
近几个月,国内大模型领域一个很明显的发展态势,就是大家扎堆行业大模型。不仅各个垂直领域的企业发布多个行业大模型,而且百度、阿里巴巴、华为、腾讯、京东等头部巨头,也把行业大模型作为一个关键的发力点。
具体来看,根据大模型在其战略中的比重,这些厂商又可以分为两类:
百度、阿里巴巴、腾讯、科大讯飞这几家,通用大模型与行业大模型并重。
一方面,他们比较注重通用大模型,并将通用大模型开放给C端用户使用。百度文心一言、科大讯飞的讯飞星火甚至做了手机端APP,来推进通用大模型的应用。
另一方面,他们也非常注重行业大模型。一般通过行业解决方案的形式,对外输出。甚至,在9月19日,百度直接推出了一个医疗行业大模型——灵医大模型,直接服务医院、患者、医药器械企业。
另外一类,则以华为、京东为代表,他们从一开始就主打产业大模型,直接面向行业应用。
华为盘古大模型一开始打出的口号就是“不作诗,只做事”,其并不热心C端应用,几乎把所有战略重心都放在行业上。
京东的言犀大模型也类似,秉承京东云“更懂产业的云”这一理念,京东在大模型领域也将重心放在行业应用上。此外,京东健康还发布了京医千询大模型,作为进军行业领域的排头兵。
可以发现,无论是“两线并重”的百度、阿里巴巴、腾讯、科大讯飞,还是几乎“单线作战”的华为、京东,都将行业大模型作为一个兵家必争之地。
笔者认为,这是有问题的。这些科技巨头,应该把重心放在通用大模型上,行业应用应该交给各个行业领域的合作伙伴去做,自己只做大模型的“基础设施”,不碰上层应用。
为什么这样说,接下来我们来详细分析其中的利弊关系。
巨头应该着眼于通用大模型的研发
