
自然语言处理( Natural Language Processing, NLP)是计算机科学领域与人工智能领域中的一个重要方向,广泛应用于机器翻译、舆情监测、观点提取、语音识别等场景。自然语言处理技术在发展过程当中长期面临着包含内容的有效界定、不规范输入等在内的技术难点。这些都导致了较高的人工参与程度及尚有极大提升空间的机器学习效率。
特斯联所打造的科创中心致力于通过弱监督大模型训练体系及联邦学习安全训练体系,向不具备AI能力或弱AI能力的用户提供AI算法孵化服务能力。目前针对计算机视觉、自然语言处理、推荐预测、知识图谱四个方向共十三个细分项,特斯联与学术生态及产业合作伙伴已展开深入合作。在自然语言处理方向,特斯联打造了基于对比学习与自监督的NLP自训练学习算法,通过自监督的预训练算法、特征表示学习算法,及自训练系统,解决前述挑战。
NLP自训练学习算法:已知反哺未知,提升学习效率
特斯联核心算法团队基于数千项目的业务数据,提出了基于自监督的预训练算法、特征表示学习算法,及自训练系统,*限度从领域数据、大量无标签数据、已有无标签样本、已知标签样本特征中,挖掘潜在内嵌信息,反哺到未知标签数据上,减少人工干预,提升学习效率。
- 基于自监督的预训练算法
特斯联通过对自有数千项目生产的数据进行提取,获得大量无标签数据,并基于bert模型实行自监督无人工干预的预训练,让bert模型深入地学习到领域内知识,从而保证模型得到领域内数据更精确的特征表示。该方法通过三个步骤实现:
1)步骤1,采用[MASK]。采用基于分词的n-gram masking技术,1-gram~4gram Masking的概率分别为40%、30%、20%、10%。Mask使用whole word masking方式对分词后的结果进行。
2)步骤2,取消[MASK]。通过word2vec计算相似度,召回最相似的词替代MASK,缓解预训练任务与下游fine-tune任务的不一致性。基于分词后的结果随机挑选15%的词进行MASK。其中80%同义词替换,10%随机词替换,10%保持不变。
3)步骤3,添加sentence-order prediction任务。Sentence-order prediction任务预测自监督的两个句子为正序或逆序,使预训练模型学习到sentence pair的内在知识。
上述三个步骤之后,算法将所有训练集和测试集的数据去掉标签,并结合所有未标注的数据,进入预训练模型实行自监督预训练,让预训练模型更充分学习到任务数据的内在语义特征,更精准地预测无标签数据。
- 特征表示学习算法
特斯联提出通过一个改进的全局特征相似度,充分挖掘样本特征内在的联系和表示,从而构建捕捉样本间细粒度特征的学习模块。

如上图,输入分别通过4个大模型,每个大模型分别在一块GPU中,通过master节点分发输入,最终master节点将4块GPU中大模型的输出进行concat,并通过线性层得到最终输出特征表示学习算法模型主要采用bert、roberta、macbert,其base和large模型级联分别对应如图GPU1、GPU2、GPU3,得到输出的embedding特征表示为E1、E2、E3。GPU0部分为bert、roberta、macbert模型级联,使用fgm对抗性训练技术,最终得到输出embedding特征表示为E0。这里使用stacking的集成学习思想,结合四种特征表示concat (E0,E1,E2,E3),再进入分类器得到模型输出,让特征的表示更加丰富,融合各模型知识,以不同的视角去获得特征表示,以此为后续的任务提供更有效的支持。
- 自训练系统
自训练系统为一个自监督训练系统,其流程分为两个阶段:*阶段,采用自监督对比学习技术,充分利用无标签数据进行自监督训练,让模型清晰地表达现有数据;第二阶段,使用少量带标签数据对模型微调,让模型在任务数据上达到较好效果。其中,*阶段分为自监督与半监督两个步骤:
*步,自监督/对比学习。首先假设样本集合为![]() ,其中
