
在DeepSeek V3一个月前惊艳亮相后,它背后的“能量来源”DeepSeek R1系列正式发布。
1月20日,DeepSeek在Huggingface上上传了R1系列的技术报告和各种信息。
按照DeepSeek的介绍,它这次发布了三组模型:1)DeepSeek-R1-Zero,它直接将RL应用于基座模型,没有任何SFT数据,2)DeepSeek-R1,它从经过数千个长思想链(CoT)示例微调的检查点开始应用RL,和3)从DeepSeek-R1中蒸馏推理能力到小型密集模型。
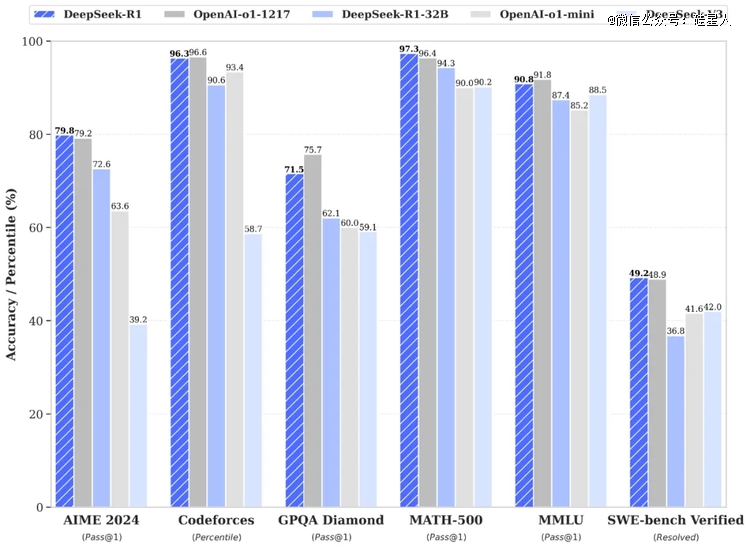
DeepSeek-R1在AIME2024上获得了79.8%的成绩,略高于OpenAI-o1-1217。在MATH-500上,它获得了97.3%的惊人成绩,表现与OpenAI-o1-1217相当,并明显优于其他模型。在编码相关的任务中,DeepSeek-R1在代码竞赛任务中表现出专家水平,在Codeforces上获得了2029 Elo评级,在竞赛中表现优于96.3%的人类参与者。对于工程相关的任务,DeepSeek-R1的表现略优于OpenAI-o1-1217。
1. “RL is all you need”
此次技术报告里披露的技术路线,最让人惊叹的是R1 Zero的训练方法。
DeepSeek R1 放弃了过往对预训练大模型来说必不可少甚至最关键的一个训练技巧——SFT。SFT(微调)简单说,就是先用大量人工标准的数据训练然后再通过强化学习让机器自己进一步优化,而RL(强化学习)简单说就是让机器自己按照某些思维链生成数据自己调整自己学习。SFT的使用是ChatGPT当初成功的关键,而今天R1 Zero完全用强化学习取代了SFT。
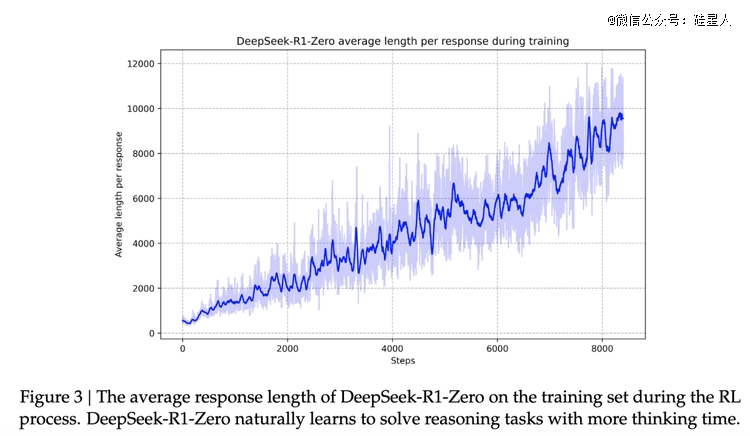
而且,效果看起来不错。报告显示,随着强化学习训练过程的进行,DeepSeek-R1-Zero 的性能稳步提升。比如,“在 AIME 2024 上,DeepSeek-R1-Zero 的平均 pass@1 得分从最初的 15.6% 跃升至令人印象深刻 71.0%,达到与 OpenAl-o1-0912 相当的性能水平。这一重大改进突显了我们的 RL 算法在优化模型性能方面的有效性。”
但R1 zero本身也有问题,因为完全没有人类监督数据的介入,它会在一些时候显得混乱。为此DeepSeek用冷启动和多阶段RL的方式,改进了一个训练流程,在R1 zero基础上训练出更“有人味儿”的R1。这其中的技巧包括:
冷启动数据引入—— 针对 DeepSeek-R1-Zero 的可读性和语言混杂问题,DeepSeek-R1 通过引入数千条高质量的冷启动数据进行初始微调,显著提升了模型的可读性和多语言处理能力;
两阶段强化学习——模型通过两轮强化学习不断优化推理模式,同时对齐人类偏好,提升了多任务的通用性;
增强型监督微调——在强化学习接近收敛时,结合拒绝采样(Rejection Sampling)和多领域的数据集,模型进一步强化了写作、问答和角色扮演等非推理能力。