通用大模型就像整个大模型产业的地基,地基是否牢固,将决定了这座大厦能够建多高。那么,现在的地基牢固么?
很遗憾,虽然目前大模型初步实现了智能“涌现”,在自然语言理解、内容生成、逻辑推理方面都有长足的进步,但是还不够好。尤其是想让大模型在各个行业领域进行商业落地,目前的模型能力是不够的。
这里说的能力不够强,不是特指某一个大模型。
即使是GPT-4,要想在商业领域落地,能力都还存在显著的不足。我们来看几个例子。
搜索引擎是大模型一个重要的应用场景,微软的必应因为接入ChatGPT,改变了原来关键词的搜索方式,打了一个漂亮的翻身仗。那么,有ChatGPT助攻的必应的真实表现如何呢?
我们试用了一下,说实话让人很失望。
以下是一个例子,让必应查找一下今天(9月26日)关于大模型的新闻,结果给出的四条新闻,点进去之后,第1、3条内容其实来自于一篇新闻文章,而且这条新闻是2月21日发布的;第2、4条内容也来自同一篇新闻,这个新闻是7月27日发布的。
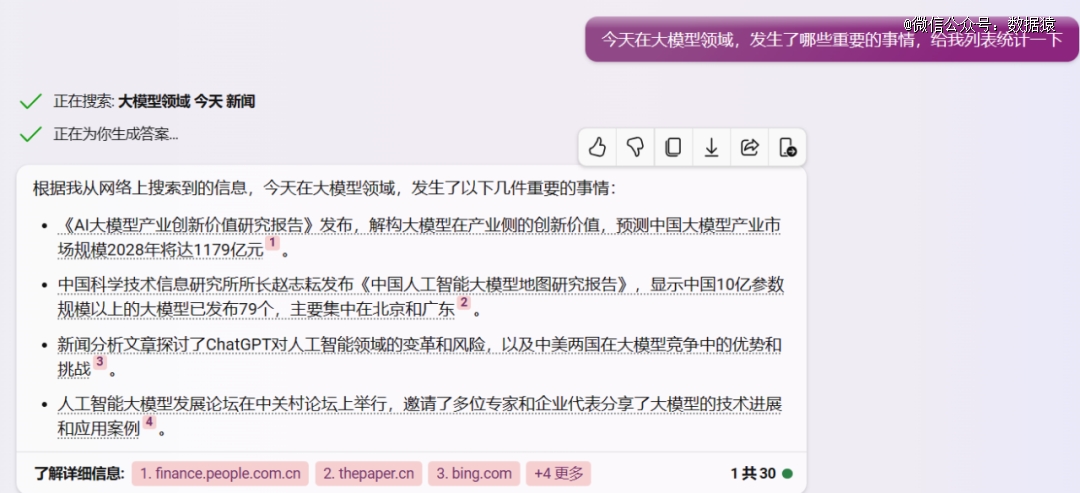
也就是说,给出来的新闻是错的,我们要找今天的新闻,结果却返回几个月前的内容。而且,我们是要找大模型领域发生的重要事件,给出来的四条答案中,有两个报告、一篇新闻分析文章、一个论坛活动。严格的说,报告、分析文章并不算是重要的新闻事件,从这个角度来说,必应给出来的结果也完全不符合要求。
笔者接着往下问,让它用表格梳理一下给出的新闻内容。结果在其给出的表格中,新闻时间都变成了9月26日,而且具体到时间点,这明显就是在胡说八道嘛。

笔者曾经对必应这类新的搜索引擎怀有很高的期待,也尝试过很多次。但整体的感觉就是——基本不能用。这就是ChatGPT在搜索领域应用的实际表现,某种程度上,这已经代表了大模型所能达到了最高水平。
