
人才与能源,正在成为科技公司AI战役中必夺的高地塔。
“这场AI的人才之战,是我见过的最疯狂的人才争夺战!”马斯克在推特上直言。
就在5月28日,这位特斯拉CEO创办的AI初创公司——xAI在官网宣布融资60亿美元,用于打造超级计算机,马斯克称之为“超级计算工厂”。诚然,这需要更多人才。马斯克甚至表示,xAI如果不提供offer,人就被Open AI挖走了。
在这场谁也看不到未来确切形状的人工智能大模型战役中,投资一个靠谱的团队,对于投资公司来说显然是最有力的保障。这也是这场人才争夺战愈演愈烈的重要原因。
不过,“真正优秀的人才通常不会主动找工作,因此需要去挖那些你看好的人才”。OpenAI创始人Sam Altman早年在他的文章中提及。
信息差是这场人才争夺战中决定胜负的关键。
我们的*篇人才图谱聚焦这个科技巨头们重金押注的领域——具身智能。
如果说这场AI战事的未来难以预测,具身智能或许是其中一种*形态。英伟达CEO黄仁勋更是表示,下一个AI浪潮将是具身智能。
硅兔尝试梳理了美国大公司,两个AI黄浦军校——谷歌和英伟达的具身智能人才图谱以及在其中的华裔大佬,或许能为希望在其中进行创业或投资的读者提供按图索骥的参考。
「1」根据谷歌和英伟达重点具身智能论文和项目一共梳理114名业界实战大佬,其中谷歌占比60%,英伟达40%,男多(90%)女少(10%)。
「2」8%的研究员学术水平比肩美国科学院院士。59%的研究员属于高水平段位。
「3」78%的研究员最高学历水平为博士,研究生占比18%,本科生仅占比4%。
「4」华裔在谷歌和英伟达具身智能研究员中占比约27%。
「5」斯坦福向谷歌和英伟达输送了最多具身智能大佬,其次是CMU和MIT,三家学校输送的人才占比约1/3。
欲知数据详解及华裔大佬履历见下
「1」
共计248名研究员参与了谷歌和英伟达具身智能研究,剔除62名未在Google Scholar建档的研究员,剩余186名研究员中,业界力量占六成、学界力量占四成。
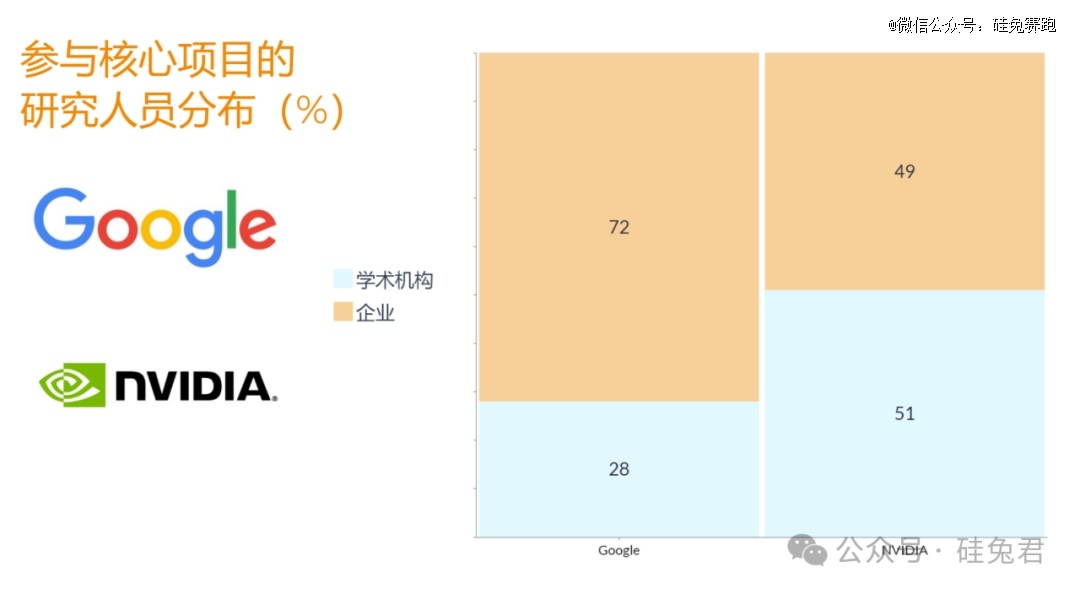
具体来看,谷歌独立研究能力更强,英伟达借助了多个*学校的研究资源。参与英伟达机器人研究的高校研究人员达到45人,占比一半(51%);相较之下,谷歌的这个比例不到三分之一(27人,28%)。
「2」
聚焦业界人才,谷歌和英伟达114位研究员中,男性占比约90%,华裔占比约27%,博士学历占比约78%。
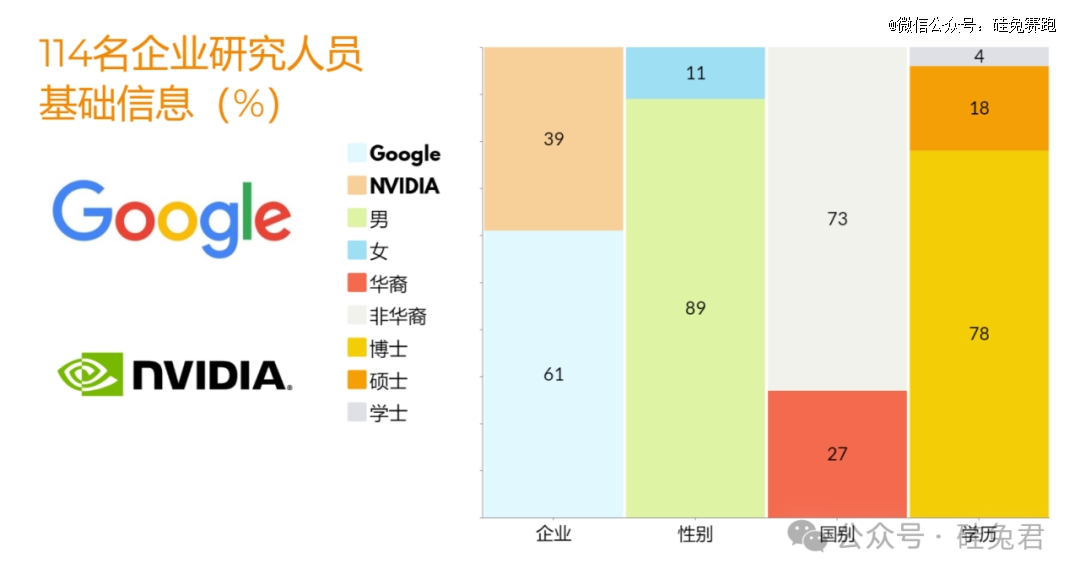
在性别比例和族裔方面,谷歌和英伟达略有差异,谷歌似乎对女性更友好,有11名女性科学家加入,而英伟达只有2名。
英伟达华裔的比例更高,占比达40%,而这一比例在Google只有20%。
「3」
斯坦福向谷歌和英伟达输送了最多具身智能大佬,其次是CMU和MIT,三家学校输送的人才占比约1/3。
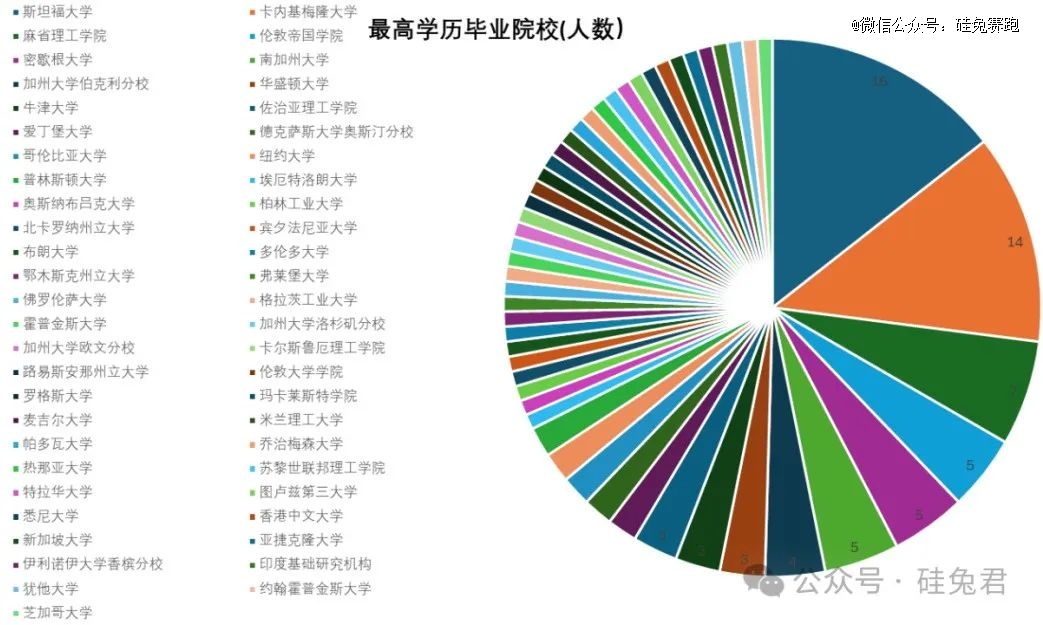