可以看出来,R1系列与GPT,甚至OpenAI的o系列看起来的做法相比,在对待“有监督数据”上都更加激进。不过这也合理,当模型的重点从“与人类的交互”变成“数理逻辑”,前者是有大量的现成的数据的,但后者很多都是停留在脑子里的抽象思考,没有现成数据可以用,而寻找那些奥数大师们一个个罗列和标注他们脑子里的解题思路,显然又贵又耗时。让机器自己产生某种同样存在它自己脑子里的数据链条,是合理的做法。
论文里另一个很有意思的地方,是R1 zero训练过程里,出现了涌现时刻,DeepSeek把它们称为“aha moment”。
技术报告里提到,DeepSeek-R1-Zero 在自我进化过程中展现了一个显著特点:随着测试阶段计算能力的提升,复杂行为会自发涌现。例如,模型会进行“反思”,即重新审视并评估之前的步骤,还会探索解决问题的替代方法。这些行为并非通过明确编程实现,而是模型与强化学习环境交互的自然产物,大大增强了其推理能力,使其能够更高效、更精准地解决复杂任务。
“它突显了强化学习的力量和美丽:与其明确地教模型如何解决问题,我们只需为其提供正确的激励,它就会自主地开发先进的问题解决策略。这一“顿悟时刻”有力地提醒了强化学习在解锁人工智能新水平方面的潜力,为未来更自主、更适应的模型铺平了道路。”
2. 蒸馏,蒸馏,欢迎大家一起来蒸馏
在DeepSeek的官方推文里,所有介绍的重点并不在R1模型技巧或R1模型榜单成绩,而是在蒸馏。
“今天,我们正式发布 DeepSeek-R1,并同步开源模型权重。DeepSeek-R1 遵循 MIT License,允许用户通过蒸馏技术借助 R1 训练其他模型。DeepSeek-R1 上线API,对用户开放思维链输出,通过设置 `model='deepseek-reasoner'` 即可调用。DeepSeek 官网与 App 即日起同步更新上线。”
这是它官方发布的头几句话。
DeepSeek在R1基础上,用Qwen和Llama蒸馏了几个不同大小的模型,适配目前市面上对模型尺寸的最主流的几种需求。它没有自己搞,而是用了两个目前生态最强大,能力也最强大的开源模型架构。Qwen 和 Llama 的架构相对简洁,并提供了高效的权重参数管理机制,适合在大模型(如 DeepSeek-R1)上执行高效的推理能力蒸馏。蒸馏过程不需要对模型架构进行复杂修改,减少了开发成本。而且,直接在 Qwen 和 Llama 上进行蒸馏训练比从头训练一个同规模的模型要节省大量的计算资源,同时可以复用已有的高质量参数初始化。
这是DeepSeek打的一手好算盘。
而且,效果同样不错。
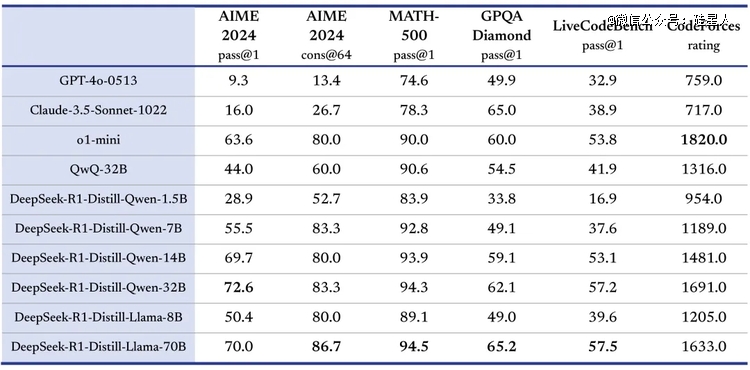
“我们在开源 DeepSeek-R1-Zero 和 DeepSeek-R1 两个 660B 模型的同时,通过 DeepSeek-R1 的输出,蒸馏了 6 个小模型开源给社区,其中 32B 和 70B 模型在多项能力上实现了对标 OpenAI o1-mini 的效果。”
此外,在技术方向上,这也给业界带来启发:
