
11月10日,近日有消息称,芯片巨头英伟达(NVIDIA)将基于H100推出三款针对中国市场的AI芯片,以应对美国最新的芯片出口管制。
规格文件中显示,英伟达即将向中国客户推出新产品分别名为HGX H20、L20 PCle、L2 PCle,基于英伟达的Hopper和Ada Lovelace架构。从规格和命名来看,三款产品针对的是训练、推理和边缘场景,最快将于11月16日公布,产品送样时间在今年11月至12月,量产时间为今年12月至明年1月。
钛媒体App从多位英伟达产业链公司了解到,上述消息属实。
钛媒体App还*了解到,英伟达的这三款 AI 芯片并非“改良版”,而是“缩水版”。其中,用于 AI 模型训练的HGX H20在带宽、计算速度等方面均有所限制,理论上,整体算力要比英伟达 H100 GPU芯片降80%左右,即H20等于H100的20%综合算力性能,而且增加HBM显存和NVLink互联模块以提高算力成本。所以,尽管相比H100,HGX H20价格会有所下降,但预计该产品价格仍将比国内 AI 芯片910B高一些。
“这相当于将高速公路车道扩宽,但收费站入口未加宽,限制了流量。同样在技术上,通过硬件和软件的锁,可以对芯片的性能进行精确控制,不必大规模更换生产线,即便是硬件升级了,性能仍然可以按需调节。目前,新的H20已经从源头上‘卡’住了性能。”一位行业人士这样解释新的H20芯片,“比如,原先用H100跑一个任务需要20天,如今H20再跑可能要100天。”
尽管美国发布新一轮芯片限制措施,但英伟达似乎并没有放弃中国巨大的 AI 算力市场。
那么,国产芯片是否可以替代?钛媒体App了解到,经过测试,目前在大模型推理方面,国内 AI 芯片910B仅能达到A100的60%-70%左右,集群的模型训练难以为继;同时,910B在算力功耗、发热等方面远高于英伟达A100/H100系列产品,且无法兼容CUDA,很难完全满足长期智算中心的模型训练需求。
截止目前,英伟达官方对此并未做出任何评论。
据悉,今年10月17日,美国商务部工业和安全局(BIS)发布了针对芯片的出口管制新规,对包括英伟达高性能AI芯片在内的半导体产品施加新的出口管制;限制条款已经于10月23日生效。英伟达给美国SEC的备案文件显示,立即生效的禁售产品包括A800、H800和L40S这些功能最强大的AI芯片。
另外,L40和RTX 4090芯片处理器保留了原有30天的窗口期。
10月31日曾有消息称,英伟达可能被迫取消价值50亿美元的先进芯片订单,受消息面影响,英伟达股价一度大跌。此前,英伟达为中国*的A800和H800,由于美国新规而无法正常在中国市场销售,而这两款芯片被称为A100及H100的“阉割版”,英伟达为了符合美国之前的规定而降低了芯片性能。
10月31日,中国贸促会新闻发言人张鑫表示,美方新发布的对华半导体出口管制规则,进一步加严了人工智能相关芯片、半导体制造设备对华出口的限制,并将多家中国实体列入出口管制“实体清单”。美国这些措施严重违反了市场经济原则和国际经贸规则,加剧了全球半导体供应链撕裂与碎片化风险。美国自2022年下半年开始实施的对华芯片出口禁令正在深刻改变全球供需,造成2023年芯片供应失衡,影响了世界芯片产业格局,损害了包括中国企业在内的各国企业的利益。
