
以布里斯托市A38路旁的喷泉池为起始点,你需要花用不到20分钟时间,就可以骑自行车“冲”出这座英国西南部城市的CBD,进入几乎只有成排英式平房、灌木丛和河道的郊外。
没错,即便布里斯托(Bristol)是名副其实的英国西南部中心,但从城市规模来看,但它依然被很多中国留学生起了一个非常清新脱俗的名字——“布村”。( “除了伦敦,其他都是村儿”。)
然而,如今接触芯片产业后,我们才恍然发现,这座古老的英国小城,竟然藏着英国最强大的半导体产业集群之一。
1972年,硅谷大名鼎鼎的仙童半导体(英特尔、AMD的创始人们都是从这家公司出来的)为进入欧洲市场做出了一个重要决策——在布里斯托设立一个办事处。自此,便打开了这座英国西部小城面向半导体产业的全球视野。
而6年后,诞生于布里斯托,并在80年代占据全球SRAM市场60%份额的微处理器公司Inmos,接受了卡拉汉政府与撒切尔政府高达2亿英镑的投资,才终于创造出以布里斯托核心的英国半导体基础设施与生态系统,召集了大批像XMOS 半导体创始人、英国著名计算机科学家David May这样的半导体超级精英。
“其实布里斯托一直都是英国的IT重镇。它与周围的斯温顿、格洛斯特组成一个三角地带,被称为欧洲的‘硅谷’。半导体公司如果在欧洲设立研发中心,布里斯托通常是*。譬如英伟达、惠普、博通、高通等世界级巨头都在布里斯托设有办事处。”
一位了解欧洲半导体产业的从业者告诉虎嗅,很多人因为ARM对剑桥印象深刻,但从历史来看,实际上布里斯托才是英国的芯片设计中心。
“华为也在布里斯托也有研发中心。”
就像上世纪50年代,8位天才“叛徒”离开仙童半导体创立英特尔、AMD、泰瑞达等公司,才成就了如今的硅谷一样,布里斯托才华横溢的工程师们也不甘于停留在“过去”——在摩尔定律失效争议进入高潮,人工智能、计算结构发生异变的“临界点”上,没有人不渴望能够成为那个改变时代的*。
一位名叫 Simon Knowles 的工程师从剑桥大学毕业后,在1989年*次踏上布里斯托的土地,接受了存储器企业Inmos的一份芯片设计工作。
在此后近20年里,从Inmos内部一个专用处理器团队的*,再到两家半导体企业Element 14与 Icera的创始人之一,Knowles几乎见证了摩尔定律达到*和走向衰落的全过程。而幸运的是,Knowles参与创立的这两家总估值超过10亿美元的公司,分别在2000年和2011年被博通和英伟达收购。
没有任何意外,这位天才半导体设计师与连续创业者,又继续在2016年另起炉灶,与另一位天才半导体工程师Nigel Toon创立了一家新的半导体设计公司,主动迎击人工智能市场需求触发的芯片架构创新机会。
没错,这家公司就是刚在2020年12月29日宣布完成2.22亿融资(这笔融资也让公司的资产负债表上拥有4.4亿美元现金),估值已高达27.7亿美元,被外媒称为英伟达*对手之一的人工智能加速处理器设计商Graphcore。
需要注意,它也是目前西方AI芯片领域*的独角兽。

图片为Graphcore的IPU处理器
西方私募与风投对待半导体这种项目一直非常谨慎,因为它们资金高度密集且无法预估前期投资回报。正如Knowles在一次采访时承认:“与能够小规模尝试、不成功再换一个坑的软件产业相比,如果一枚芯片设计失败,除了花光所有钱,公司几乎无路可选。”
