
从微观世界的分子与材料结构、到宏观世界的几何与空间智能,创建和理解 3D 结构是推进科学研究的重要基石。3D 结构不仅承载着丰富的物理与化学信息,也可为科学家提供解构复杂系统、进行模拟预测和跨学科创新的重要工具。
如何准确且高效地构建 3D 模型、理解和生成 3D 世界正在成为 AGI、AI for Science、具身智能三大 AI 热门领域共同关注的焦点。而随着 AI 技术的发展,大型语言模型(LLM)与大型多模态模型(LMM)那强大的自回归下一 token 预测能力也已经在开始被用于创建和理解 3D 结构。基于此,我们看到了 AI for Science 的新可能。
近日,一个开创性的此类大模型诞生了。它名为Uni-3DAR,来自深势科技、北京科学智能研究院及北京大学,是一个通过自回归下一 token 预测任务将 3D 结构的生成与理解统一起来的框架。据了解,Uni-3DAR 是世界*此类科学大模型。并且其作者阵容非常强大,包括了深势科技 AI 算法负责人柯国霖、中国科学院院士鄂维南、深势科技创始人兼首席科学家和北京科学智能研究院院长张林峰等。
柯国霖在 𝕏上分享表示:Uni-3DAR 的核心是一种通用的粗到细 token 化方法(coarse-to-fine tokenization),它能将3D结构转化为一维的 token 序列。


基于这套通用的 token 化方法,Uni-3DAR 使用自回归的方式,统一了 3D 结构的生成和理解任务。大量实验表明,Uni-3DAR 在分子生成、晶体结构生成与预测、蛋白结合位点预测、分子对接和分子预训练等多个任务中均取得了*性能。尤其在生成任务中,相较于现有的扩散模型,其性能实现了高达256%的相对提升,推理速度提升达21.8倍,充分验证了该框架的有效性与高效性。此外,此模型不仅可以用在微观的 3D 分子,也可以用到宏观的 3D 任务上,具备跨尺度的能力。
具体来说,Uni-3DAR 解决了 3D 结构建模里的两个痛点:
*,数据表示不统一。当前的3D结构存在多种表示方式,尤其在不同尺度下差异显著。宏观结构常用点云、网格(Mesh)等表示方式,而微观结构则多采用原子坐标或图结构。这些表示方式的差异导致建模思路截然不同。即使在同一尺度,由于数据特性的差异,不同类型的结构(如晶体、蛋白质、分子)也往往采用各自专用的表示与模型,难以兼容。这种表示上的割裂严重限制了模型的通用性,也阻碍了构建可借助大规模数据训练的通用基础模型的可能性。
第二,建模任务不统一。3D结构相关任务可分为生成和理解两大类,但它们各自独立发展。生成任务多依赖扩散模型,从随机噪声逐步合成稳定结构,而理解任务则主要基于无监督预训练方法。相比之下,大型语言模型(LLM)已通过自回归方式成功实现了生成与理解任务的统一,但这种统一范式在3D结构建模领域仍然鲜有尝试。若能借助自回归方法统一 3D 任务建模,不仅有望打通理解与生成的界限,更可能将 3D 结构纳入多模态大语言模型的处理范式,继图像和视频之后成为 LLM 可理解的新模态,为构建面向物理世界的通用多模态科学模型奠定基础。
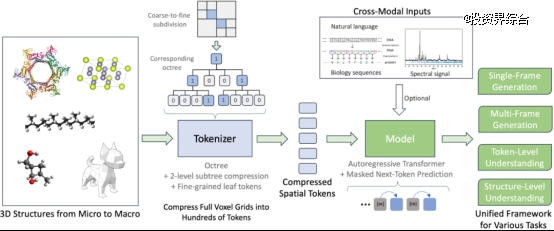
下面我们具体解读下这篇论文的两个核心技术。