,其中![]() 和
和![]() 为语义相关的,
为语义相关的,![]() 为样本集合中的原始数据,
为样本集合中的原始数据,![]() 为生产的与
为生产的与![]() 相似的数据。评价
相似的数据。评价![]() 和
和![]() 的语义空间表示是否相关,须衡量alignment和uniformity两个指标。其中alignment计算
的语义空间表示是否相关,须衡量alignment和uniformity两个指标。其中alignment计算![]() 和
和![]() 的平均距离为:
的平均距离为:![]()
,uniformity计算向量整体分布的均匀程度为:![]()
以上述两个指标作为指导,设计随机采样dropout mask的方式生成![]() 。设
。设![]() ,其中z是随机生成的dropout mask。训练阶段将同一个样本分两次输入到上述的特征表示学习模型中,会在分类器前得到两个不同的特征表示向量
,其中z是随机生成的dropout mask。训练阶段将同一个样本分两次输入到上述的特征表示学习模型中,会在分类器前得到两个不同的特征表示向量![]() ,
,![]() 。将
。将![]() 作为正样本,模型训练目标为:
作为正样本,模型训练目标为: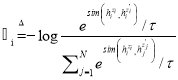
第二步,半监督/对比学习。从训练集中取出部分的标注数据,微调经过自监督训练的模型。过程中,也采用对比学习训练。我们记数据集中原始样本,正样本、负样本为![]() ,其中正负样本均取自原始带标注数据集,损失函数改进为
,其中正负样本均取自原始带标注数据集,损失函数改进为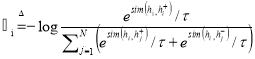 。使用带标注的数据按上述损失函数进行监督训练后,模型即可达到一种良好的性能。
。使用带标注的数据按上述损失函数进行监督训练后,模型即可达到一种良好的性能。
为进一步提升模型的性能,对于已收集到的大量无标签数据,也可使用微调后的模型对无标签数据生成标签。这里可通过设定阈值限制选择高置信度的标签,将这些标签混合原始的标注数据继续微调模型,进一步提升模型性能。
自监督训练系统解决了标注数据不足,少标签数据的问题,可在极少人工干预的情况下,让不懂AI算法的人员训练出属于自己的AI模型。
提升意图识别效率,特斯联NLP自训练学习算法助力AI产业落地
在人机对话系统的实践中,大量算法需要首先进行用户的意图识别,但用户的许多意图数据量很少,难以对用户各个意图进行大量的数据标注。这在实际的工业落地中是一个极大的挑战,也是NLP自训练学习算法可以发挥作用的场景。
特斯联NLP自训练学习算法可帮助厂家将此产业难题分解为几个pipeline式的子问题,逐一解决。厂家可先从对话系统中搜集大量未标注的用户对话语料,然后根据特斯联九章算法赋能平台提供的指标选择训练模型和训练目标,直接使用无标注的语料开启预训练。在开启预训练流程后,NLP自训练学习算法会自动挖掘用户各个意图之间的语义相关联系和区别,学习界定各个不同意图的边界方法,充分捕捉用户输入的潜在语义表达。完成预训练流程后,NLP自训练学习算法会自动使用未标注语料,进行自监督的对比学习训练,进一步学习区分不同用户输入和意图。随后的下游任务训练流程,仅需要对用户对话语料数据进行少量的标注,配合半监督技术进行下游的微调训练。待训练完成后,即可获得最终的意图识别模型,帮助满足诸如人机对话、机器人文本客服、机器人语音客服等实际工业场景中的需求。
随着技术的不断迭代,自然语言识别的能力也已从“让机器听得到”发展到了“让机器听得懂”的阶段,未来突破的方向则是让机器不仅能够“听得懂”还能“做得到”,这离不开整个产业的共同努力。借由科创中心,特斯联希望打造流程化、低门槛的AI基础设施,使各细分领域的玩家可以共同站在当前AI发展的成果的基础之上,探索更前沿的创新,使人工智能技术真正高效地参与到产业实践当中。