因此,直到2018年以后,随着人工智能商业化的可能性被持续鼓吹和放大,投资者们才确定可以从“人工智能大规模运算驱动芯片结构变革”的趋势中看到回报前景。
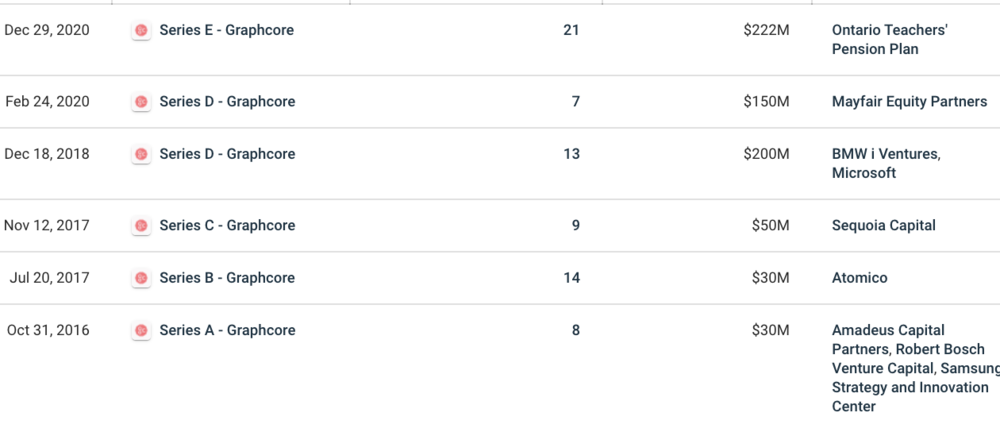
于是,在2017年获得了超过8000万美元投资后的Graphcore,又接连在2018年与2020年分别获得2亿与1.5亿美元风险投资。
需要注意的是,除了博世、三星从A轮就开始参投,红杉资本是Graphcore的C轮领投方,而微软与宝马i风投则成为其D轮融资领投方;
而E轮融资的主要参与者,则是非产业基金——加拿大安大略省教师养老金计划委员会领投,富达国际与施罗德集团也加入了这轮融资。
你可以从投资方看出,Graphcore的产业投资方基本分为三个产业方向——云计算(数据中心)、移动设备(手机)与汽车(自动驾驶)。没错,这是三个最早被人工智能技术“入侵”的产业。
 图片来自Crunchbase
图片来自Crunchbase
工业界们似乎越来越达成这样一个共识,未来需要有一家像ARM主导移动设备时代一样的底层创新企业,除了有希望卖出上亿块芯片的同时,也能推动人工智能与各个产业的深度整合,最终触达到上百亿普通消费者。
从产品的角度来看,Graphcore 在2020年拿出了相对引人注目的作品——推出第二代 IPU-M2000芯片,该芯片搭载在一个名为IPU Machine platform的计算平台上。另外,其芯片配套的软件栈工具Poplar也有同步更新。
“教计算机如何学习,与教计算机做数学题,是完全不同的两件事。提升一台机器的‘理解力’,底层驱动注重的是效率,而不是速度。” Graphcore CEO Nigel Toon 将新一代AI芯片的开发工作视为一个“千载难逢的机会”。
“任何公司能做到这一点,都能分享对未来几十年人工智能技术创新和商业化的决定权。”
切中英伟达的“软肋”
没有一家AI芯片设计公司不想干掉市值高达3394亿美元的英伟达。或者说,没有一家公司不想做出比GPU更好的人工智能加速器产品。
因此,近5年来,大大小小的芯片设计公司都倾向于在PPT上,用英伟达的T4、V100,甚至是近期发布的“最强产品”A100与自己的企业级芯片产品做比较,证明自己的处理器拥有更好的运算效率。
Graphcore也没有例外。
他们同样认为,由于上一代的微处理器——譬如中央处理器(CPU)和图形处理单元(GPU)并不是为人工智能相关工作而专门设计,工业界需要一种全新的芯片架构,来迎合全新的数据处理方式。
当然,这样的说法并不是利益相关者们的单纯臆想。
我们无法忽视来自学术界与产业界对GPU越来越多的杂音——随着人工智能算法训练与推理模型多样性的迅速增加,在诞生之初并不是为了人工智能而设计的GPU暴露出了自己“不擅长”的领域。
“如果你做的只是深度学习里的卷积神经网络(CNN),那么GPU是一个很好的解决方案,但网络已经越‘长’越复杂,GPU已经难以满足AI开发者们越来越大的胃口。”
一位算法工程师向虎嗅指出,GPU之所以快,是因为它天生就能并行处理任务(GPU的释义和特点可以看《干掉英伟达》这篇文章)。如果数据存在“顺序”,无法并行,那么还得用回CPU。