Compressed Spatial Tokens统一微观与宏观 3D 结构
3D 结构在微观(如原子、分子、蛋白质)和宏观(如物体整体、力学结构)层面均表现出显著稀疏性:大部分空间为空白,只有局部区域含有重要信息。传统的全体素网格表示计算资源消耗巨大,无法利用这种稀疏性。
为此,Uni-3DAR 提出了一种层次化、由粗到细的token 化方法,实现了数据的高效压缩和统一表示,既适用于微观也适用于宏观3D结构建模,为后续的自回归生成与理解任务提供了坚实基础。
1. 层次化八叉树压缩
该方法首先利用八叉树对整个3D空间进行无损压缩。具体做法是从包含整个结构的一个大格子开始,针对非空格子(即包含原子或其他结构信息的区域),递归地将其均分为 8 个等大小的子单元。经过多层细分后,形成一个由粗到细的层次结构,其每一层的 token 不仅记录了区域是否为空,还保留了该区域的空间位置信息(由所在层次及格子中心坐标确定),为后续的自回归生成提供了明确的空间先验。
2. 精细结构 token 化
虽然八叉树可以有效压缩空白区域,但它仅提供了粗粒度的空间划分,无法捕捉到诸如原子类型、精确坐标(在微观结构中)或物体表面细节(在宏观结构中)等重要信息。
为此,该团队在最后层非空区域内进一步引入了「3D patch」的概念 —— 类似于图像领域中的 2D patch 的处理。通过将局部结构细节进行离散化(例如采用向量量化技术),将连续的空间信息转化为离散的 token。这样一来,无论是描述微观尺度下单个原子的信息,还是刻画宏观尺度下物体表面的细节,都能以同一形式进行表示。
3. 二级子树压缩
由于即使在八叉树结构下,token数量仍可能较多,该方法进一步提出了二级子树压缩策略。具体来说,将一个父节点及其 8 个子节点的信息合并为一个单一的token(利用父节点固定状态以及子节点的二值特征,共可组合成 256 种状态),从而将token总数约降低 8 倍。这不仅大幅提高了计算效率,也为大规模3D结构的高效建模提供了可能。综上,该方法充分利用了3D结构固有的稀疏性,通过八叉树分解、精细token化与二级子树压缩,不仅大幅降低了数据表示的复杂度,而且实现了从微观到宏观3D结构的统一表示,为后续自回归生成与理解任务提供了高效、通用的数据基础。
Masked Next-Token Preiction统一生成和理解的自回归框架
在传统自回归模型中,token的位置是固定的 —— 例如在文本生成中,第 i 个token后总是紧接着第 i+1 个token,因此下一个token的位置可以直接推断,无需显式建模。
然而,在该论文提出的粗到细3Dtoken化方法中,token是动态展开的,其位置在不同样本间存在较大变化;如果不显式提供位置信息,自回归预测的难度将大大增加。为此,该论文提出了 Masked Next-Token Prediction 策略。
具体而言,该方法对每个token复制一份,确保两个副本具有相同的位置信息,然后将其中一个副本替换为 [MASK]token。在自回归预测过程中,由于被掩码token与目标token的位置信息完全一致,模型能够直接利用这一明确的位置信息来预测下一个token的内容,从而更精确地捕捉下一个token的位置特征,提高预测效果。尽管复制token使序列长度翻倍,但实验结果表明,该策略显著提升了性能,而推理速度仅下降 15% 至 30%。
