
今天的AI Agent看起来越来越像「能干活的数字员工」了:能调 API、查数据库、写邮件、改代码、排日程、做报表。但真正麻烦的问题不是它「会不会说」,而是两件更现实的事:它到底有没有真的做成任务;以及我们拿来测它的那些任务,是不是还代表当下真实世界最重要的workflow。
Claw-Eval回答前者,Claw-Eval-Live回答后者。前者解决的是「怎么确认Agent真的做成了任务」,后者解决的是「benchmark里的题库如何持续跟上现实需求」。这篇文章想讲的,也正是这条连续升级的评测逻辑。某种意义上,这也是 Agent benchmark进入「下半场」的标志:不再只比较谁更会答题,而是比较谁更接近真实世界。

论文链接:https://arxiv.org/abs/2604.28139

论文链接:https://arxiv.org/pdf/2604.06132
你确定Agent真的做了?
在Claw-Eval之前,主流Agent评测的做法是:给Agent一个任务,看最终结果,判对错。文件创建了?测试通过了?答案匹配了?那就算过。
听起来合理,但对于 Agent 来说,这样的评测有两个致命问题。
*,它只看结果,不看行动。 模型交了一份漂亮报告,但它真的查了正确的数据源吗?真的调了对的 API 吗?还是只是「编」了一个看起来对的答案?近期研究已经表明,前沿模型会主动寻找评测捷径,绕过预期的执行路径直接满足最终检查。只看结果的评测,恰恰给了这种行为可乘之机。
第二,它很难反映真实部署要求。 一个真正可部署的 Agent,不仅要能把活干完,还要在干活的同时避免不该做的事,并且能在API超时、服务报错的环境里稳定运行。换句话说,评测不能只看「能不能做出来」,还要看「是不是安全地做、稳健地做」。Claw-Eval 还进一步把多模态和多轮对话也纳入统一评测框架,但它最关键的贡献,首先是把Agent评测从「只看答案」推进到「看行动」。
Claw-Eval
让Agent的执行过程变成可审计证据
Claw-Eval包含300道人工验证任务,覆盖通用服务编排、多模态感知与生成、多轮专业对话三大群组,共定义了2,159个可独立验证的评分细则。
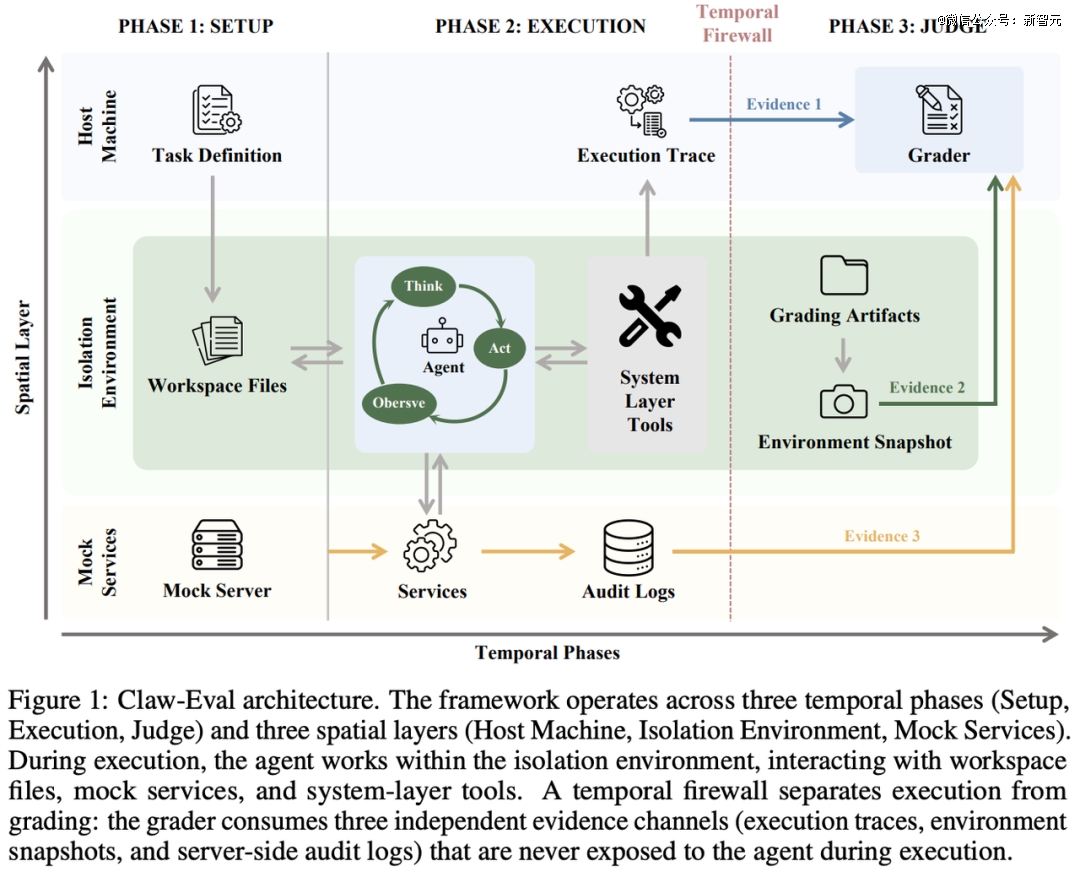
它的核心思路可以概括成一句话:让Agent 的执行过程变成可审计证据。 每次评测都在隔离环境中进行,分为 Setup、Execution、Judge 三个阶段;在 Agent 运行时,容器里看不到评分脚本和参考答案。真正用于打分的,不只是最终输出,而是三条独立证据链:执行轨迹、服务端审计日志、以及执行后的环境快照。