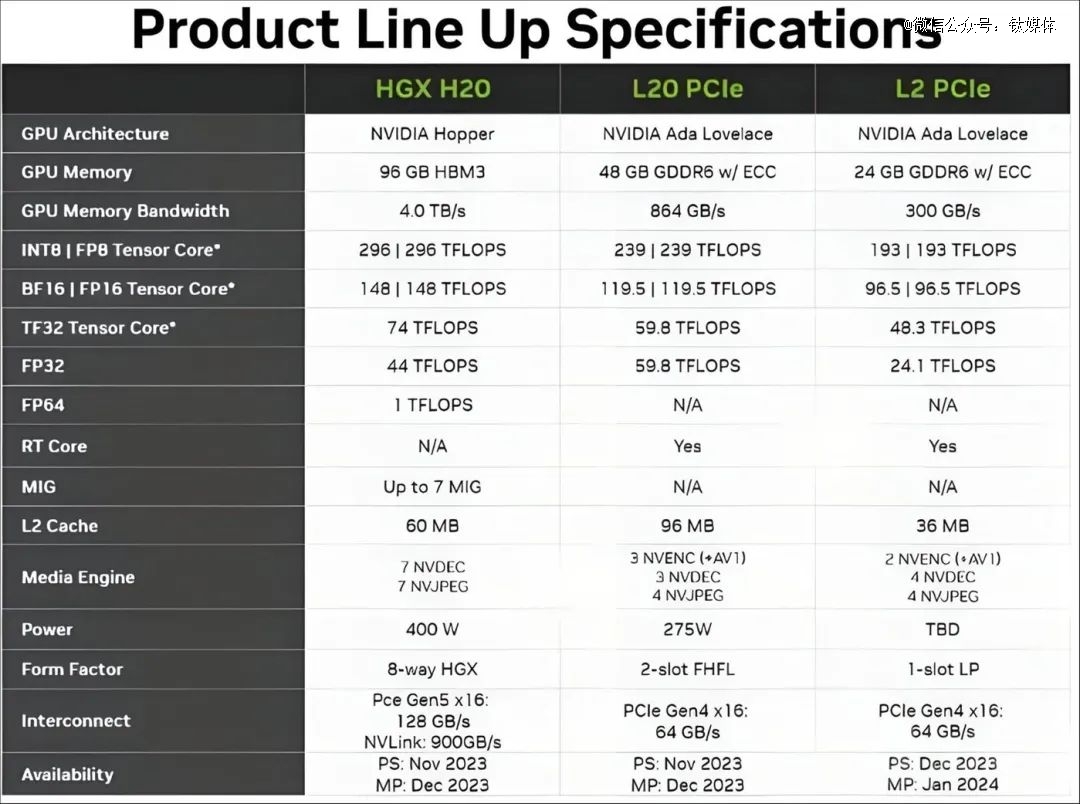
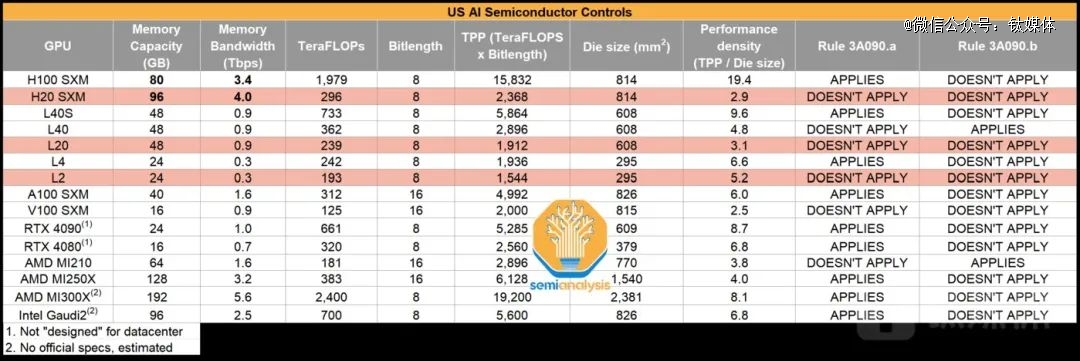
英伟达HGX H20、L20、L2与其他产品的性能参数对比
钛媒体App了解到,新的HGX H20、L20、L2三款 AI 芯片产品,分别基于英伟达的Hopper和Ada架构,适用于云端训练、云端推理以及边缘推理。
其中,后两者L20、L2的 AI 推理产品有类似的“国产替代”、兼容CUDA的方案,而HGX H20是基于H100、通过固件阉割方式 AI 训练芯片产品,主要替代A100/H800,国内除了英伟达,模型训练方面很少有类似国产方案。
文件显示,新的H20拥有CoWoS先进封装技术,而且增加了一颗HBM3(高性能内存)到96GB,但成本也随之增加240美元;H20的FP16稠密算力达到148TFLOPS(每秒万亿次浮点运算),是H100算力的15%左右,因此需要增加额外的算法和人员成本等;NVLink则由400GB/s升级至900GB/s,因此互联速率会有较大升级。
据评估,H100/H800是目前算力集群的主流实践方案。其中,H100理论极限在5万张卡集群,最多达到10万P算力;H800*实践集群在2万-3万张卡,共计4万P算力;A100*实践集群为1.6万张卡,最多为9600P算力。
然而,如今新的H20芯片,理论极限在5万张卡集群,但每张卡算力为0.148P,共计近为7400P算力,低于H100/H800、A100。因此,H20集群规模远达不到H100的理论规模,基于算力与通信均衡度预估,合理的整体算力中位数为3000P左右,需增加更多成本、扩展更多算力才能完成千亿级参数模型训练。
两位半导体行业专家向钛媒体App表示,基于目前性能参数的预估,明年英伟达B100 GPU产品很有可能不再向中国市场销售。
整体来看,如果大模型企业要进行GPT-4这类参数的大模型训练,算力集群规模则是核心,目前只有H800、H100可以胜任大模型训练,而国产910B的性能介于A100和H100之间,只是“万不得已的备用选择”。
如今英伟达推出的新的H20,则更适用于垂类模型训练、推理,无法满足万亿级大模型训练需求,但整体性能略高于910B,加上英伟达CUDA生态,从而阻击了在美国芯片限制令下,国产卡未来在中国AI芯片市场的*选择路径。
最新财报显示,截至7月30日的一个季度内,英伟达135亿美元的销售额中,有超过85%份额来自美国和中国,只有大约14%的销售额来自其他国家和地区。
受H20消息影响,截至美股11月9日收盘,英伟达股价微涨0.81%,报收469.5美元/股。近五个交易日,英伟达累涨超过10%,最新市值达1.16万亿美元。
【本文由投资界合作伙伴微信公众号:钛媒体授权发布,本平台仅提供信息存储服务。】如有任何疑问,请联系(editor@zero2ipo.com.cn)投资界处理。