对小模型来说,蒸馏优于直接强化学习:从 DeepSeek-R1 蒸馏得到的小模型在多个推理基准(如 AIME 2024 和 MATH-500)上的表现优于直接对小模型进行强化学习。大模型学到的推理模式在蒸馏中得到了有效传递。
3. DeepSeek比OpenAI更有活力
如果简单来概括R1系列的发布,DeepSeek用巨大的算力和各类资源,训练了一个强大的底层模型——这个叫做R1 zero的模型,在训练过程里直接抛弃了GPT系列为代表的SFT等预训练技巧,直接激进地几乎全部依赖强化学习,造出了一个仅靠自己反思就拥有泛化能力的模型。
然后,因为全是“自我反思”学出来的能力,R1 zero有时候会显得学的有点杂而混乱了,为了能够让人更好使用,DeepSeek用它自己的一系列技巧来让它和真实的场景做了对齐,改造出一个R1。
然后在此基础上,不是自己蒸馏小模型而是用几个*的开源框架蒸馏出来了几个最合适尺寸的模型。所有这些都开源给外界参考和使用。
整个过程里,DeepSeek显示出很强的自己自成一派的技术路线和风格。而这种路线正在和OpenAI正面交锋。
OpenAI的o系列此前陆续传出的训练方法上,对于“对齐”基本延续着GPT系列形成的风格,此前一名OpenAI负责训练安全和对齐部分的研究员曾对我们透露,他们内部,所谓安全和与人类对齐,其实和提高模型能力是同一件事。但后来随着o3的预告,同时发生的就是这些人类安全对齐机制的研究员的集体离职。这也让这家公司的创新变得遮遮掩掩,外部看来就是慢下来,且活力减少了。
这样的对比,也让DeepSeek在这个阶段的异军突起显得更让人期待。它比OpenAI更有活力。
从DeepSeek R系列来看,它的对齐放在了R1这个模型的训练阶段里,而R1 zero更像是只追求用最*的强化学习方法自己练出强大的逻辑能力。人类反馈说喜不喜欢它,这些信息并没有太被混在最初R1 zero里面一起训练。
这继续在把“基础模型”的能力和实际使用的模型分开,最初GPT3和InstructGPT其实就是这样的思路,只不过当时是基础能力和人类偏好分开两阶段完成,现在是更抽象的基础逻辑能力和更强调实用性能和性价比的偏好。这也是为什么V3之前被发现在文科类的能力上不强的原因。
所以,与“追上o1”相比,DeepSeek R1 zero证明出来的能力,和用它蒸馏出来的V3的惊艳,以及这次它又用Llama和Qwen蒸馏出来的几个小参数模型表现出来的能力,才是这一系列动作的关键。
在与人类交互这件事上,ChatGPT因为有GPT4提供的基础能力后,实现了突破,但OpenAI选择立刻闭源,这样就只有它自己能突破。在泛化出强大的数理推理能力这件事上,DeepSeek V3因为有DeepSeek R1的强大涌现才实现突破,而DeepSeek则把它开源,选择让大家都能一起突破。
DeepSeek对OpenAI的威胁是真实的,接下来的“比拼”会越来越有意思。
【本文由投资界合作伙伴微信公众号:硅星人授权发布,本平台仅提供信息存储服务。】如有任何疑问,请联系(editor@zero2ipo.com.cn)投资界处理。





