
大模型热度持续提升,不仅企业推出数十个大模型,数据猿注意到多个高校也在陆续推出大模型。那么,高校研发大模型的出发点是什么呢,他们的做法跟企业又有什么不一样?本篇文章致力于搞清楚这个问题。
01 大模型的竞赛,高校是一个重量级选手
在中国市场,企业界目前已经推出了上百个大模型产品。然而,在这场竞赛中,有一个别样的参赛选手容易被忽视——高等院校。
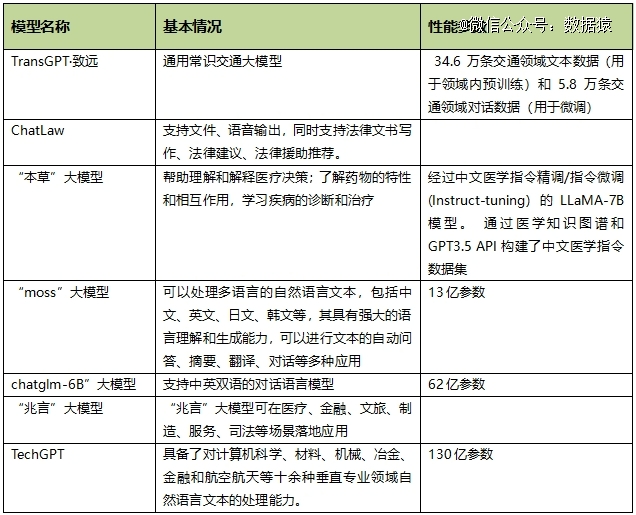
事实上,中国已经有多个学校陆续推出了自己的大模型。北京交通大学与中国计算机学会智慧交通分会以及足智多模公司合作,发布并开源了国内*综合交通领域的大型模型,命名为TransGPT·致远。这一模型的推出为智能交通领域的研究和应用提供了有力支持。
北京大学推出了ChatLaw大模型,哈尔滨工业大学发布了“本草”大模型,复旦大学的“moss”大模型也在研究领域取得了突出成就。清华大学的“chatglm-6B”大模型、上海交通大学研发的“兆言”大模型以及东北大学的“TechGPT”等等,都是国内大学在大型模型研究方面的杰出代表。
这些国内大学的大型模型不仅在自然语言处理领域有重要应用,还为各个领域的研究和实践提供了有力工具。它们的开源和分享精神也有助于促进科学界和工业界的合作,推动了中国在大型模型研究领域的发展。
以下是对国内高校大模型进展的不完全统计:
近日,来自苏州大学的一个研发团队最近发布了一款名为OpenBA的开源seq2seq模型。OpenBA是一款具有150亿参数的双语非对称seq2seq模型,也是中国开源模型社区迎来的*大型语言模型变体。根据相关论文的介绍,研究人员采用了高效的技术,并采用了三阶段的训练策略,从零开始构建了OpenBA模型。
OpenBA模型的亮点有以下几点:
1、该模型为中文开源社区贡献了一个有代表性的编码器解码器大型语言模型。而且,该模型的训练过程,包括数据的收集与清洗、模型的构建与训练,都已完全开源,使其能够广泛地被研究和应用。
2、数据方面,OpenBA模型所使用的数据均是公开可获取的,这一特点增强了模型的透明度和可用性。
3、为了提升模型对中文指令的理解能力,研究团队基于开源的标注数据构建了大规模的中文Flan数据集,并完全开放了数据集的构建方法。
4、令人印象深刻的是,尽管OpenBA模型仅使用了380亿个标记的训练数据,但在多个中英文下游任务上表现出色,超越了许多参数量更大、数据量更多的模型。
02 同样的赛道,不一样的玩法
同样是做大模型,高校与企业相比,有什么不一样呢?