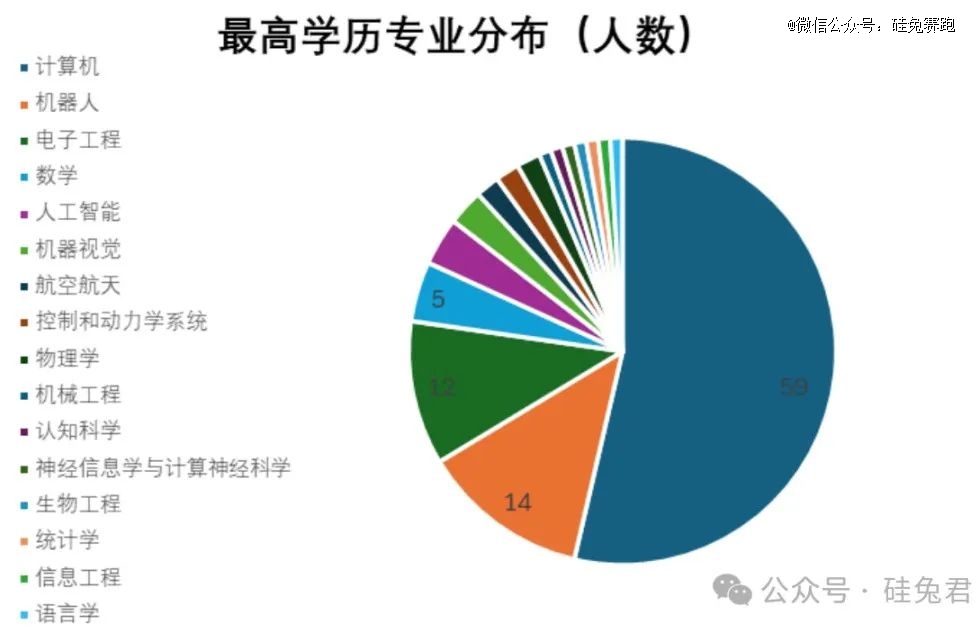
114位研究员最高学历毕业的院校总共有51所大学。其中,斯坦福大学有16人,卡内基梅隆大学有14人,麻省理工学院有7人,这三所学校的人数占比约三分之一,而其他大多数学校只有一名学生。
绝大部分研究人员来自美国的院校,但欧洲也有两所学校在具身智能领域产生了重大影响:英国伦敦帝国理工学院和牛津大学,毕业于这两所学校的研究人员共有8人。牛津大学在深度学习方面积累了丰富的经验,并且谷歌收购DeepMind后与牛津大学展开了合作,引入了深度学习领域的专家。例如,AlphaGo的研发团队中就包括了3名牛津大学在职教授以及4位前牛津大学的研究人员。
「4」
8%的业界研究员学术水平比肩美国科学院院士。59%的业界研究员属于高水平段位。谷歌研究员的学术能力相较英伟达更强。
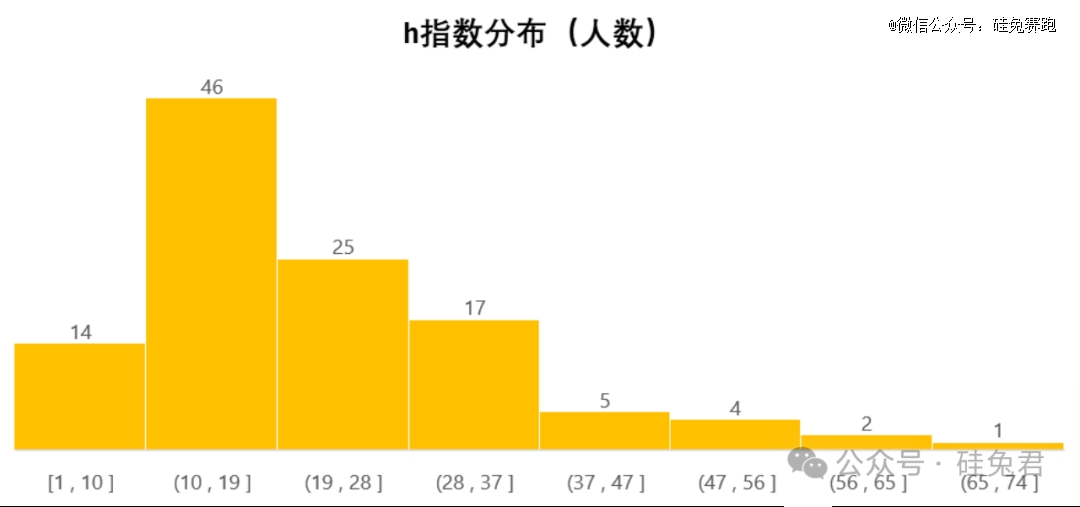
我们采用被引用量和“h”指数来衡量学术水平。“h”指数是一位作者至少具有相同引用次数(h)的最高发表论文数量。例如:某人的h指数是20,这表示他已发表的论文中,每篇至少被引用了20次的论文总共有20篇。
一般来说,h指数在10以上可以被认为是较高水平,h指数18属于高水平,而成为美国科学院院士的一般要求是45以上。
这114名企业研究人员的h指数表现出了他们相当强的研究水平:89%的人的h指数大于10,59%的人的h指数大于18,而有8%的人的h指数甚至超过了45。
进一步比较谷歌和英伟达的学术水平会发现,谷歌研究人员影响力明显要比英伟达高。例如,谷歌企业研究人员引用量平均数和h指数平均数是12596和23,而英伟达的这一组数据为6418和21。
「5」
谷歌和英伟达各有约1/10的具身智能研究员离职加入其他公司。
谷歌70人中有7人离开,占比10%。目前在英伟达、苹果、特斯拉、1x、OpenAI、Figure AI等企业就职,总体上来说离开谷歌的人才较少,绝大多数人才在Google DeepMind工作。
其中,Scott Reed 2016 年加入 Google DeepMind 从事控制和生成模型方面的工作,后加入英伟达成为GEAR 团队的首席研究科学家。
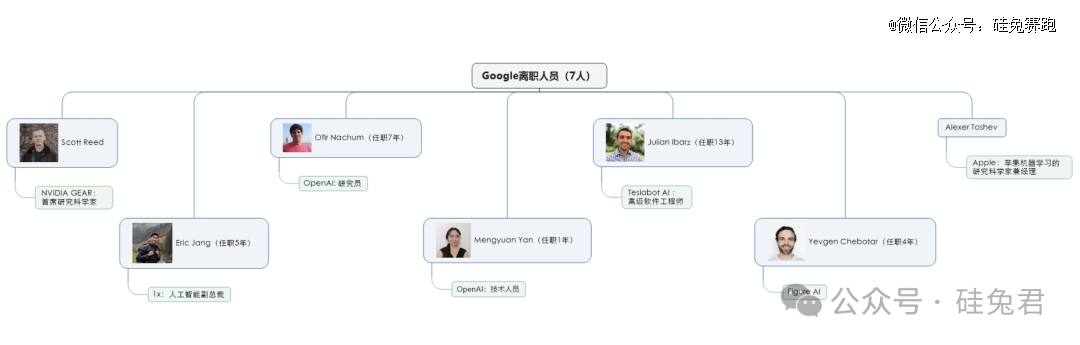
注:谷歌离职研究员及去向
英伟达44名具身智能研究人员有4人离开,占比9%。一人去了谷歌,一人去了Allen Institute for AI研究机构,另外两人选择创业。
Igor Mordatch的研究兴趣包括机器学习、机器人学和多智能体系统,他曾是OpenAI的研究科学家,在斯坦福大学和Pixar动画工作室担任访问研究员。他共同组织了OpenAI学者指导计划,并担任AI4All、Google CS研究指导计划和Girls Inc.的导师和教学助理。离开英伟达后在Google DeepMind担任研究科学家。他发布文章约123篇,Google Scholar h指数51,被引用量18752次。
