

6月,北京智源大会现场,围绕具身智能的技术路线之争再次成为行业焦点。过去一年,随着机器人产业快速升温,一个问题持续引发讨论:机器人究竟应该走VLA路线,还是世界模型路线?
对此,作为本次大会具身产业CEO论坛的首位开场主旨演讲嘉宾,智平方创始人兼CEO郭彦东博士一上台便化身“终结者”,对这一行业争论抛出明确答案:
世界模型不是VLA的竞争路线,而是VLA体系中的核心组成部分;而在世界模型与VLA融合之后,类脑架构将成为下一代机器人大脑的重要演进方向。
这一判断背后,也对应着智平方过去三年持续高压强的技术布局——从端到端VLA,到融合世界模型,再到最新发布的类脑大模型NeuroVLA,一条清晰的机器人大脑进化路线正在成型。
终结世界模型与VLA之争
世界模型无疑是当下全球具身智能领域最热门的话题之一。
不少研究者认为,机器人首先需要建立对物理世界的理解能力,才能进一步产生可靠行为;也有人认为,VLA直接从视觉和语言生成动作,是更高效、更现实的技术路径。
郭彦东博士认为,从生命演化的角度来看,行动能力并不是孤立产生的。生命首先需要感知环境、理解环境,然后才会产生行动。
换句话说,世界模型负责理解世界,而VLA负责作用于世界,两者并非对立关系,而是天然统一的整体。
他在演讲中指出,当前被广泛讨论的“世界模型”,本质上并不是物理规律驱动,而是靠海量数据训练出来的。“数据足够多,模型就知道水杯越过桌面会下落、手机屏幕用力敲可能会碎——这不是物理规律的总结,而是大数据学习的结果。”
基于这一判断,郭彦东重新给出了VLA的定义:VLA是多种模态融合的大数据驱动的端到端模型架构的总称。在这个定义下,世界模型与VLA没有本质区别,更不是替代关系。
“世界模型解决的是对物理环境进行稠密、包含时间维度的4D预测,它是一个非常好的空间基础模型,是VLA空间感知的一部分,能帮助机器人大脑越来越好。”
他进一步用具体任务解释了为什么两者必须融合:“如果不把世界模型合并在VLA里面,很多任务完全做不了。比如泡茶要先拿茶包再倒水,做咖啡要先拿杯子再接水——这些推理认知逻辑靠语言模型更容易完成。世界模型擅长的是短程预测,比如水杯靠近桌边可能掉落。只有把两者合并,机器人才既能做短程物理预测,又能做长程任务规划。”
除了在VLA中融合世界模型的预测能力,智平方还利用世界模型生成真实环境中难以采集的边缘数据(corner case)。“比如采集杯子数据时,采集到的可能都是桌子中间的,忘记采集桌子边缘的。这时就可以用世界模型生成桌子边缘的样本,来补足VLA。”
基于这一判断,智平方很早便开始推动世界模型与VLA的融合研究。
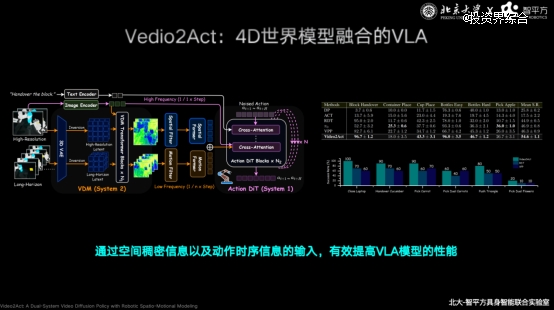
2025年11月,智平方联合北京大学率先推出融合世界模型的新一代架构Video2Act,首次实现“先预测、后执行”的机器人模型范式。
在智平方看来,世界模型最 大的价值从来不是生成视频,而是生成行动。
机器人不仅需要预测未来会发生什么,更需要基于这种预测决定下一步应该做什么。
因此,Video2Act并非传统意义上的视频生成模型,而是一个融合4D世界模型的VLA架构。通过空间稠密信息建模以及动作时序的持续输入,机器人能够提前理解未来状态变化,并将这种预测能力直接转化为行动决策。
这是世界模型第 一次真正成为机器人行动系统的一部分。