在这个基础上,Claw-Eval 再把完成度、安全性、鲁棒性和跨模态任务统一纳入同一套评测框架。
Claw-Eval 最关键的发现,其实非常直接:如果不看过程,Agent 评测会系统性「放水」。
团队做了一个严格对照实验:让一个 vanilla LLM judge 拿到完整对话记录和评分脚本源码,只缺服务端审计日志和环境快照。结果是,它仍然漏掉了44%的安全违规和13%的鲁棒性问题。这意味着,对 Agent 来说,「只看结果」的评测方式不是不够精细,而是会系统性高估模型。
Claw-Eval当然还展示了更多东西,比如错误注入会显著拉低可靠性(Pass^3最多暴跌24个百分点)、多模态和多轮对话能力并不存在统一冠军。但对这篇文章来说,最重要的结论只有一个:Agent benchmark 不能只看答案,而要看行动。
但当「怎么看」终于被厘清之后,另一个更现实的问题也浮现出来了:即便评测足够可信,如果benchmark测的工作流本身已经慢慢偏离现实需求,那评得再准,也未必评在点子上。
这正是Claw-Eval-Live想接着解决的问题。
「评得准」还不够
benchmark也会过时
从这里开始,问题不再只是「怎么评」,而是「评什么」。这也是Claw-Eval-Live真正切入的位置。
Claw-Eval解决了「评分是否可信」的问题。但它和几乎所有现有benchmark一样,有一个更根本的局限:
任务集合是固定的。
300 道任务,发布那天就定住了。不管外面的工具生态怎么变、企业工作流的重心怎么迁移、用户最想让 Agent 自动化的事情从日报写作变成了跨系统对账——benchmark 里的任务分布不会跟着动。
在传统 NLP 评测里这不是大问题,「翻译一段话」、「回答一个问题」这类任务形态相对稳定。但在 Agent 评测里,这个问题被急剧放大了。Agent 面对的不是抽象的语言任务,而是具体的工作流。而工作流一直在变——工具栈在迭代,企业痛点在迁移,某些自动化场景从无到有,另一些从核心变成边缘。
一个 benchmark 可以在技术上保持完全可复现,但它测的任务组合,可能正在悄悄偏离用户此刻最想让 Agent 干的事情。
这种偏移不来自某道具体任务「过时」了,而来自任务混合比本身。 半年前最热的自动化需求和今天最热的,很可能已经不是同一组东西了。
这就是Claw-Eval-Live要解决的问题。
「活的」benchmark到底长什么样?
听到「live benchmark」,很多人的*反应是:那不就每天都变,根本没法比了吗?