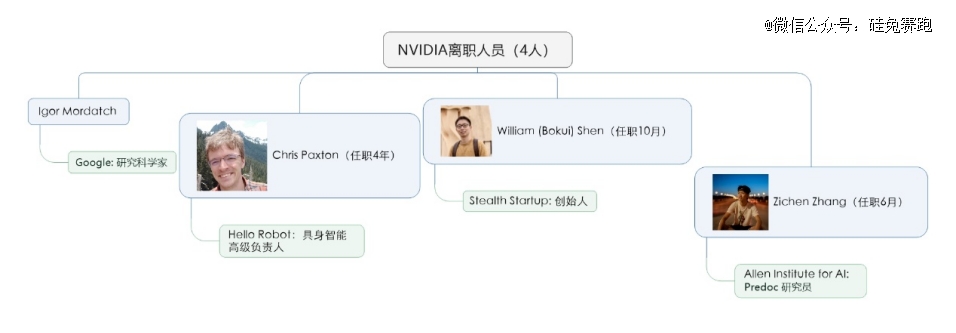
注:英伟达离职研究员及去向
「6」
“美国科学院院士”学术水平(h指数大于45)的研究员,谷歌得6人,英伟达得1人。他们分别是(按照指数高低):
谷歌
Nicolas Heess
DeepMind研究科学家。
2011年发表论文《Learning a Generative Model of Images by Factoring Appearance and Shape》,彼时正在攻读爱丁堡大学的神经信息学与计算神经科学博士学位,毕业后在DeepMind工作至今。
早期研究聚焦在机器视觉、机器学习、图形/增强现实/游戏等领域,目前是英国UCL计算机系荣誉教授。
发布约224篇文章 ,Google Scholar h指数65,被引用量48917次。
Martin Riedmiller
DeepMind研究科学家。
1986-1996年在德国University of Karlsruhe(卡尔斯鲁厄大学,现在的卡尔斯鲁厄理工学院)学习计算机专业,并取得博士学位。毕业后他一边在学术界任教,一边创业。
2002年- 2015年先后在University of Dortmund、University of Osnabrueck、University of Freiburg担任教授,带领Machine Learning Lab;2010 -2015年在德国巴登创立Cognit - Lab for learning machines。
2015年加入Google DeepMind全职工作。
他的研究领域聚焦人工智能、神经网络、强化学习等,发布约188篇文章,Google Scholar h指数59,被引用量84113次。
Vikas Sindhwani
Google DeepMind研究科学家,领导着一个专注于解决机器人领域规划、感知、学习和控制问题的研究小组。
他拥有芝加哥大学的计算机科学博士学位和印度理工学院(IIT)孟买分校的工程物理学士学位。
2008年-2015年在IBM T.J. Watson Research Center纽约分部负责机器学习组。2015年加入Google DeepMind工作至今。
担任《机器学习研究交易》(TMLR)和《IEEE模式分析与机器智能交易》的编辑委员会成员;曾是NeurIPS、国际学习表示会议(ICLR)和知识发现与数据挖掘(KDD)的领域主席和高级程序委员会成员。
研究兴趣广泛涉及统计机器学习的核心数学基础,以及构建大规模、安全、健康人工智能系统的端到端设计。
曾获得人工智能不确定性(UAI-2013)*论文奖和2014年IBM Pat Goldberg纪念奖;并入围了ICRA-2022杰出规划论文奖和ICRA-2024机器人操作*论文奖的决赛。
发布约137篇文章,Google Scholar h指数52,被引用量17150次。
Vincent Vanhoucke
Google DeepMind杰出科学家、机器人技术部门高级总监,在谷歌工作超过16年。