在第三方评测中,Video2Act相较于硅谷同类标杆模型取得超过30%的性能领 先。
更值得关注的是,2026年,由英国皇 家两院院士、图灵人工智能世界领 先研究员Philip Torr、强化学习领域奠基者Pieter Abbeel等全球顶 级学者联合完成的世界模型权威综述《World Model for Robot Learning: A Comprehensive Survey》中,Video2Act被作为“世界模型+VLA融合路线”的代表性成果重点引用。
这意味着,关于“世界模型还是VLA”的争论,正在被新的技术范式所取代。
真正重要的问题已经不再是谁替代谁,而是谁能够率先实现两者的深度融合。
世界模型与VLA融合之后,下一代机器人大脑来了
如果说世界模型与VLA的融合解决了机器人“看懂世界”的问题,那么机器人如何像人一样稳定、高效地行动,则成为新的挑战。
这也是智平方近期重点突破的方向。
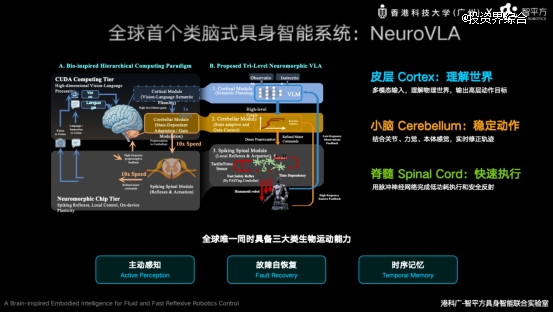
在智源大会上,郭彦东重点介绍了智平方最新发布的类脑具身智能系统NeuroVLA,目前唯 一同时具备主动感知、故障自恢复与时序记忆三大类生物运动能力的具身智能系统。
他提出一个观点:
“大家做人形机器人,天天想着如何长得像人,但没有人想如何让脑子更像人。”
在现有VLA架构中,机器人虽然已经具备较强的理解能力,但面对真实世界的复杂环境,仍然普遍存在响应慢、动作抖动、能耗高等问题。
原因在于,大多数机器人仍然依赖一个统一的大模型同时处理感知、推理与控制。
而人类大脑并不是这样工作的。
人脑中,皮层负责思考,小脑负责协调运动,脊髓负责本能反射,不同系统在不同时间尺度上协同运作。
借鉴这一机制,智平方构建了全球首 个“皮层—小脑—脊髓”三级类脑架构NeuroVLA。
其中,皮层负责语义理解和任务规划;小脑负责高频运动协调与动态修正;脊髓则负责毫秒级运动执行与安全反射。
这一设计让机器人首次具备了类似生物系统的层级智能能力,从架构层面提升机器人在真实物理世界中的稳定性、实时性与能效。
实验结果显示,NeuroVLA能够将机器人运动抖动降低75%以上,在碰撞发生后20毫秒内完成反射响应,同时显著降低系统功耗。

对于机器人而言,这些数字背后意味着一次质变。
过去的机器人能够思考,却难以流畅行动。未来的机器人不仅能够思考,还能够像人一样即时反应、自主修正和持续适应。
机器人开始从“会推理”,走向“会本能反应”。
从某种意义上说,NeuroVLA所解决的已经不再是简单的模型问题,而是机器人大脑架构问题。
它试图回答的是:机器人如何拥有真正接近生物系统的智能。
而这正是类脑智能的价值所在。
从端到端VLA,到Video2Act,再到NeuroVLA。过去三年,智平方持续围绕机器人大脑进行系统性创新。

如果说VLA让机器人拥有了行动能力,世界模型让机器人拥有了理解和预测能力,那么NeuroVLA则进一步赋予机器人接近生物系统的反应与控制能力。
这三次演进背后,其实对应着同一个方向:
如何让机器人拥有一个更像人脑的“大脑”,让机器人越来越接近真正的人类智能。
在本次智源大会的舞台上,郭彦东给出的不仅是一套技术方案,更是一条关于下一代机器人大脑的演进路线。
【免责声明】:本文不构成任何投资建议。市场有风险,投资需谨慎。
如有任何疑问,请联系(editor@zero2ipo.com.cn)投资界处理。





