。
分子动力学模拟和基于结构的生物活性预测
基于结构的方法利用蛋白质靶标的空间信息来预测化合物的结合模式。这些信息可以通过实验确定的结构(例如x射线晶体学)或基于深度学习的建模方法(如AlphaFold67) 获得。然后,通过分子动力学方法计算蛋白质动力学的分子对接等策略,可以列举潜在的结合模式。
例如,FEP方法的适用性和使用最近在学术和工业药物发现项目中大大增加了。分子对接、分子动力学和FEP可以扩展到天然产物的亲和性研究。
基于序列或bgc的生物活性预测
越来越多的方法被用于预测生物活性,这些方法基于来自bgc的DNA和/或蛋白质序列数据,并使用机器学习算法。
利用现有小分子知识的一种方法是预测BGC的最终产物,并直接从预测中推断其活性,例如PRISM。这种方法的一个问题是在预测结构预测不佳的bgc的活性时面临的挑战,在最终预测中即使是很小的错误也可能导致实际化合物的活性大不相同。
生物活性预测的替代方法借鉴了自然语言处理(NLP)领域。例如word2vec和Deep-BGCpred。
值得注意的是,挖掘工具预测的BGC序列边界并不精确,经常遗漏部分BGC或与其他BGC融合在一起。为了使用BGC序列数据作为机器学习的输入,通常需要专家手动更新BGC边界。因此,BGC预测的改进对于这种生物活性预测方法至关重要,并且仍然是需要进一步研究的领域。
基于自我抵抗、调节或进化特征的生物活性预测
人们早就知道细菌含有抗性基因,使它们能够抵抗它们自己产生的抗生素天然产物的作用。目前有许多抗生素耐药性决定因素数据库,如综合抗生素耐药性数据库(CARD)、国家抗生素耐药生物数据库(NDARO)和ResFinder。为了利用抗性信息,已经创建了各种算法,试图将这些抗性基因与bgc联系起来。
虽然bgc预测可能产生何种代谢物,但可以利用调节网络来估计bgc是如何被控制的,特别是对哪些信号作出反应。这些信息可以作为信标,找到特定目的(如对压力或疾病的反应)所需的bgc或代谢物。例如,这可以用来预测哪些基因簇在互惠微生物中表达以应对病原体入侵,这可能有助于优先考虑bgc用于抗生素的发现。
2、新兴人工智能方法
在上述所有应用领域,人工智能技术仍处于起步阶段,缺乏(高质量)标准化数据。
目前业内已经着手建立高质量数据集,因此未来人工智能方法准确性的重大改进是可以实现的。基于这种趋势,未来人工智能的新兴方法可能为该领域带来巨大的发展。
分子表征方法
能够多大程度上简洁地捕获分子数据的重要信息,对于机器学习算法的成功至关重要。
圆形指纹图谱能够最准确地鉴定结构相关的天然产物,然而,对于从天然产物到合成模拟物的支架跳跃,圆形指纹被发现不如基于药物团的描述符有用。因此未来需要创建更好的分子表征方式。
深度学习
天然产物研究方面,最近受到相当关注和应用的一种机器学习技术是深度学习。
深度学习的应用包括分子图神经网络方法:例如,用于预测药物靶点结合亲和力,基于smile的新药物样分子生成方法,基于图的新分子生成方法,性质预测方法和基于表面网格的蛋白质口袋条件分子表示方法。
过去几年最著名的深度学习方法之一是AlphaFold67,它可以通过学习蛋白质数据库的整个语料库,从蛋白质的初级氨基酸序列预测蛋白质的三维结构。
对于天然产物研究,结构预测是高度相关的,因为它能够帮助预测天然产物生物合成酶家族的底物特异性或帮助预测通过靶向修饰的耐药性进化。AlphaFold开创的先例表明,深度学习有可能解决天然产物计算研究中长期存在的问题,尽管目前天然产物数据要少得多。由于自然产物计算研究的深度学习仍处于起步阶段,因此应谨慎对待其预测。
解决数据限制的方法
在天然产品研究中,深度学习面临的*挑战之一是对大型精选数据集的开放访问。深度学习等“数据饥渴型”算法只有在训练数据集足以支持模型复杂性的情况下才能提高性能。
减少有效所需数据点数量的一个解决方案是在较大的化学数据集上使用预训练模型的权重。使用预先验证和预先训练的化学模型,如ChemBERTa或MoleculeNet,可以减少从头开始训练新模型所需的计算量。在许多情况下,预训练的模型也会产生更高的预测精度。
虽然深度学习技术可以克服不完整样本标记和小数据集的问题,但半监督学习(将标记数据与未标记数据结合)可以帮助在不完整标记的数据集上学习。
另一种选择是迁移学习。在这种策略中,从大量数据集中学习的任务中的知识可以转移到可用数据较少的相关任务中。这可以提高模型效率,并缓解与低数据相关的问题。
另外主动学习技术,通过实验指导选择未标记的数据进行标记,也可以在标记训练数据有限的情况下使用。这已经成功地应用于识别抑制抗癌靶CXC趋化因子受体4与其配体之间蛋白-蛋白相互作用的小分子,通过主动检索信息丰富的活性化合物,不断改进自适应结构-活性模型。
在主动学习被广泛应用之前,仍然存在许多实际挑战,其中许多挑战围绕着标准化实验数据采集的时间要求和成本。这也许可以解释为什么主动学习尚未广泛应用于自然产物研究,因为实验通常很复杂。随着实验分辨率和自动化程度的提高,主动学习将在未来的天然产物研究中发挥核心作用。
3、总结与展望
综上所述,人工智能在天然产物药物发现方面的进展主要受到缺乏大型、高质量数据集的限制,而不是缺乏创新的算法。
不要仅仅因为“炒作”因素而使用新算法,而是仔细考虑哪种算法最适合现有数据的类型和数量;例如,天然产品数据集通常比一般的计算机视觉相关数据集小得多,这可能意味着具有较少参数的简单模型可能更成功。
因此,对于未来人工智能的发展,为对数据库维护和持续支持应该是国际和国家资助机构的优先事项。由于与天然产物研究相关的大量数据类型,单一的整体存储库不太可能满足天然产物社区的需求。相反,专注于天然产物数据不同方面(如结构、bgc、光谱数据和生物活动)的专门存储库必须专注于提高互操作性,以开发分布式数据资源网络。
最后,全球科学界的集体资源远远超过任何一个实验室的能力。如果有适当的激励措施和指导方针,社区生成和策划的数据集可以具有巨大的潜力,推动人工智能驱动的天然产物药物发现领域。
【本文由投资界合作伙伴微信公众号:智药局授权发布,本平台仅提供信息存储服务。】如有任何疑问,请联系(editor@zero2ipo.com.cn)投资界处理。