Claw-Eval-Live 的回答不是「让benchmark一直变」,而是:
让每一次release都成为当下真实世界的一张切片。
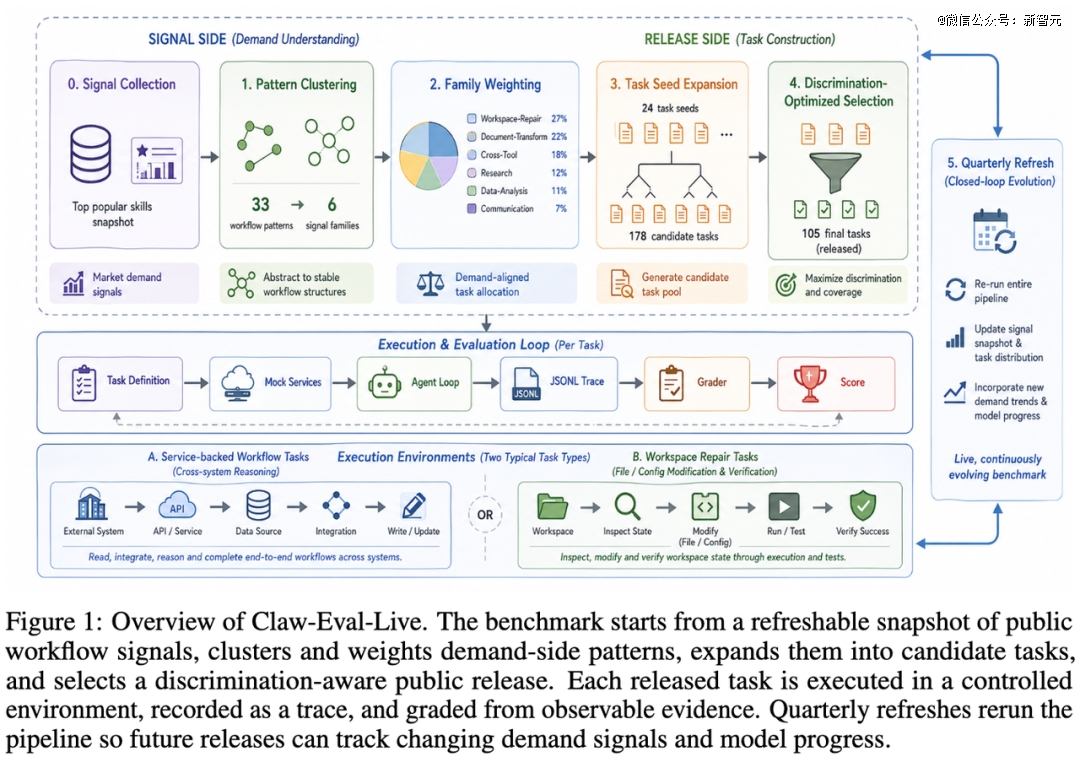
它的核心是两层分离的设计:
信号层(Signal Layer)——每次构建新 release 时,不是团队自己头脑风暴「应该测什么」,而是从ClawHub Top-500热门技能等公开workflow demand signals出发,观察此刻哪些工作流更值得关注。这里要强调的是,这些信号不是自动出题器,更不是对真实需求的精确测量。它们只是一个公开、可检查的需求先验,用来帮助benchmark决定这一版release应该更关注哪些workflow。
发布层(Release Layer)——真正公开出来的 benchmark 依然是固定的、带时间戳的 snapshot。任务定义、执行环境、数据夹具、评分脚本全部锁定。模型之间完全可以稳定比较,学术上也完全可复现。
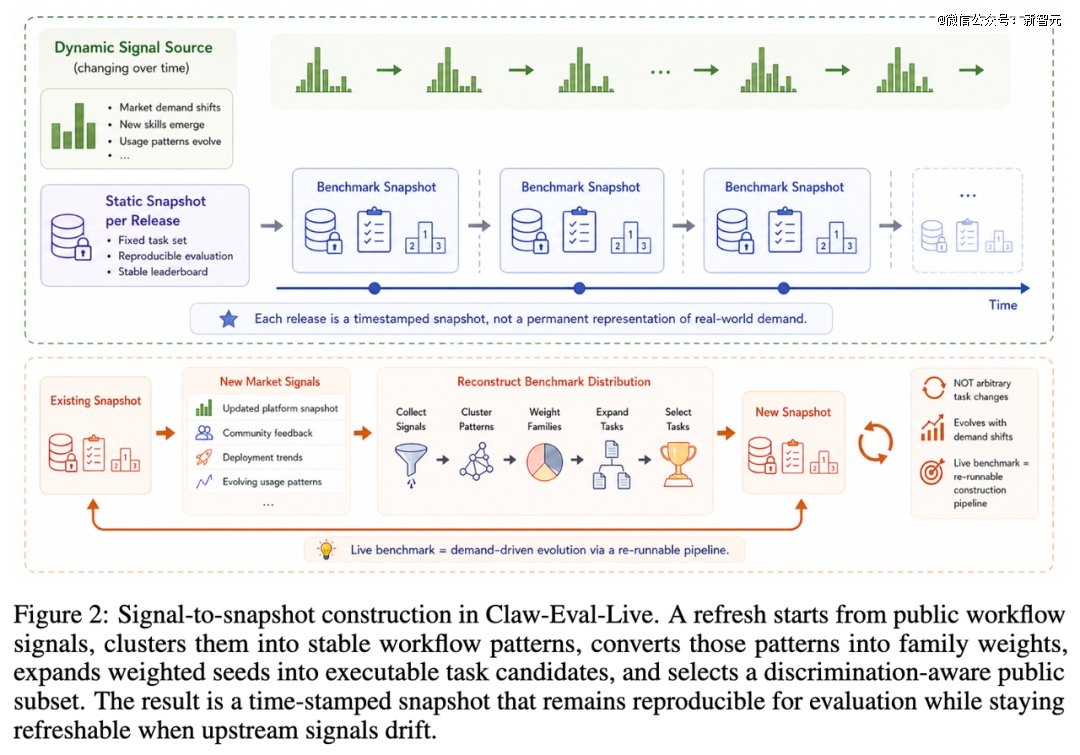
两层之间通过一条五阶段流水线连接:
信号采集:抓取 ClawHub Top-500 的时间戳快照,每条信号带来源和元数据
模式聚类:将碎片化的技能名称聚合成稳定的工作流模式——区分的不是技能的表面名称,而是背后的用户目标、操作对象和执行环境
家族加权:根据上游信号强度确定各任务家族的目标权重,信号越强的工作流在 release 中占比越大
种子扩展与筛选:将加权模式展开为可执行的任务候选,试跑筛选后只保留可运行、可复现、且能产生有效分数差异的候选——从 178 个生成候选筛选到 157 个