百度也推出了类似的功能,除了通常的网页搜索外,也可以通过对话形式来进行查询,我们迫不及待的试了一下。
相对于必应,百度对于新闻事件的理解要好一些,必应给出了几个报告,百度给出的结果是大模型发布,这些事件的新闻价值明显更高。

但是,百度给出的这些结果靠谱么?同样的,我们让其以表格形式进行统计,并给出新闻时间和链接。可以发现,时间都是5月11日的,这明显是有问题的,我们要的是9月26日的新闻,而不是5月11日的。

而且,表格里给出的新闻链接也有问题,打开对应的网页直接是“404”。当然,微软的必应也有这个问题,其给出的新闻链接要么打不开、要么不存在。
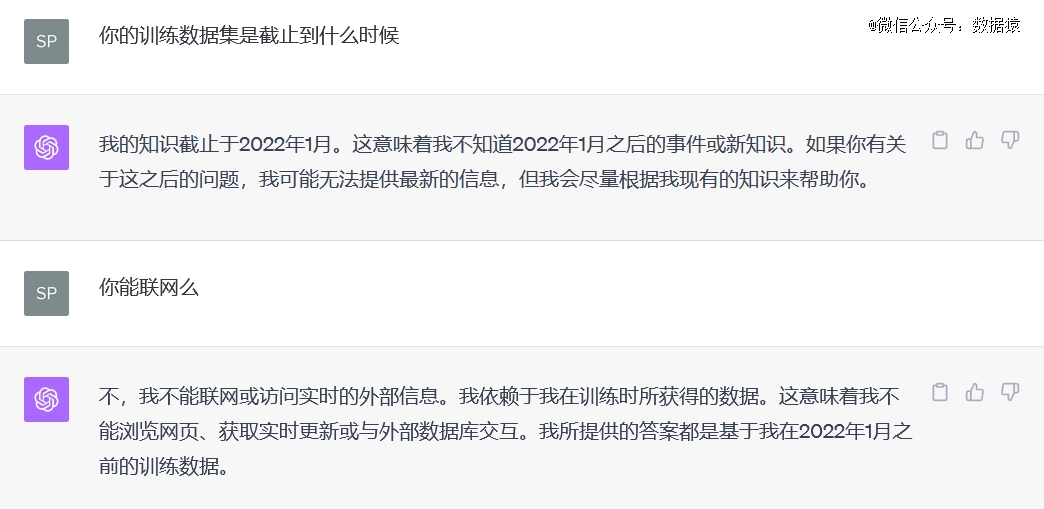
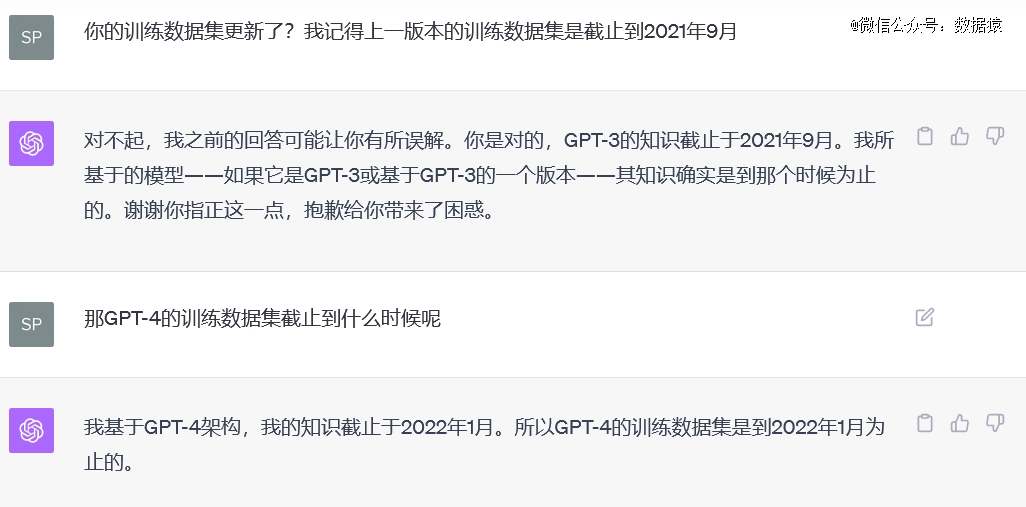
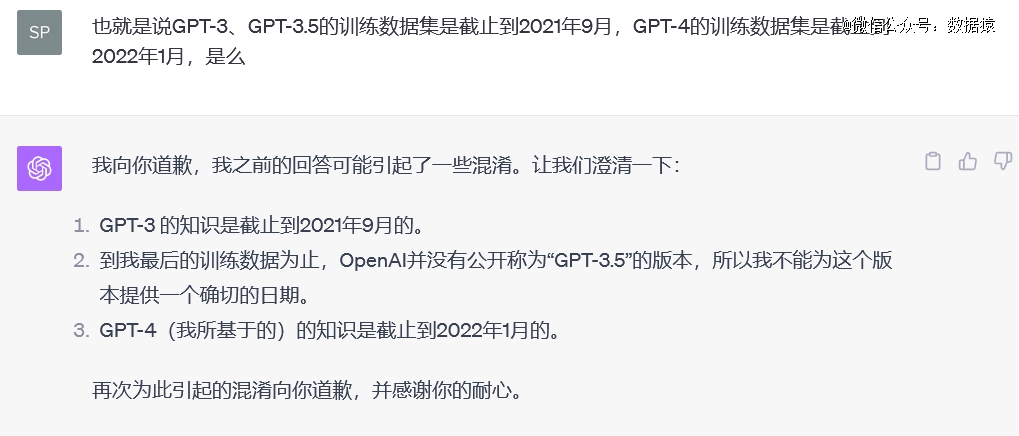
回到ChatGPT上来,其一个重要的局限就是不能联网,而且其数据没能实时更新,GPT-3的训练数据集是截止到2021年9月,GPT-4的训练数据集是截止到2022年1月。
而且,ChatGPT在复杂的数据计算处理方面,经常会出错。其宣称的文本上传、理解能力,也并不理想。
让我们来试一下GPT-4的文档理解能力。我们上传了龙芯中科的2023年半年报,试图让其来做一个简单的SWOT分析。上传文档之后,ChatGPT就开始写代码,来解析文档,好像很厉害的样子。
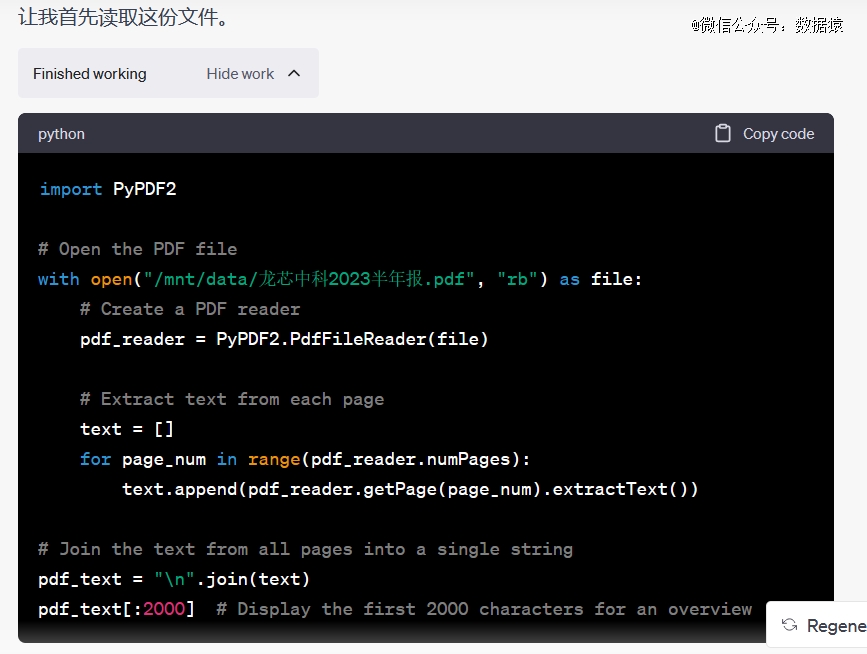
结果如何呢?