“很多时候既然硬件是固定的,我们会想办法从软件层,把存在顺序的数据,变为并行的数据。譬如语言模型中,文字是连续的,靠一种‘导师驱动’的训练模式就可以转换为并行训练。
但肯定不是所有模型都可以这么做,譬如深度学习中的‘强化学习’不太适合用GPU,而且也很难找到并行方式。”
由此来看,学术圈不少人甚至喊出“GPU阻碍了人工智能的创新”这句话,并不是耸人听闻。
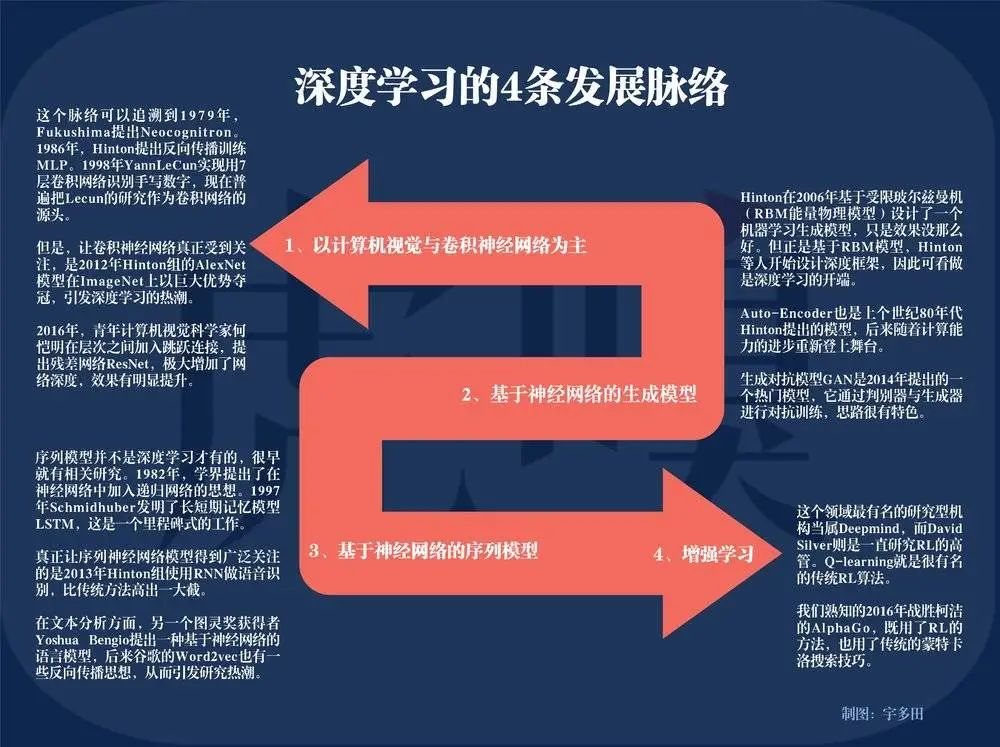
深度学习的4个发展脉络,制图:宇多田
“深度学习”,这个近10年来机器学习领域发展最快的一个分支,其神经网络模型发展之快、类型之广,只靠GPU这块硬件的“一己之力”是很难追上其复杂运算脚步的。
Graphcore 回复了虎嗅一份更为详尽的答案。他们认为,对于深度学习中除去CNNs的另外几个分支,特别是循环神经网络(RNN)与强化学习(RL),让很多开发者的研究领域受到了限制。
譬如,用强化学习做出了阿尔法狗的英国AI公司 Deepmind,很早就因为GPU的计算局限问题而关注Graphcore,其创始人Demis Hassabis最后成为了Graphcore的投资人。
“很多企业产品部门的开发者把需求(特别是延时和吞吐量的数据指标)交给算力平台部门时,他们通常会拒绝说 ‘GPU 目前不够支持这么低的延时和这么高的吞吐量’。
主要原因就在于,GPU的架构更适用于‘静态图像分类与识别’等拥有高稠密数据量的计算机视觉(CV)任务,但对数据稀疏的模型训练并不是*的选择。
而跟文字相关的“自然语言处理”(NLP)等领域的算法,一方面数据没那么多(稀疏),另一方面,这类算法在训练过程中需要多次传递数据,并迅速给出阶段性反馈,以便为下一步训练提供一个便于理解上下文的语境。”
换句话说,这是一个数据在持续流动和循环的训练过程。
就像淘宝界面的“猜你喜欢”,在*天在“学习”了你的浏览和订单数据后,把不太多的经验反馈给算法进行修正,第二天、第三天以及未来的每一天不断学习不断反馈,才会变得愈加了解你的产品喜好。
而这类任务,譬如谷歌为更好优化用户搜索在2018年提出的BERT模型,便是优秀且影响深远的RNN模型之一,也是Graphcore提到的“GPU非常不擅长的一类任务”。为了解决这类问题,仍然有很多公司在使用大量CPU进行训练。
CPU与GPU架构对比
从根本上看,这其实是由当下芯片运行系统*的瓶颈之一决定的——如何在一块处理器上,将数据尽可能快地从内存模块传送到逻辑操作单元,且不费那么多功耗。在进入数据爆炸时代后,解锁这个瓶颈便愈加迫在眉睫。
举个例子,2018年10月 BERT-Large 的模型体量还是3.3 亿个参数,到2019年,GPT2的模型体量已达到15.5亿(两个均属于自然语言处理模型)。可以说,数据量对从系统底层硬件到上层SaaS服务的影响已经不可小觑。
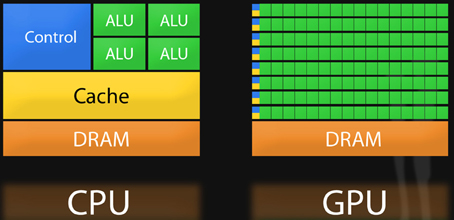
而一块传统的GPU或CPU,当然可以执行连续多个操作,但它需要“先访问寄存器或共享内存,再读取和存储中间计算结果”。这就像先去室外地窖拿储存的食材,然后再回到室内厨房进行处理,来来回回,无疑会影响系统的整体效率和功耗。
