
2011年9月,英特尔开发者论坛(IDF)的最后一天,英特尔首席技术官贾斯汀-拉特纳(Justin Rattner)在长达一小时的演讲中,抽出了大约一分钟的时间介绍了一项革命性的技术——HMC(Hybrid Memory Cube,混合内存立方体)。
这项技术由美光和英特尔共同合作开发,虽然被一笔带过,但它的重要性,其实并不比处理器架构迭代要差多少,因为这是内存产业又一次的革命,有望彻底解决过往DDR3所面临的带宽问题。
实际上,早在IDF开始前的8月,美光研究员兼首席技术专家Thomas Pawlowski就在Hot Chips 上详细介绍了HMC,当时虽然没有透露与英特尔的合作,但他表示,HMC是一种三维集成电路创新,它超越了三星等公司展示的处理器-内存芯片堆叠技术,是一种全新的内存-处理器接口架构。
对于美光来说,HMC就是反杀三星海力士两大韩厂的最有力武器。
内存革命
在介绍HMC的时候,Pawlowski 对当时DRAM标准的落后提出了质疑,他认为,出于继续增加带宽并降低功耗和延迟以满足多核处理的需求,对内存的直接控制必须让位于某种形式的内存抽象,DRAM厂商总是需要一个行业标准机构(例如JEDEC)就用于指定 DRAM 的约 80 个参数达成一致,从而产生“*公分母”解决方案。
他的言外之意就是,美光不打算继续一起慢吞吞地坐下来协商了,既然内存带宽吃紧,那就开发一种全新的高带宽标准,抛开JEDEC那堆框框架架的束缚,自己另立一个山头,而盟主呢,自然就是美光了。
在Pawlowski所公布的全新 HMC 标准中,从处理器到存储器的通信是通过高速 SERDES 数据链路进行的,该链路会连接到 DRAM 堆栈底部的本地逻辑控制器芯片,IDF 上所展示的原型里,4 个 DRAM 通过硅通孔(TSV)连接到逻辑芯片,还描述了多达 8 个 DRAM 的堆叠,值得一提的是,原型里的处理器没有集成到堆栈中,从而避免了芯片尺寸不匹配和散热问题。
HMC本质上其实是一个完整的 DRAM 模块,可以安装在多芯片模块 (MCM) 或 2.5D 无源插接器上,从而更加贴近 CPU,除此之外,美光还介绍了一个"远存储器"的配置,在这以配置中,一部分 HMC 连接到主机,而另一部分 HMC 则通过串行链接连接到其他 HMC,以此来形成存储器立方体网络。
以今天的目光来看,HMC不可谓不先进,而Pawloski也颇感自豪,他表示HMC无需使用复杂的内存调度程序,只需使用一个薄仲裁器即可形成浅队列,HMC从架构上就消除了复杂的标准要求,时序约束不再需要标准化,只有高速 SERDES 接口和外形尺寸才需要标准化,而这部分规范完全可以通过定制逻辑 IC 进行调整以适应应用,大容量 DRAM 芯片在众多应用中都是相同的。
在许多人担心的延迟问题上,Pawlowski也表示,虽然HMC的串行链路会略微增加系统延迟,但整体的延迟反而是显著降低的,尤其是它的DRAM 周期时间 (tRC) 在设计上较低,较低的队列延迟和较高的存储体可用性还进一步缩短了系统延迟。
他同时也展示了*代 HMC 原型的具体数据,美光同英特尔合作,通过将 1Gb 50nm DRAM 阵列与 90nm 原型逻辑芯片相结合构建了*代 27mm x 27mm HMC 原型,其在每个立方体上使用 4 个 40 GBps(每秒十亿字节)链路,每个立方体的总吞吐量为 160 GBps,DRAM 立方体的总容量为 512MB,由此产生的性能比下一代 DDR4 显着提高了约 3 倍的能效(以 pj/bit 为单位)。
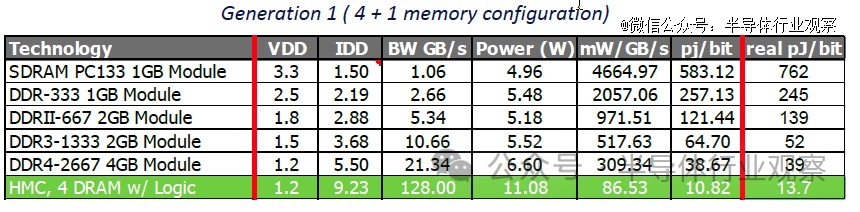
HMC解决了传统DRAM的带宽问题,一时之间成为了大家的新宠儿,但实质上是集不断发展的硅通孔(TSV)技术于大成,并不能全然归功于美光和英特尔。
什么是TSV呢?TSV全称为Through Silicon Via,是一种新型三维堆叠封装技术,主要是将多颗芯片(或者晶圆)垂直堆叠在一起,然后在内部打孔、导通并填充金属,实现多层芯片之间的电连接。相比于传统的引线连接多芯片封装方式,TSV能够大大减少半导体设计中的引线使用量,降低工艺复杂度,从而提升速度、降低功耗、缩小体积。