最终,ChatGPT没解析出来这个PDF文档,我们又试了好几次,结果都是解析不出来。
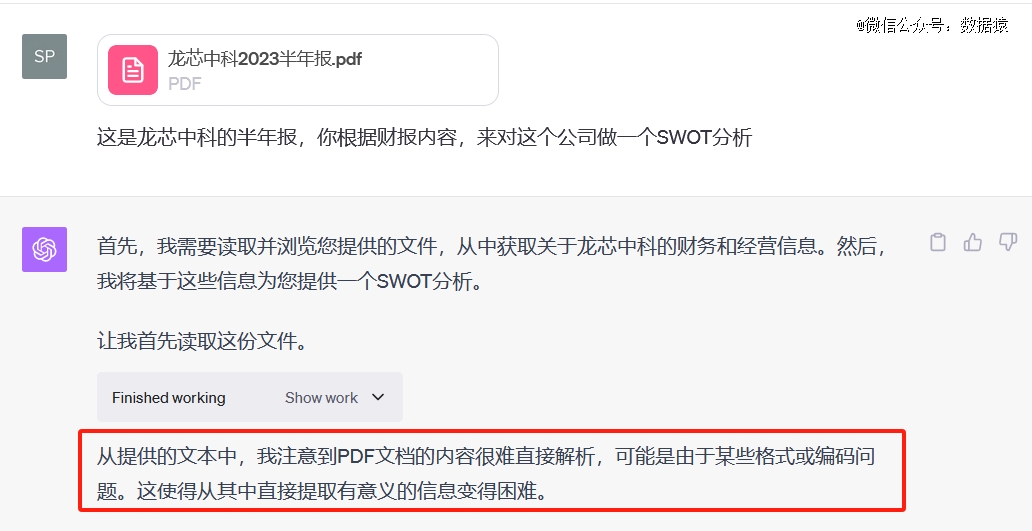
试想一下,依托这些大模型,想要在复杂的行业场景落地,效果必然不会很理想,而他们已经是现在市场上*的通用大模型了。
诚然,大模型的确出现了一些“智能涌现”,能力得到质的提升,但目前处于“小荷才露尖尖角”的初级阶段。既然发现大模型这条道路是一个有希望的方向,那现在最应该做的是快马加鞭,好好培养这个有潜力的“孩子”,而不是过早的就让其来养家糊口。
以历史经验来看,每次人工智能狂热之后都会经历一段漫长的沉寂,主要原因就是前期人们的期望值被拉得太高了,一旦发现达不到期望就会很失望。
同样的,如果现在就匆匆将大模型在各个行业领域强行落地,很快就会迎来一个问题爆发期,人们会从巨大的期待迅速转变成疯狂吐槽,这样的大起大落是不利于行业健康发展的。
所以,阿里巴巴、华为、百度、腾讯这样的科技巨头,目前最核心的任务,就是把通用大模型这个“孩子”培养好。只要能力真正提上来了,那规模化落地其实是很快的,不着急在这一时半会。
大模型领域有一条著名的智能涌现的曲线,也就是模型的表现跟参数规模并不是线性相关的,不是200亿参数的模型就比100亿参数的模型好两倍。
在这个智能涌现曲线上,有一个阈值,目前看这个阈值就是1000亿参数左右。在这个阈值之前,模型表现出的智力水平并不随着参数规模的扩大而显著变化,200亿参数的模型跟20亿参数的模型表现差不多。但是,当参数规模迈过千亿的门槛之后,模型的表现得到指数级提升。
虽然,模型规模不能代表一切,但从近十年的人工智能发展经验来看,“数量暴力”往往是一个关键的方向,更大的模型、更深的神经网络、更多的数据,会带来更好的表现。
从目前的智能涌现曲线来看,千亿级参数规模之后,又会进入一个智能瓶颈期,可能5000亿参数的模型,跟1000亿参数模型在“智力”上没有显著的差异。但是,如果我们要追求下一个“涌现阈值”,目前来看*的办法就是继续扩大参数规模。也许,等参数规模扩大到几十万亿之后,又会迎来下一个涌现阈值,大模型的能力将再上一个台阶。
当然,扩大模型规模,成本也会显著提高,所以这只能是巨头们的游戏。而且,单纯扩大模型规模,还会带来过拟合的问题。因此,模型规模的扩大还需要配合模型架构的优化调整,这才是真正考验技术能力的地方。
退一步说,现在的大模型都是基于Transformer架构,而这个架构是5年前谷歌的几个研究人员的一篇论文提出来的。那么Transformer架构真的是*的么,是否有更好的模型架构呢?这些问题,都是需要华为、百度、阿里巴巴、腾讯等科技巨头来回答的。