拥有斯坦福大学电气工程的博士学位(1999-2003)和巴黎中央理工学院的工程师学位。
曾领导Google Brain的视觉和感知研究,并负责谷歌语音搜索的语音识别质量团队。共同创立了机器人学习会议(Conference on Robot Learning)。
研究涵盖了分布式系统和并行计算、机器智能、机器感知、机器人和语音处理等多个领域。发布约64篇文章,Google Scholar h指数50,被引用量165519次。
Raia Hadsell
DeepMind研究与机器人技术高级总监,VP of Research。
2014年加入至今。
在Reed College获得宗教学和哲学学士学位后(1990-1994),在纽约大学与Yann LeCun合作完成博士学位研究(2003-2008),集中于使用连体神经网络(今天通常称为“三元损失”)的机器学习、人脸识别算法,以及在野外使用深度学习进行移动机器人研究。论文“Learning Long-range vision for offroad robots”获得了2009年的杰出论文奖。
在卡内基梅隆大学机器人研究所做博士后研究,与Drew Bagnell和Martial Hebert合作,然后成为新泽西州普林斯顿市SRI国际公司视觉与机器人组的研究科学家(2009-2014)。
加入DeepMind之后,研究重点放在人工通用智能领域的一些基本挑战上,包括持续学习和迁移学习、用于机器人和控制问题的深度强化学习,以及导航的神经模型。是一个新开放期刊TMLR的创始人和主编,CoRL的执行委员会成员,欧洲学习系统实验室(ELLIS)的成员,也是NAISys(神经科学与人工智能系统)的创始组织者之一。担任CIFAR顾问,并曾担任WiML(机器学习中的女性)执行委员会成员。
发布约107篇文章,Google Scholar h指数45,被引用量36265次。
Nikhil J Joshi
资料有限,在印度印度理工学院(Indian Institute of Technology)获得物理硕士学位,在印度基础研究机构Tata Institute of Fundamental Research 获得分子物理学博士学位。2017年加入Google Brain做软件开发,之前在多家企业任职。Google Scholar h指数45,被引用量8320次。
英伟达
Stan Birchfield
英伟达首席研究科学家和高级研究经理。
2016年加入,主要负责计算机视觉和机器人技术的交叉领域,包括学习、感知、以及人工智能介导的现实和交互。
1999年获得斯坦福大学电气工程博士学位,辅修计算机科学。
毕业后,加入湾区初创公司Quindi Corporation担任研究工程师,开发智能数字音频和视频算法。
2013-2016年,加入微软,负责开发计算机视觉和机器人技术的应用与地面实况导航系统,并领导开发了自动摄像头切换功能。
Google Scholar h指数56,被引用量14315次。