基于 Masked Next-Token Prediction,该论文构建了一个统一的自回归框架,使得 3D 结构的生成与理解任务能够在单一模型内同时进行。
具体来说,生成任务(包括单帧与多帧生成)在被掩码的token上执行,利用自回归机制逐步构建结构;token级理解任务(如原子级属性预测)则依托精细结构token进行;而结构级理解任务则引入了一个特殊的 [EoS](End of Structure)token,用于捕捉整体结构的全局信息。
此设计使不同任务对应的token在模型内部彼此独立、互不干扰,从而支持联合训练。同时,自回归特性也便于将其他模态数据(例如自然语言文本、蛋白质序列、仪器信号等)统一到单个模型,进一步提升模型的泛化能力和实用性。
实验结果
该论文在微观3D结构领域设计了一系列任务,包括分子生成、晶体结构生成与预测、蛋白结合位点预测、蛋白小分子对接以及基于预训练的分子性质预测。
实验结果显示,在生成任务中,Uni-3DAR 的性能大幅超过了扩散模型方法;而在无监督预训练的理解任务上,其表现与基于双向注意力的模型基本持平。这些成果充分证明,Uni-3DAR 不仅能统一不同类型的3D结构数据及任务,而且在效果和速度上均实现了显著提升。
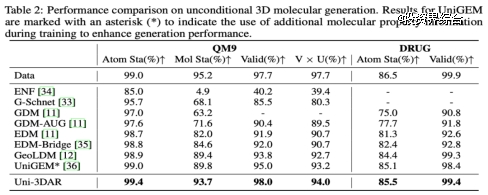
3D 小分子生成任务性能
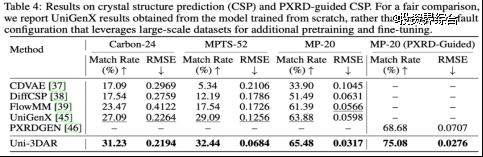
晶体结构预测,以及基于多模态信息(粉末 X 射线衍射谱)的晶体结构解析性能
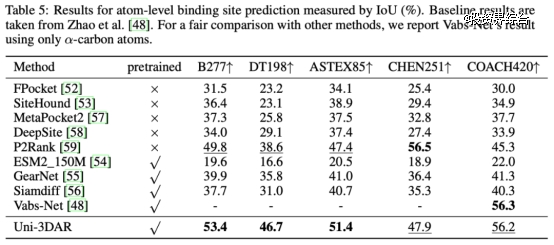
蛋白结合位点预测效果
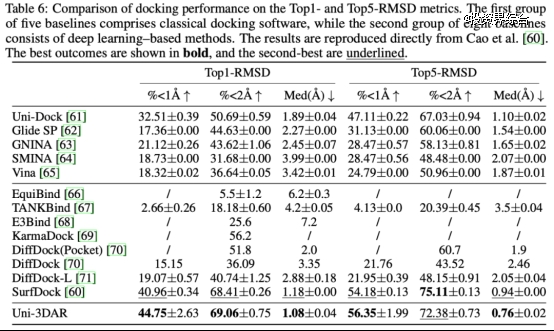
蛋白小分子对接效果
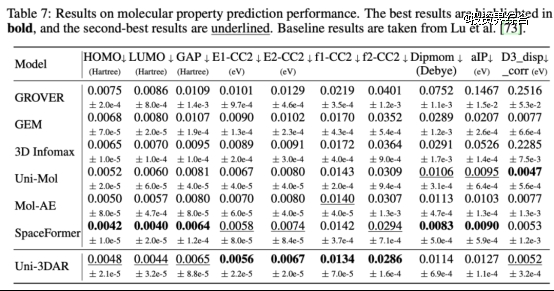
基于预训练的小分子属性预测效果,其中 Uni-Mol 和 SpaceFormer 也为深势科技提出的专用模型,Uni-3DAR 超过了 Uni-Mol,与 SpaceFormer 基本持平
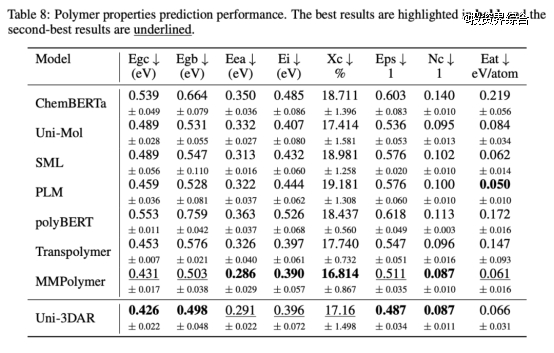
基于预训练的高分子聚合物性质预测,其中 Uni-Mol 和 MMPolymer 也为深势科技提出的专用模型,Uni-3DAR 超过了 Uni-Mol,与 MMPolymer 基本持平
未来展望目前,Uni-3DAR 的实验主要集中在微观结构领域,因此亟需在宏观 3D 结构任务中进一步验证其通用性和扩展性。此外,为保证与以往工作的公平对比,当前 Uni-3DAR 在每个任务上均采用独立训练。未来的一个重要方向是融合多种数据类型与任务,构建并联合训练一个更大规模的 Uni-3DAR 基座模型,以进一步提升性能与泛化能力。同时,Uni-3DAR 还具备天然的多模态扩展潜力。后续可以引入更多模态的信息,例如蛋白质序列、氨基酸组成,甚至结合大语言模型与科学文献知识,共同训练一个具备物理世界理解能力的多模态科学语言模型,从而为构建通用科学智能体打下基础。