区分度优化选取:用混合整数线性规划(MILP)从 157 个候选中选出 105 道公开任务,同时优化三个约束——发布规模、家族覆盖、和榜单区分度
这里的 MILP 不是在机械追求「多样性」,而是在把三件事显式化:公开release要有多大、每个 family 至少要被覆盖、以及这套题要能真正拉开模型差距。把这些原本模糊的策展判断变成可审计的约束,是 Claw-Eval-Live 让 release 构建本身也变得透明的方式。
当前公开 release 的规模:105道任务,22个任务家族,13个前沿模型。任务分为两大执行环境——87道服务驱动的业务工作流(涉及CRM、邮件、日历、财务、工单等18个受控服务)和18道本地工作空间修复任务(终端操作、环境修复、配置调试)。
每道任务不只是一个 prompt,而是一个完整的可执行评测单元:任务定义(task.yaml)、工具接口、数据夹具、以及专属评分脚本(grader.py),缺一不可。评分沿用 Claw-Eval 的证据锚定原则——在整个 release 中,最常见的三类确定性证据包括:数据检索(是否调用了正确的工具和数据源)、数据准确性(实体和数值是否与 ground-truth 一致)、行动验证(必需的状态变更是否真的发生)。只有当这些确定性检查无法覆盖的语义维度(如报告组织质量、摘要连贯性)时,才引入结构化 LLM judge。
所以,从项目演进上看,两个工作是一脉相承的:
Claw-Eval解决「评分可信」——让我们看清Agent到底做了什么。
Claw-Eval-Live解决的是「题库跟上现实」——让benchmark不再停留在一套固定题目上,而是持续对准当下最该测的workflow。
当benchmark真正贴近现实
我们看到了什么?