早在1999年,日本超尖端电子技术开发机构(ASET)就开始资助采用TSV技术开发的3D IC芯片项目“高密度电子系统集成技术研发”,也是最早研究3D集成电路的机构之一,之后的2004年,日本的尔必达也开始自己研发TSV,并于2006年开发出采用TSV技术的堆栈8颗128Mb的DRAM架构。
闪存行业先一步实现了3D堆叠的商业化,东芝在2007 年 4 月推出了具有 8 个堆叠裸片的 NAND 闪存芯片,而海力士则是在同年 9 月推出了具有 24 个堆叠裸片的 NAND 闪存芯片。
而内存行业相对稍晚一点,尔必达在2009年9月推出了*款采用TSV的DRAM芯片,其使用8颗1GB DDR3 SDRAM堆叠封装而来,2011年3月,SK海力士推出了使用 TSV 技术的 16 GB DDR3 内存(40 nm级别),同年9 月,三星推出了基于 TSV 的 3D 堆叠 32 GB DDR3(30 nm级别)。
集合了最新TSV技术的HMC,不仅荣获了2011年The Linley Group(《微处理器报告》杂志出版商)所颁发的*新技术奖,还引发了一众科技公司的兴趣,包括三星、Open-Silicon、ARM、惠普、微软、Altera和赛灵思在内的多家公司与美光组成了混合内存立方联盟 (HMCC),美光开始磨拳霍霍,准备开始一场更加彻底的内存技术革命。
JEDEC的反击
前面提到了美光技术专家Pawlowski对于旧内存标准的抨击,尤其是JEDEC机构,似乎成了一个十恶不赦的坏蛋,仿佛是因为它的存在,内存技术才迟迟得不到改进。
那么JEDEC又是何方神圣呢?
JEDEC固态技术协会(Solid State Technology Association)是固态及半导体工业界的一个标准化组织,最早历史可以追溯到1958年,由电子工业联盟(EIA)和美国电气制造商协会(NEMA)联合成立的联合电子设备工程委员会(Joint Electron Device Engineering Council,JEDEC),其主要职责就是制定半导体的统一标准,而在1999年后,JEDEC独立成为行业协会,确立了现在的名字并延续至今。
作为一个行业协会,JEDEC 制定了 DRAM 组件的封装标准,并在 20 世纪 80 年代末制定了内存模块的封装标准。“ JC-42及其小组委员会制定的标准是我们能够如此轻松地升级 PC 内存的原因,”自 20 世纪 70 年代以来一直担任 JEDEC 志愿者的 Mark Bird 说道,“我们对各个组件配置、SIMM、它们所在的插槽以及每一个设备的功能进行了标准化。”
虽然说做DRAM的厂商,肯定离不开JEDEC所制定的标准,但JEDEC本质上并不具备强制性,其*大原则就是开放性与自愿性标准,所有标准都是开放性、自愿性的,不会偏袒某一个国家与地区而歧视其他国家或地区,拥有近300家会员公司的它还奉行着一家公司一票与三分之二多数制的制度,从而降低了标准制定程序被任何一家或一批公司所把控的风险。
不管是美光也好,三星海力士也罢,它们并没有能力去干涉JEDEC标准的制定,即使DRAM厂商早已屈指可数,但标准的话语权并不由三巨头所掌握,只有大家真正认可,才会最终被推行为正式标准。
这时候问题来了,行业还在JEDEC所制定的标准下前行,美光却要单独跳出来自己干,还组建了属于自己的联盟,这听起来有点像苹果才会做的事,如同火线接口、早期雷电接口和Lighting接口等,东西是好东西,但是独此一家别无分号。
要是美光这HMC技术足够先进也就罢了,*JEDEC四五年,也能像苹果一样赚笔小钱,也能和韩国厂商分庭抗礼了,只可惜这技术只*了一两年左右,甚至可能还没有这么久。
在美光公布HMC的2011年,JEDEC就公布了关于Wide IO 的 JESD229 标准,作为一项3D IC 存储器接口标准,其正是为了解决DRAM带宽而来,基本概念是使用大量引脚,每个引脚的速度相对较慢,但功率较低。
2012年1月,该标准正式通过,其中规定了 4 个 128 位通道,通过单数据速率技术连接到以 200MHz 频率运行的 DRAM,总带宽为 100Gb/S,虽然还是不能与HMC的带宽相媲美,但也从侧面证明了JEDEC的标准并非一直原地踏步和一无是处。
当然,如果只有Wide IO也就算了,毕竟HMC的理念足够先进,虽然价格也很昂贵,但是总会有一部分高带宽需求的产品来买单,前景还是挺光明的。