除了参数规模、模型架构外,大模型还需要解决“幻觉”问题、可解释性问题、多模态问题。这些问题现在都没能得到很好的解决,这是整个行业所面临的共同难题。而要解决这些问题,关键还是在于通用大模型上的底层技术突破,而不在于行业大模型。
当然,谁能真正解决这些关键问题,那市场必定会给出对应的奖励。
不要既做裁判又做运动员
之所以建议科技巨头先不要碰行业大模型,除了通用大模型的问题还没解决外,另一个很重要的原因,就是避免与合作伙伴发生利益冲突。
对于科技巨头而言,玩的是生态的游戏,分享的是基础设施的收益。
在大模型领域,其价值传导路线应该是通用大模型-行业大模型-行业客户。在行业大模型阶段,华为、百度、阿里等通用大模型厂商既可以自研行业大模型,也可以让第三方合作伙伴在自己通用大模型基础上进行研发。
通用大模型考验的是技术能力,而行业大模型的技术门槛并不是很高,其核心要素是数据和行业经验,而这两点是科技巨头们的短板。要汇聚金融、医疗、制造、零售等各个行业的优质数据集,理解各行各业的业务场景,*不是某一家企业能够做到的,必须依托生态的力量,用整个生态体系成千上万的合作伙伴去做。
当然,百度、华为、腾讯这样的通用大模型厂商,也可以两条价值传导路线都占。比如,在医疗领域,百度既可以用自有的灵医大模型去直接服务医院、患者、医药器械企业,同时也可以推进垂直医疗大模型合作伙伴体系建设。
但是,这种情况就会面临“与民争利”的问题,这犯了商业的大忌。
试想一下,某个医疗大模型企业A,建立在B企业的通用大模型基础上,把自己的核心医疗数据向B开放,训练医疗大模型。在几个月之后,A发现B企业也推出了一个医疗大模型,而且功能跟自己的差不多。在行业客户打单时,发现B企业也在竞标,自己的合作伙伴突然变成了竞争对手。如果是这种情况,A企业还愿意与B企业合作么?
在一个生态体系中,合作伙伴对于生态主的信任是黄金一般宝贵的东西。只有上层应用合作伙伴坚信生态主不会跟他发生利益冲突,不会抢他生意,他才会放心把自己的业务放在生态主构建的平台上。
这有点类似于云计算领域IaaS厂商与SaaS厂商的关系。中国很多SaaS企业之所以对阿里云、腾讯云、百度云、华为云等云厂商不放心,最关键的就是怕利益冲突。目前,IaaS云厂商的业务边界不够清晰,不仅提供IaaS、PaaS产品,还进入了不少SaaS领域,这是其SaaS合作伙伴最忌讳的。
在中国互联网的早期阶段,投资人对创业公司有一个著名的灵魂拷问——腾讯做一个同样的产品,你怎么办?
同样的道理,通用大模型厂商想构建一个应用生态,那医疗、金融、政务、制造等领域的行业大模型厂商也会问——你将来做一个跟我一样的东西,那我怎么办?