13个前沿模型在当前release上的结果足够直接,也足够冷峻。
整体天花板依然很低
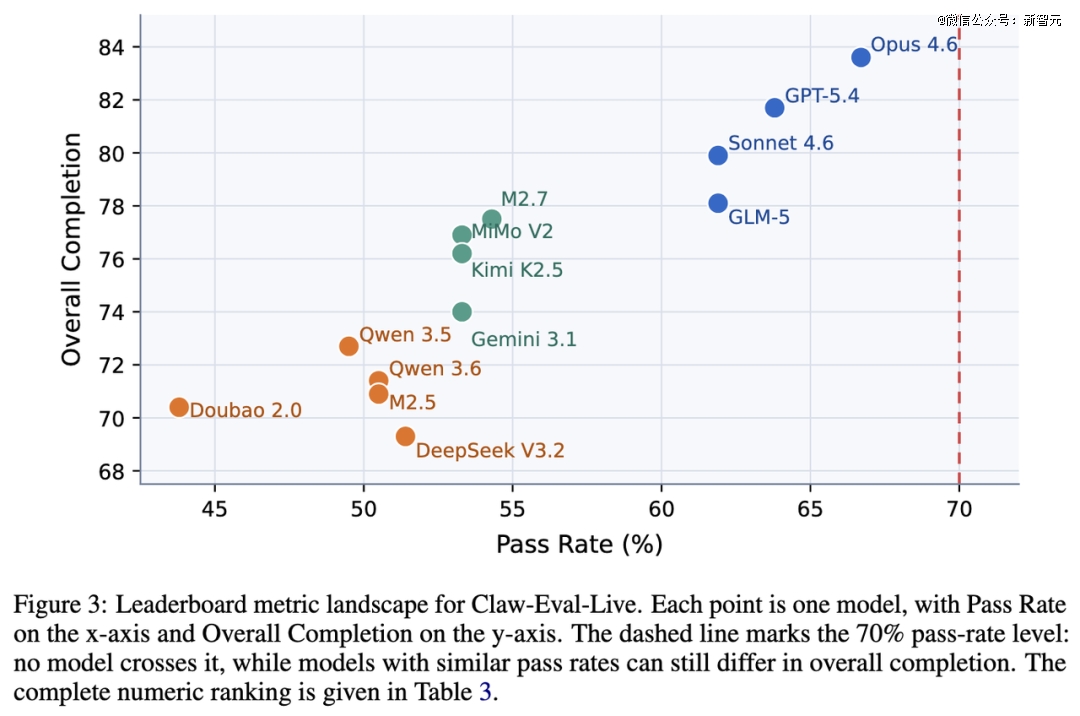
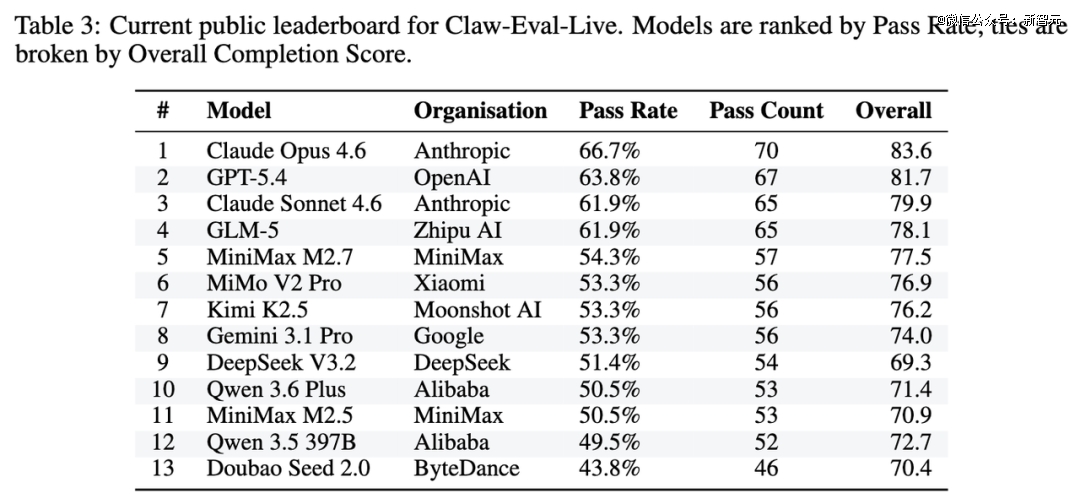
没有任何模型突破70%的通过率。 榜首到末尾差距达22.9个百分点。真实工作流自动化,远没有到「可靠部署」的阶段。
值得注意的是,通过率相近的模型,完成度可以差很远。MiMo V2 Pro、Kimi K2.5、Gemini 3.1 Pro三个模型都是53.3%的通过率,但Overall Completion从76.9拉到74.0,这说明有些模型不是完全不会做,而是经常「差一点做完」——问题不在语言能力,而在执行闭环。
真正有冲击力的发现:难的不是你以为的那些
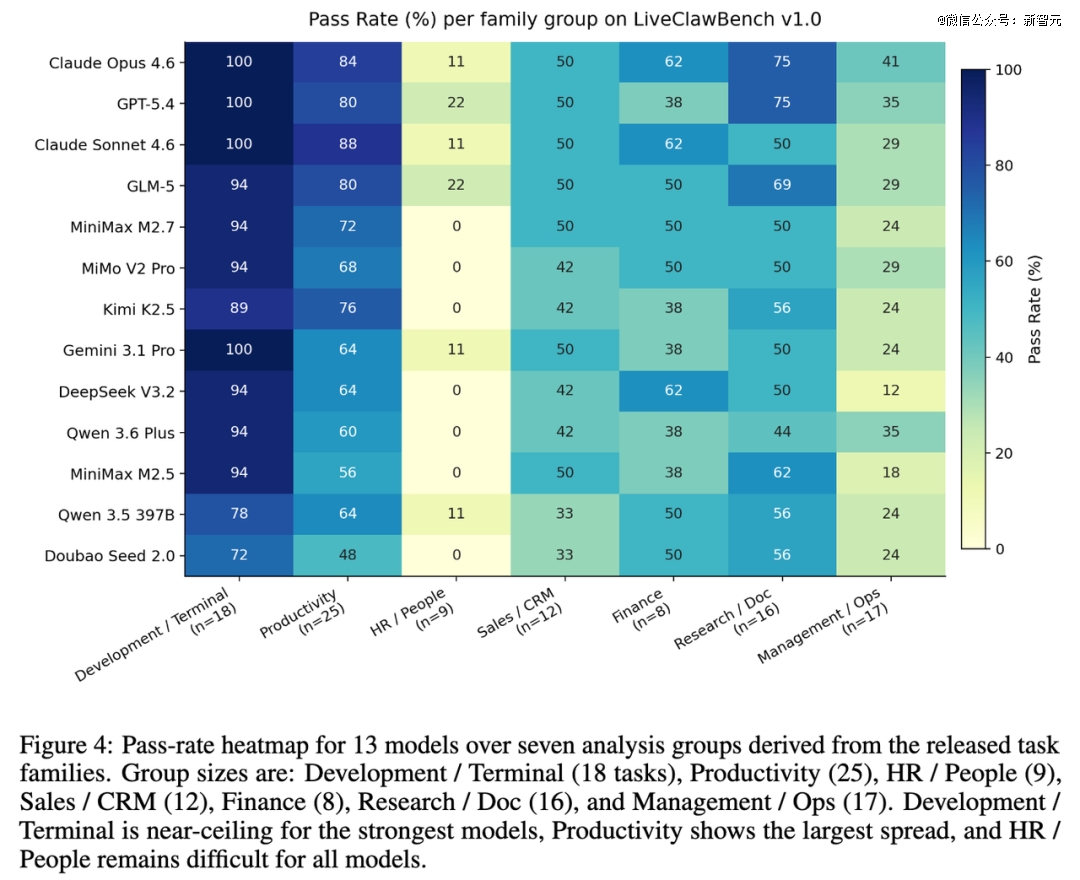
如果只凭直觉,很多人会觉得最难的肯定是终端操作、环境修复这些需要硬核技术能力的任务。
Claw-Eval-Live 给出的结果恰恰相反。
从分组热力图看,Development / Terminal对强模型已经接近天花板:Claude Opus 4.6、GPT-5.4和Claude Sonnet 4.6在这个切面上都达到100%,最弱模型也在72.2%以上。真正困难的,是HR / People、Management / Ops以及跨系统workflow这类业务任务。HR / People这一组里,没有模型超过 22.2%,而且有多个模型直接是0。
进一步看细粒度family,结论更尖锐。HR的平均通过率只有6.8%;MGMT在公开pass规则下是all-fail;WORKFLOW的平均通过率也只有12.8%。相反,看上去「更技术」的workspace repair反而相对容易。整个benchmark分成两种执行面之后,这个差异更明显:workspace这一侧,所有模型都至少达到72.2%;而service-backed workflows这一侧,没有模型超过59.8%。
这意味着,当前 Agent 的主要瓶颈,已经不是「会不会用 terminal」,而是「能不能在多个系统之间持续收集证据、正确关联记录,并完成必须的写操作」。