因此,很多半导体新兴企业的产品架构核心思路,便是让“内存更接近处理任务,以加快系统的速度”——近存算一体。这个概念其实并不新鲜,但能做出真东西的公司少之又少。
而Graphcore到底做到了什么?简单来说,便是“改变了内存在处理器上的部署方式”。
在一块差不多像小号苏打饼一样大的IPU处理器上,除了集成有1216块被称为IPU-Core的处理单元,其与GPU和CPU*的不同,便是大规模部署了“片上存储器”。
简言之,便是将SRAM(静态随机存储器)分散集成在运算单元旁,抛弃了外接存储,*程度减少数据的搬移量。而这种方法的目标,就是想通过减少负载和存储数量来突破内存带宽瓶颈,大大减少数据传输延迟,同时降低功耗。
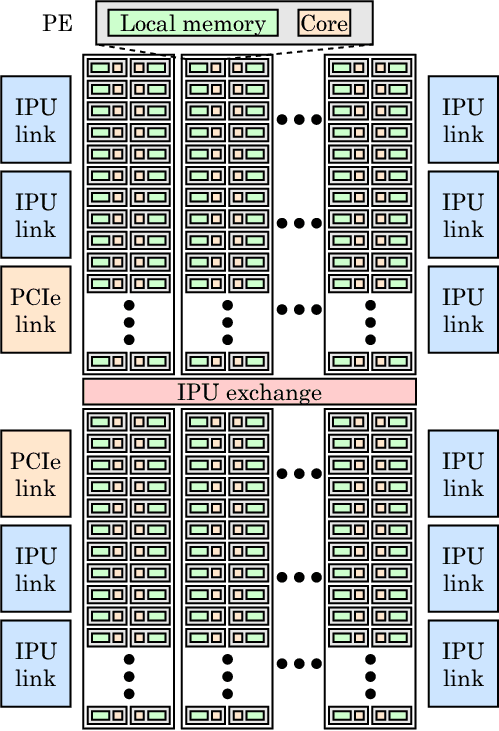
IPU架构
也正因为如此,在一些特定算法的训练任务中,由于所有模型都可以保存在处理器中,经过测试,IPU的速度的确可以达到GPU的20~30倍。
举个例子,在计算机视觉领域,除了大名鼎鼎且应用广泛的残差网络模型ResNets(与GPU很契合),基于分组卷积与深度卷积方向的图像分类模型 EfficientNet 和 ResNeXt 模型也是逐渐兴起的研究领域。
而“分组卷积”有个特点,就是数据不够稠密。
因此,微软机器学习科学家 Sujeeth 用Graphcore的IPU做了一次基于EfficientNet模型的图像分类训练。最后的结果是,IPU用30分钟的时间完成了一次新冠肺炎胸部X光样片的图像分析,而这个工作量,通常需要传统 GPU 用5个小时来完成。
重重考验
但是,就像GPU的大热与计算机视觉领域的主流算法模型ResNets的广泛应用的相辅相成,决定Graphcore成功还是失败的关键,也在于“特定”。
就像Graphcore销售副总裁兼中国区总经理在接受虎嗅采访时指出:
一方面,他们的产品的确更适用于训练市场中数据较为稀疏,精度要求较高的深度学习任务,譬如与自然语言处理相关的推荐任务,这也是阿里云与百度愿意与之达成合作的重要原因之一。
另一方面,计算机视觉领域刚流行起来的新模型,是IPU在努力“攻克”的方向,而之前很多模型,还是GPU最应手。
此外,GPU创造的强大软件生态Cuda,比硬件更不容易被破坏(关于Cuda,也在《干掉英伟达》这篇文章里有详细解释),而这层围墙恰恰是开辟产业影响力的关键。
毫无疑问,Graphocore在这方面根基尚浅,因此除了常规操作,他们选择基于编程软件Poplar,做一些相对大胆的尝试。
譬如,他们在自己的开发者社区开放计算图库PopLibs的源代码,让开发者去尝试描述一种新的卷积网络层。这一层对标的是GPU的cnDNN和cuBLAS,而英伟达并没有开放它们。
为了向开源社区致敬,Poplar v1.4增加了对 PyTorch 的全面支持。这一聪明的举动将有助于简化人们的接受程度,有助于吸引更广泛的社区参与。
此外,为了能够尽快打开市场,Graphcore并没有走“打比赛来提升产业知名度”的实验室销售路线,而是将IPU直接推入了产业界,去逐个敲开服务器集成商、云厂商等客户的大门。
“AI这个行业本身,不管是算法的迭代还是模型的变化,其实都是非常快的。有云厂商曾抱怨,说某家处理器跑某一种模型性能非常好,但模型稍微改一改,跑出来的性能就大跌眼镜。”