通过综合对比,我们发现,高校研发大模型技术产品,跟企业相比,在以下几个方面存在明显的区别:
1、目的不同,高校是为了出学术成果,而不是商业成果。
高校的研究主要追求学术探究,他们致力于探索大模型的理论基础、算法优化以及应用拓展,旨在推动学科发展。研究者追求的是发表高水平论文,提高学术声望,为学术界贡献新知。
相比之下,企业的目标是商业化应用,他们关注的是如何将大模型技术转化为具体的产品和服务,实现商业价值和盈利。
因此,在研发的深度上,高校可能更侧重于技术的原理和探讨,而企业更关心技术的实际应用和商业可行性。
这种目的的差异也影响着研究者的动力和方法,高校研究者通常追求创新和突破,他们可能会更加开放地探索各种可能性,包括不太成熟的或者风险较高的方向。
而企业研发团队则需要更加务实,他们要考虑市场需求、竞争态势,更倾向于在已有基础上进行改进和优化,以确保产品的可靠性和市场竞争力。
2、高校的理论研发能力强,但产品化能力弱。
很多高校拥有世界级的*科学家和研究团队,他们在前沿理论探索方面具备*的能力。这使得高校能够在大模型的算法设计、深度学习理论等方面取得*地位,甚至在某些领域超越企业界。然而,尽管拥有强大的研发能力,高校在产品化方面的能力相对较弱。
由于缺乏工程化和产品化的经验,高校团队开发的大模型往往难以直接转化为商业产品。产品化需要考虑诸多因素,包括稳定性、性能优化、用户友好性等,这些要求对工程团队的技能和经验提出了更高的要求,而这是高校研究团队所缺乏的。
3、资金实力较弱,算力不足,模型规模较小。
高校在大模型研发中普遍面临着资金实力较弱、算力不足的挑战,这限制了他们在模型规模上的发展。相较之下,企业通常拥有更充足的财力,能够投入大量资源进行研发,尤其是在高昂的算力需求方面。
大模型的训练需要庞大的数据集和超级计算机集群,这往往需要花费数以千万计的美元。然而,高校的研究预算相对有限,难以承担这样的高昂成本。
这种资金和算力的短缺使得高校往往只能开展规模较小的大模型研究,他们可能会聚焦于百亿参数规模以内的模型,而千亿参数规模以上的大模型则较为困难。这种限制影响了高校在大模型研究领域的深入探索,因为更大参数规模的模型往往能够更好地捕捉数据的复杂关系,具备更强的泛化能力。
4、高校的大模型产品具有浓厚的实验性质,后期持续迭代不足。
大模型的研发不是一次性任务,而是需要不断迭代和升级,以适应不断变化的需求和挑战。然而,由于高校研究项目通常以发表学术论文为主要目标,一旦论文发表,后期持续迭代模型的动力和资源支持就显得不足。这导致了许多高校推出的大模型往往只是昙花一现,缺乏持久的影响力和实际应用。
03 高校*的价值,在于其是理论探索的先锋队
既然高校有这么多缺陷,但为什么还要凑这个热闹呢?高校研发大模型到底有什么价值呢?难道就是为了研发团队发几篇论文?
在数据猿看来,虽然高校有多种缺陷,但在推进大模型发展方面,有其独特的价值。
首先,在大模型前沿理论探索方面,高校具有不可替代的重要地位。
大模型技术的发展正处于快速探索和创新的阶段,其中充满了未解之谜。例如,大模型的“幻觉”——模型在没有真实理解情况下“假装”理解的问题,这是一个需要深入探讨的理论难题;多模态融合则涉及将来自不同传感器或源头的数据进行融合,需要开发新的理论和算法以更好地处理这种复杂信息,这些理论难题都需要高校的前沿探索。
大模型的伦理安全研究也是一个备受关注的领域,高校可以通过深入的伦理研究,探讨大模型的应用边界、道德责任和社会影响,为未来的技术发展提供指导。
在前沿理论、技术探索方面,与企业相比,高校通常拥有丰富的学科背景和跨学科研究资源。大模型技术的发展不仅仅依赖于计算机科学,还需要涉及心理学、认知科学、生物学等多个领域的知识。高校研究者可以自由穿梭于不同学科领域,推动多领域知识的融合,为大模型的发展提供跨学科的理论支持。这种综合性的研究视角有助于拓展大模型技术的应用领域,推动科技的交叉创新。
此外,高校在学术研究中更容易进行高风险高回报的研究。大模型技术的发展充满了不确定性和挑战,探索新的理论和方法可能会面临失败的风险。而高校由于其学术性质,通常具有较高的学术自由度,可以承担更多的风险,去尝试那些可能具有革命性意义的理论突破,这种高风险的探索为大模型技术的未来发展带来了更多的创新可能性。
需要注意的是,高校与企业并不是完全割裂的,而是可以紧密合作。事实上,不少企业就在与高校联手进行大模型技术研发。而且,企业与高校在人才方面是相通的,经常有人才流动。比如,高校为企业源源不断的输送人才,是企业研发的重要后备力量。另一方面,企业高级人才也可能回到高校做研发、任教。这样的双向人才流动,将大大促进人才市场的活跃,而这是大模型理论和技术发展不可或缺的催化剂。
企业推出的大模型产品,往往具有排他性,甚至会申请专利保护。而高校的技术成果则具备更多的公共资源属性,一般会将成果向社会开放。一些小型团队,可以在高校研究成果的基础上,进一步产品化、商业化,这降低了他们创业的门槛。以美国硅谷的成功经验来看,高校的研究成果往往是创业团队的发源地。在高校实验室中,有一些隐藏的“金矿”,等待创业团队去挖掘。
【本文由投资界合作伙伴微信公众号:数据猿授权发布,本平台仅提供信息存储服务。】如有任何疑问,请联系(editor@zero2ipo.com.cn)投资界处理。