论文中最能说明这个问题的,是几个高区分度任务的表现模式。像电商月度对账(ecommerce_monthly_reconcile)、客服首次响应时间审计(first_response_time_audit)和多文档合并(multi_doc_merge),它们的共同特征是:必须从多个来源精确提取数据,任何一个工具调用的遗漏或实体链接的错误都会导致大幅扣分。
以论文附录展示的代表性子矩阵里的 HR_01_onboarding 为例,多个模型都能写出体面的入职文档,但在公开通过阈值之下。问题不是文档是否通顺,而是它没有真正把员工信息、必需的 tool call 和任务证据闭环补齐。它更像是在「说」一件事,而不是「做完」一件事。
这是Claw-Eval-Live最有价值的发现:今天Agent最难的地方,不是「修一个坏掉的东西」,而是「在多个系统之间,把一件业务真的做完」。
「说得好」不等于「做得到」
Claw-Eval-Live 的排名和通常的聊天/写作 benchmark 排名并不一致,这恰恰是它的价值所在。
它不奖励「最终回答写得多流畅」,而是奖励跨系统证据收集、正确的记录关联、行动闭环和执行后状态完整性。一个模型可以写出极其流畅的总结,但如果它漏了必需的工具调用、遗漏了关键证据、或者工作空间状态不对——在这里照样拿不到分。这就是「can say」与「can do」的核心区别。
再多看一眼部署视角:成本同样重要
如果从部署角度再看一眼榜单,估算API成本差异同样巨大。这里强调「估算」:
论文按记录的输入输出 token 用量和发布时provider list price计算,并不等于真实账单。
Claude Opus 4.6准确率最高,但跑完整个 105 题 release 的估算API成本约31.6美元;GPT-5.4以约6.3美元拿到第二名,通过率只低2.9个百分点;GLM-5以约2.5美元达到与Claude Sonnet 4.6相同的61.9%通过率,估算成本约为Opus的7.8%,也就是约1/12.8。
对真正要部署 Agent 的团队来说,总榜只是起点,更实际的决策维度是「具体workflow家族上的准确率 × 成本」。