「7」
部分业界华裔大佬
这114名企业研究人员中共有31名华裔,重点介绍12名佼佼者,其中谷歌 4人,英伟达 6人,OpenAI 、1x各1人。
谷歌
Fei Xia(夏斐)
Google DeepMind高级研究科学家。
2016年毕业清华,2021年在斯坦福大学电气工程系获得了博士学位。
读博期间曾在NVIDIA的Dieter Fox,Google的Alexander Toshev和Brian Ichter那里做过研究实习。在斯坦福大学完成博士学位后,于2021年秋季加入Google的机器人团队。
研究兴趣包括大规模和可转移的机器人模拟,长期任务的学习算法,以及环境的几何和语义表示的结合。最近研究方向是将基础模型(Foundation Models)用于智能体的决策过程中。
学术成就包括在ICRA 2023会议上接受了5篇论文,在CoRL 2022会议上接受了4篇论文。
代表工作有GibsonEnv, iGibson, SayCan等,iGibson开发用于机器人学习的大规模互动环境,以及在机器人控制策略中使用模仿学习和模型预测控制(MPC)的结合。Google Scholar h指数为33,引用量为12478。
Andy Zeng
Google DeepMind高级研究科学家。
在UC Berkeley获得了计算机科学和数学的双学士学位,并在普林斯顿大学获得了计算机科学博士学位。2019年博士毕业后加入Google Brain工作,专注于机器学习,视觉,语言和机器人学习。
研究兴趣包括机器人学习,使机器能够智能地与世界互动并随着时间的推移自我提高。
学术成就包括在各种会议上发表的论文,如ICRA,CVPR,CoRL等。
参与的重要项目包括PaLM-E。
Google Scholar h指数为32,引用量为12207。
Tianhe Yu
Google DeepMind研究科学家。
2017年在UC Berkeley获得了计算机科学、应用数学和统计学的最高荣誉学士学位,2022年在斯坦福大学获得了计算机科学博士学位,导师是Chelsea Finn。
2022年博士毕业后加入Google Brain工作,专注于机器学习,视觉,语言和机器人学习。
研究兴趣包括机器学习,感知,控制,特别是离线强化学习(即从静态数据集中学习),多任务和元学习。最近在探索在决策问题中利用基础模型。
学术成就包括在各种会议上发表的论文,如ICRA,CVPR,CoRL等。
参与的重要项目包括PaLM-E。
Google Scholar h指数为25,引用量为7726。
Yuxiang Zhou
Google DeepMind高级研究工程师。
2010年至2018年间在英国伦敦帝国学院攻读计算机科学硕士和博士学位,导师是Stefanos Zafeiriou教授。
2017年9月至2018年3月在Google Brain & DeepMind进行了深度强化学习和机器人学的研究实习,在2018年12月加入Google DeepMind,担任研究工程师。