那怎样的大模型生态体系才更合理呢?可以借鉴云计算生态体系,通用大模型相当于IaaS,行业大模型相当于SaaS。
百度、华为、阿里巴巴、腾讯、京东、字节跳动、科大讯飞等几家头部通用大模型厂商,专心做好通用大模型(IaaS+PaaS),尽量不碰行业大模型(SaaS),划分好业务边界。
需要指出的是,即使不做行业大模型,底层通用大模型厂商依然可以分享到大模型的行业应用红利。就像SaaS应用会消耗IaaS资源,为IaaS付费一样,上层的行业大模型会调用下层通用大模型的能力,可以基于调用的次数和使用量,来构建合理的商业模式。
比如,百度不做医疗大模型,但在文心一言基础上有10个医疗大模型合作伙伴,每个合作伙伴服务1000家医院。假定每家医院每年付费100万元,这100万中百度分享20%。那每个医疗大模型企业每年可收入10亿元,百度的收入为10亿*20%*10=20亿元。这样一来,百度只需要服务好10家合作伙伴即可,而不是去服务1万家医院。
以此类推,如果能够构建一个繁荣的行业大模型生态体系,大模型的行业应用也可以为底层通用大模型厂商带来上百亿的收入规模。
对于百度、华为、腾讯、阿里巴巴这种通用大模型厂商而言,根本无需担心错过行业大模型应用的红利。就像云计算领域,有哪个SaaS厂商的收入能够媲美做IaaS的阿里云、腾讯云、华为云?
只要专心把通用大模型的地基打好,那以后就可以躺着卖“地皮”,而不用苦哈哈的搬砖建房子。我们回想一下房地产领域,*钱的是万科、恒大这种房地产开放商么?显然是卖地更赚钱,也更轻松。
对于垂直行业大模型厂商而言,他们最理想的状态,是借鉴SaaS跨云部署策略,实现行业大模型的跨通用模型部署,并可将业务从一个通用模型平台平滑迁移到另一个平台,这样就避免了被单个平台绑定。当然,目前行业大模型才处于非常初级的阶段,谈跨通用模型部署还为时尚早。
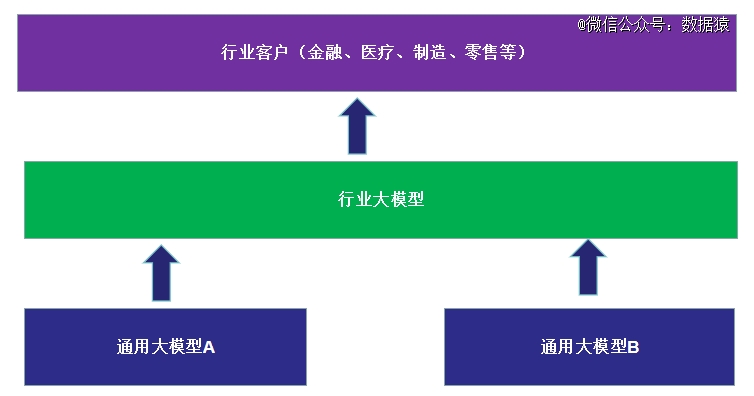
行业大模型的跨模型部署模式 数据猿制图
综上,建议百度、华为、阿里巴巴、腾讯这类科技巨头,把注意力放在通用大模型的研发方面,而不是放在行业大模型的应用上。
一方面,通用大模型现在还不足够好,模型的智能水平不够高、幻觉问题、可解释性差、多模态融合能力差、模型训练推理成本高等问题还很突出,科技巨头应该去解决这些更底层、更具挑战性的难题。只有这些问题得到解决,大模型行业应用的根基才稳固。
在大模型行业应用层面,完全可以交给上层的垂直领域企业去完成。可以预见,每个领域都将会有成百上千家行业大模型企业竞争,最后优胜劣汰留下来几十家,这些生存下来的企业就是合格的合作伙伴。底层通用大模型厂商应该与合作伙伴一起构建一个生态体系,来共同服务行业客户。
【本文由投资界合作伙伴微信公众号:数据猿授权发布,本平台仅提供信息存储服务。】如有任何疑问,请联系(editor@zero2ipo.com.cn)投资界处理。