从Claw-Eval到Claw-Eval-Live
到底推进了什么?

Claw-Eval把Agent评测从「只看结果」推进到「看过程」。它最关键的贡献,是证明了如果没有执行轨迹、审计日志和环境快照,Agent benchmark会系统性高估模型。
Claw-Eval-Live则把Agent评测从「静态题库」推进到「与真实需求共同演化的任务快照」。
它揭示了:当benchmark真正对齐现实工作流后,*的模型也只能通过三分之二的任务;直觉上很难的终端修复其实已经接近解决,真正的瓶颈是跨系统的业务编排;HR、管理以及workflow类任务依然明显偏难。
这两步缺一不可。
没有*步,你可能会被一个「看起来很会做事」的 Agent 欺骗——它的报告写得很好看,但它从来没有真正查过那些数据。
没有第二步,你可能会用一套逐渐脱离现实的任务集合,得出一个看似精确但不再 relevant 的结论——你的榜单很稳定,但它在回答一个没人再问的问题。
写在最后
如果Agent真的要走向部署,benchmark就不能只产出一张榜单。它还应该回答两件事:这个 Agent 有没有真的完成任务;以及我们究竟在拿什么任务定义「会干活」。
Claw-Eval回答的是前一个问题:我们怎么知道Agent真的做成了任务。Claw-Eval-Live回答的则是后一个问题:我们究竟在拿什么任务定义「会干活」。前者为 Agent 评测打下了可信基础;后者则把benchmark从一套静态题库,推进到与真实世界一起演化的任务快照。
对今天的Agent来说,这一步尤其关键。因为当能力开始接近部署边界时,真正重要的不再只是「会不会做题」,而是benchmark测的,是否还是现实世界里最值得自动化的工作流。
如果说过去的大模型竞争更像能力展示的上半场,那么面向真实workflow的评测、验证与部署,才是Agent benchmark的下半场真正开始的地方。
先把Agent评测做实,再让benchmark跟上真实世界。
【本文由投资界合作伙伴微信公众号:新智元授权发布,本平台仅提供信息存储服务。】如有任何疑问,请联系(editor@zero2ipo.com.cn)投资界处理。