研究主题包括解决机器人学、第三人称模仿学习、统计变形模型的密集形状研究等。
Google Scholar h指数为17,引用量为3099。
英伟达
Linxi Fan(范林熙)
NVIDIA 高级研究科学家,也是 GEAR Lab的负责人。
在斯坦福大学视觉实验室获得博士学位,师从李飞飞教授。
曾在 OpenAI(与 Ilya Sutskever 和 Andrej Karpathy)、百度 AI 实验室(与 Andrew Ng 和 Dario Amodei 合作)和 MILA(与 Yoshua Bengio 合作)实习。
研究探索了多模态基础模型、强化学习、计算机视觉和大规模系统的前沿。
率先创建了 Voyager(*个熟练玩 Minecraft 并持续引导其功能的 AI智能体)、MineDojo(通过观看 100,000 个 Minecraft YouTube 视频进行开放式智能体学习)、Eureka(一只 5 指机器人手,执行极其灵巧的任务,如笔旋转)和 VIMA(最早的机器人操作多模态基础模型之一)。MineDojo 在 NeurIPS 2022 上获得了优秀论文奖。
Google Scholar h指数为18,引用量为5619。
Chen-Hsuan Lin
NVIDIA高级研究科学家。
本科毕业于国立台湾大学,获得了电气工程学士学位。在卡内基梅隆大学获得了机器人学博士学位,导师是 Simon Lucey,受 NVIDIA 研究生奖学金支持。
曾在 Facebook AI 研究和 Adobe 研究进行了实习。
致力于计算机视觉、计算机图形学和生成 AI 应用。解决涉及 3D 内容创建的问题感兴趣,包括 3D 重建、神经渲染、生成模型等。
研究获得了 TIME 杂志 2023 年度*发明奖。
Google Scholar h指数为15,引用量为2752。
De-An Huang(黄德安)
NVIDIA 研究科学家,专业领域是计算机视觉、机器人学、机器学习、生物信息学。
斯坦福大学获得了计算机科学博士学位,导师是李飞飞和胡安·卡洛斯·尼布尔斯。在卡内基梅隆大学攻读硕士学位期间,曾与Kris Kitani合作,在国立台湾大学攻读本科期间,曾与Yu-Chiang Frank Wang合作。
曾是NVIDIA 西雅图机器人实验室的 Dieter Fox、Facebook 应用机器学习的 Vignesh Ramanathan 和 Dhruv Mahajan、Microsoft 雷德蒙德研究院的 Zicheng Liu 和匹兹堡迪斯尼研究院的 Leonid Sigal 的实习生。
Google Scholar h指数为32,引用量为4848。
Kaichun Mo(莫凯淳)
NVIDIA Dieter Fox 教授领导的西雅图机器人实验室的研究科学家。