但到了2013年,又杀出了一个程咬金——AMD和海力士宣布了它们共同研发的HBM,其使用了 128 位宽通道,最多可堆叠 8 个通道,形成 1024 位接口,总带宽在 128GB/s 至 256GB/s 之间,DRAM 芯片堆叠数为 4 至 8 个,且每个内存控制器都是独立计时和控制的。
就成本和带宽而言,HBM 是一个看似中庸的选择,既不如Wide I/O 便宜,带宽也比不上HMC,但中庸的HBM却通过GPU确定了自己的地位,AMD和英伟达先后都选择了HBM来作为自家显卡的内存。
而给了美光HMC致命一击的是,HBM刚推出没多久,就被定为了JESD235的行业标准,一个是行业内主要科技公司都在内的大组织,一个是美光自己拉起来的小圈子,比赛还没正式开始,似乎就已经分出了胜负。
HMC的末路
2013年4月,HMC 1.0规范正式推出,根据该规范,HMC 使用 16 通道或 8 通道(半尺寸)全双工差分串行链路,每个通道有 10、12.5 或 15 Gbit/s串行解串器,每个 HMC 封装被命名为一个cube,它们可以通过cube与cube之间的链接以及一些cube将其链接用作直通链接,组成一个最多 8 个cube的网络。
当然,在HMC 1.0发布时,美光依旧是信心满满,美光 DRAM 营销副总裁 Robert Feurle 表示:“这一里程碑标志着内存墙的拆除。” “该行业协议将有助于推动 HMC 技术的最快采用,我们相信这将彻底改进计算系统,并最终改进消费者应用程序。”
而在2014年1月举行的“DesignCon 2014”上,美光首席技术专家Pawlowski表示JEDEC并没有在 DDR4 之后做出任何新的努力,“HMC需要的只是一个SerDes(串行器/解串器)接口,其具有简单指令集,不需要所有细节,未来的趋势是HMC取代DDR成为DRAM的新标准。”他说到。
事实真的和美光说的一样吗?
当然不是,HMC看似强大的带宽,是建立在昂贵成本之上的,从2013年*版规范开始算起,真正采用了HMC技术的产品,也只有天文学项目The Square Kilometer Array (SKA) 、富士通的超级计算机 PRIMEHPC FX 100、Juniper的高性能网络路由器和数据中心交换机以及英特尔的 Xeon Phi 协处理器。
看到英特尔也别太兴奋,据美光公司称,虽然Xeon Phi 协处理器的内存解决方案采用与 HMC 相同的技术,但它专门针对集成到英特尔的 Knight's Landing 平台中进行了优化,没有标准化计划,也无法提供给其他客户,什么意思呢?就是英特尔没完全遵循HMC,自己另外搞了一套标准。
而且,别说普通消费者了,连英伟达和AMD的专业加速卡都与HMC无缘,HBM已经足够昂贵了,HMC比起它还要再贵一些,美光虽然没有公布过具体的费用,但我们相信,这个价格一定会是大部分厂商所不能承受之重,内存带宽重要是不假,但过于昂贵的成本,只会劝退客户。
值得一提的是,三星和海力士虽然也一度加入过HMCC联盟中,但它们并不是主要推动者,甚至没有大规模量产过HMC产品,2016年之后,两家都专注于HBM了,除了几个铁哥们愿意支持一下美光,HMCC的成员更多的是重在参与。
时间来到2018年,HMC早就没有了2011年时的风光,用门可罗雀来形容也不过分,人工智能在这一年开始兴起,高带宽成为了内存行业的重心,但背后的市场几乎都被HBM招徕走了,主推该标准的海力士与三星成了大赢家。
Objective Analysis 首席分析师吉姆·汉迪 (Jim Handy) 在2018年1月接受媒体采访时对美光发出了警告:“英特尔未来也会从HMC变体转向HBM,考虑到二者间没有太大区别,如果美光必须转型,损失也不会太大。”
好在美光没有执迷不悟,在2018年8月宣布正式放弃HMC,转而追求具有竞争性的高性能存储技术,也就是HBM,但大家都准备搞HBM2E了,美光此时再入场,不论是吃肉还是喝汤都轮不到它,只能慢慢追赶。
2020年3月,美光的HBM2也就是第二代HBM才姗姗来迟,其最新量产的HBM也止步于HBM2E,明显落后于两家韩厂,而市场也忠实反馈了这一差距,根据 TrendForce 的最新数据,SK 海力士占据全球 HBM 市场 50% 的份额,位居*;三星紧随其后,占据 40% 的份额;而美光位居第三,仅占据 10% 的份额。