Graphcore中国区技术应用总负责人罗旭认为,尽管市场在大量鼓吹ASIC(专用芯片)和FPGA(可编程芯片),但通用性,仍然是产业界考虑芯片的首要条件,尤其是互联网厂商。
“互联网厂商应用非常多,每个应用都会有不同的适用模型。如果一个处理器只能适配一个模型,那客户是无法引入这个处理器做大量推广的。”
而“编程环境是否友好”,也就是英伟达Cuda贡献的那种力量,是第二个关键的采购指标。
“现在客户一般都是用AI框架来设计模型,比如谷歌的TensorFlow、Facebook的PyTorch等等。他们会考虑这枚处理器的上层SDK是否能够轻松接入到框架里,以及编程模型是否好用。
客户可能会有一些算子级别的优化,需要做一些自定义算子。自定义算子开发起来是否方便其实也是取决于编程友好性如何。”
如果说客户还在乎什么,当然是产品性能。
无论是云厂商、服务器厂商还是通过云服务购买算力的开发者,都会测试多种模型跑在芯片上的性能表现。
“如果他们主要看重NLP(自然语言处理)模型,那在性能测试时就可能重点测一下BERT。如果他们看重计算机视觉,那在性能测试时就可能重点测试一些计算机视觉的经典模型。
总的来说,客户需要从以上几个维度综合评估下来,才能决定到底要不要使用这个处理器,或者说,必须确定这个处理器能给他们带来多大的收益。”
而在这个方面,无论是英伟达,还是Graphcore的IPU或其他厂商的专用芯片,都是有自己最擅长的模型,只能说是“各有千秋”,*不能以偏概全。
赢家通吃,将不复存在
从Graphcore给出的产品基准测试指标与宣传重点来看,这家公司正在拿着锤子找钉子,努力扩展IPU擅长的应用场景,以便让IPU架构能够发挥*效率。
换句话说,Graphcore或许会分英伟达的一杯羹,但永远不可能取代它们。
正如“特定”这个词的含义所限,人工智能训练与推理芯片市场,因模型的多样性与复杂性,一定能够容纳包括英伟达、Graphcore在内更多的芯片企业。
Nigel Toon也承认,人工智能计算将孕育出三个芯片垂直市场:
相对简单的小型专用加速器市场,譬如手机、摄像头以及其他智能设备里的某个IP核;
再譬如适用于数据中心某几个功能的ASIC芯片,具体问题具体解决,超大规模数据中心运营商(云厂商)将在这个市场中有大量机会;
最后一个是可编程的AI处理器,也就是GPU所在的市场。这个市场一定会有更多企业,同时未来更多的创新也一定会产生更大的份额。
CPU会持续存在,GPU也会持续创新,他们在某些AI计算任务上都是不可或缺的,或者说是*的选择。但是摩尔定律失效、AI计算和数据爆炸等趋势催生出的新市场,一定是巨大且多样性的。正是因为多样性,所以才给了更多专用芯片公司新的机会。
因此,像Cerebras、Groq、 SambaNova Systems 、Mythic AI 这样的芯片创业公司才得以筹集到数亿美元资金,英特尔也在今年投资了革新AI芯片架构的Untether AI。已经有不少人给出这样的预测——新一代的‘苹果’与‘英特尔’可能会在人工智能计算市场中诞生。
在软件还没有跟上硬件步伐的当下,这意味着激烈的竞争才刚刚开始。
【本文由投资界合作伙伴虎嗅网授权发布,本平台仅提供信息存储服务。】如有任何疑问,请联系(editor@zero2ipo.com.cn)投资界处理。