在斯坦福大学获得了计算机科学博士学位,导师是 Leonidas J. Guibas 教授。曾隶属于斯坦福大学的几何计算组和人工智能实验室。在2016年加入斯坦福之前,在上海交通大学计算机科学ACM班获得了学士学位(PS:上海ACM荣誉班直博率高达92%,3次斩获ACM国际大学生程序设计竞赛全球总冠军,培养出640名计算机“最强大脑”)。GPA为3.96/4.30(排名1/33)。
专业领域是3D计算机视觉、图形学、机器人学和3D深度学习,尤其关注对象为中心的3D深度学习,以及针对3D数据的结构化视觉表示学习。
Google Scholar h指数为20,引用量为17654。
Xinshuo Weng
NVIDIA 研究科学家,与 Marco Pavone 合作。
她在卡内基梅隆大学与 Kris Kitani 合作获得了机器人学博士学位(2018-2022 年)和计算机视觉硕士学位(2016-17 年)。本科毕业于武汉大学。
她还曾与 Facebook Reality Lab 的 Yaser Sheikh 合作,担任研究工程师,帮助构建“逼真的远程呈现”。
研究兴趣在于自主系统的生成模型和3D计算机视觉。涵盖目标检测、多目标跟踪、重新识别、轨迹预测和运动规划等任务。开发了 3D 多对象跟踪系统,例如在 GitHub 上获得 >1,300 颗星的 AB3DMOT。
Google Scholar h指数为23,引用量为3472。
Zhiding Yu (禹之鼎)
NVIDIA 机器学习研究小组的首席研究科学家和负责人。
2017年从卡内基梅隆大学获得了电子与计算机工程博士学位,并于2012年从香港科技大学获得了电子与计算机工程硕士学位。于2008年从华南理工大学联合电气工程(冯炳权实验班)本科毕业。
研究兴趣主要集中在深度表示学习、弱监督/半监督学习、迁移学习和深度结构化预测,以及它们在视觉和机器人问题中的应用。
WAD Challenge@CVPR18 中的领域自适应语义分割赛道的获奖者。在 WACV15 获得了*论文奖。
Google Scholar h指数为42,引用量为17064。
OpenAI
Mengyuan Yan
技术人员。
2014年获得北京大学物理学学士,2020年获得斯坦福大学电子电器工程博士学位。
Interactive Perception and Robot Learning Lab(IPRL)的成员,该实验室是斯坦福AI Lab的一部分,导师是Jeannette Bohg和Leonidas Guibas。
研究领域包括计算机视觉、机器学习、机器人学和生成模型。
共发布28篇文章,Google scholar h指数15,被引用量4664次。
1X Technologies
Eric Jang
AI副总裁。
2016年毕业于布朗大学硕士,专业是计算机科学。
2016 - 2022年在Google工作,担任机器人高级研究科学家,
研究主要集中在将机器学习原则应用于机器人领域,开发了 Tensor2Robot,这是机器人操作团队和 Everyday Robots 使用的 ML 框架(直到 TensorFlow 1 被弃用);是Brain Moonshot团队的共同负责人,该团队制作了SayCan。