不过有意思的是,美光似乎对HMC并未完全死心。
2020年3月,美光公司高级计算解决方案副总裁 Steve Pawlowski 表示,美光是HMC技术最早和最有力的支持者之一,如今的重点是该架构如何能够满足特定用例(包括人工智能 (AI))的高带宽内存需求,事实上在 HMC 最初构想时,人工智能 (AI) 并不存在,“我们怎样才能在低功耗、高带宽方面获得*的性价比,同时能够为我们的客户提供更具成本效益的封装解决方案?”他说到。
Pawlowski 还表示,美光继续通过“探路计划”探索 HMC 的潜力,而不是遵循最初的规格更新计划,从性能角度来看,HMC 是一个出色的解决方案,但客户也在寻求更大的容量,新兴的人工智能工作负载更注重带宽,因此这正是 HMC 架构的潜力所在。
“HMC 似乎仍有生命力,它的架构可能适用于最初构想时并不存在的应用,”Pawlowski 说,“HMC 是*于时代的技术的一个极好例子,它需要建立一个生态系统才能被广泛采用,我的直觉是,HMC 风格的架构就属于这一阵营。"
遥遥落后的美光
如今是2024年年初,HBM已经火爆了一整年,SK海力士、三星和美光无不以下一代HBM3E乃至HBM4为目标,努力保证自家的技术*,尤其是美光,为了改善自己在HBM市场中的被动地位,它选择了直接跳过第四代HBM即HBM3,直接升级到了第五代。
2023年9月,美光宣布推出HBM3 Gen2(即HBM3E),后续表示计划于 2024 年初开始大批量发货 HBM3 Gen2 内存,同时透露英伟达是主要客户之一,美光总裁兼首席执行官 Sanjay Mehrotra 也在公司财报电话会议里表示:“我们的 HBM3 Gen2 产品系列的推出引起了客户的浓厚兴趣和热情。”
但对于美光来说,技术迎头赶上只是*步,更重要的是能不能在标准上掌握话语权,2022年1月,JEDEC发布了最新的HBM3标准,其主要贡献者就是美光老对手,也是HBM的创造者之一——SK海力士,而现在被普遍认可的HBM3E这一名称,同样来源于SK海力士。
成为标准贡献者有啥好处呢?那就是SK海力士所推出的HBM3E可以大方宣称自己的向后兼容性,即使在没有设计或结构修改的情况下,也能将这一产品应用于已经为HBM3准备的设备上,不管是英伟达还是AMD,都可以轻松升级原有的产品,满足更多客户的需要。
而据Business Korea报道,英伟达已经与SK海力士签订HBM3E优先供应协议,用于新一代B100计算卡,虽然美光和三星都向英伟达提供了HBM3E的样品,完成验证测试后就会正式签约,但有业内人士预计,SK海力士仍然会率先取得HBM3E供应合同,并从中获得*的供应份额。
此前我们谈到过,存储巨头们一直梦想着一件事情,就是摆脱传统的半导体周期,过上更为安稳的日子,HMC曾是美光的一个梦想,用新标准取代旧标准,用封闭生态代替开放生态,希望凭借它来成为DRAM技术*,但它却陷入到一个怪圈当中:HMC价格更昂贵——客户缺乏意向——成本增加导致价格上涨——流失更多潜在客户。
目前来看,HBM是一个更好的切入口,它在新型DRAM的市场和利润间取得了一个微妙平衡,而SK海力士就是三巨头里走得最远的一家,考虑到未来AI芯片的性能很大程度上受到HBM的放置和封装方式的影响,SK海力士很有可能成为*个跳出周期的厂商。
美光首席技术专家Pawlowski在2011年的Hot Chip上大力批判了落后的内存标准,但他*不会想到的是,看似先进的HMC最终会被纳入JEDEC标准的HBM所击败,美光空耗了六七年时间,最终甜美果实却被韩厂摘走,让人感慨不已。
参考资料:
Beyond DDR4: The differences between Wide I/O, HBM, and Hybrid Memory Cube——extremetech
HBM Flourishes, But HMC Lives——eetimes
'기술' 타이밍 놓치면 순식간 '몰락'… 설 자리 잃은 '마이크론'——newdaily
【本文由投资界合作伙伴微信公众号:半导体行业观察授权发布,本平台仅提供信息存储服务。】如有任何疑问,请联系(editor@zero2ipo.com.cn)投资界处理。