2022年4月离开Google Robotics,加入1X Technologies(原名Halodi Robotics),带领团队完成了两项重要工作,一个是通过端到端的神经网络,实现了人形机器人EVE的自主性。
7篇论文的*作者,合著15+以上,Google scholar h指数为23,引用量为11213。写了一本书《AI is Good for You》讲诉人工智能的历史和未来。
「8」
通过重点研究论文和实验项目锁定谷歌和英伟达的具身智能人才。
谷歌重基础模型研究,其具身智能人才参与的重点研究发布包括:
SayCan:能够将高层级任务拆解为可执行的子任务。
Gato:将多模态数据进行token化输入Transformer架构。
RT-1:将机器人轨迹数据输入Transformer架构,得到离散化动作token。
PaLM-E:在PaLM通用模型基础上,进一步提升了多模态性能。
RoboCat:将多模态模型Gato与机器人数据集相结合,使得RoboCat具备在模拟环境与物理环境中处理语言、图像和动作等任务的能力。
RT-2:是RT-1模型与PaLM-E模型的结合,使机器人模型从VLM进化到VLA。
RT-X:在保持原有架构的基础上,全面提升了具身智能的五种能力。
以上模型逐步实现了模型自主可靠决策、多模态感知和实时精准运控能力的结合,同时展现出泛化能力和思维链能力。
综合以上研究论文,共梳理143名谷歌研究员。
英伟达重仿真模拟训练,其具身智能人才参与的实验项目包括:
Eureka:利用大型语言模型进行强化学习的奖励机制设计
Voyager:开放世界中用大语言模型驱动智能体
MimicPlay:通过观察人类动作进行长距离模仿学习
VIMA:多模态指令操控执行通用机器人任务
MinDojo:利用互联网规模级数据建立开放具身智能体
此外,英伟达在2024年重点发力具身智能,官宣成立通用具身智能研究GEAR(Generalist Embodied Agent Research)实验室,主要围绕多模态基础模型、通用型机器人研究、虚拟世界中的基础智能体以及模拟与合成数据技术四个关键领域开展研究,旨在推动大模型等AI技术由虚拟世界向现实世界发展。
本文首先梳理了上述提到的Google核心项目论文共7篇,每篇论文都详细列出了项目研究人员,并清晰地公布了他们的具体工作内容。
英伟达的研究页面公布了参与robotics项目的人员名单,共计54名;另外综合考虑GEAR发布的所有论文作者,共梳理出105名具身智能研究人员。
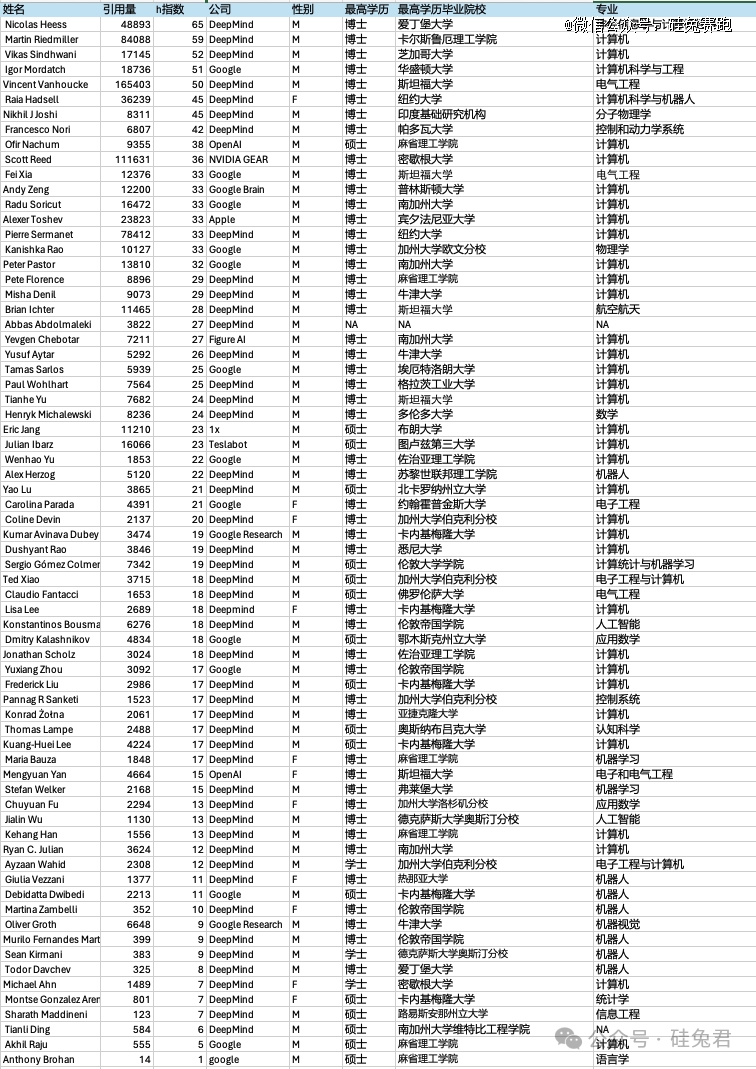
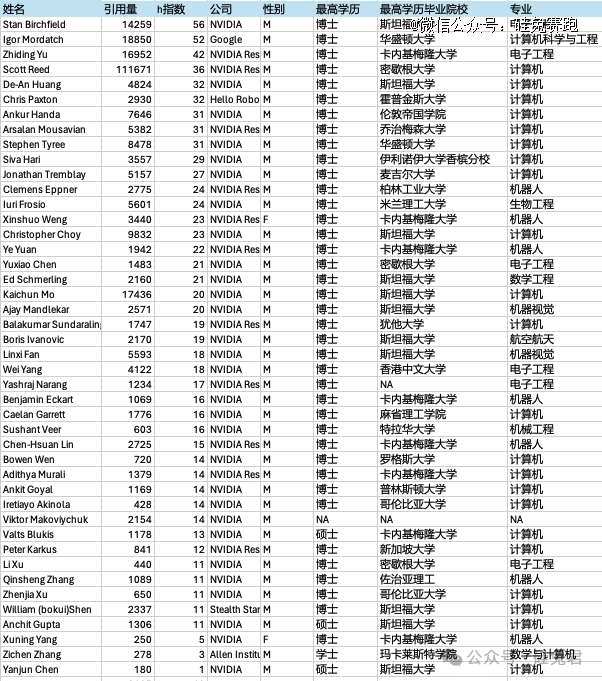
附录:谷歌、英伟达具身智能百人列表
【本文由投资界合作伙伴微信公众号:硅兔赛跑授权发布,本平台仅提供信息存储服务。】如有任何疑问,请联系(editor@zero2ipo.com.cn)投资界处理。




