
Intel下一代旗舰级CPU Sapphire Rapids将会是Intel在CPU领域的一次重要新产品。该CPU将会使用Intel 7工艺,并且大规模使用了chiplet(芯片粒)技术,从而让单个CPU中可以包含高达60个核心,从而让Intel不至于在高级封装驱动的下一代CPU竞争中落后AMD。
Sapphire Rapids早在几年前就已经宣布要开发,而其正式出货在多次推迟后,终于在最近几个月有了更确定的消息。根据最近Intel发布的消息,Sapphire Rapids将在2023年正式出货。而在9月底,Intel也在自家举办的活动Innovation Event上发布了基于Sapphire Rapids样片的demo,这也让Sapphire Rapids的一些重要特性让外界有了更加详细的认知。
在Sapphire Rapids的这些新特性中,除了chiplet这一个广为人知的技术之外,最值得关注的就是使用了异构计算的架构,集成了许多为专门计算领域优化的加速器(domain specific accelerator,DSA)。在过去的几十年中,由于CPU性能借着摩尔定律的高速发展而飞速提升,大多数时候用户会考虑只使用CPU来处理所有的算法,即使用一个通用架构来解决所有问题。然而,随着摩尔定律的发展接近瓶颈,使用一个通用架构解决所有问题已经不再现实,因为CPU性能的发展速度已经跟不上应用的需求,因此异构计算的思路得到了越来越多的重视,即为了重要的应用专门设计相关的计算加速模块,从而加速计算性能,同时也改善效率。
我们认为Intel在下一代CPU Sapphire Rapids中引入大量异构计算是一个里程碑式的事件,这是因为传统上来说通用型CPU和异构计算是两个芯片设计阵营,通用CPU设计的时候会尝试改善性能从而说服用户无需使用异构计算;而Intel这次在Sapphire Rapids中主动引入大量异构计算加速器,这也说明了异构计算确实已经成为极其重要的主流设计方案,与其单独设计CPU然后让其他公司去设计相关的异构计算芯片抢走市场,还不如在自己的CPU中主动拥抱异构计算,集成相关的加速器,来确保满足用户的需求。
具体来看,这次Intel在Sapphire Rapids中集成的独立加速器主要包括动态负载平衡模块(DLB),数据流加速器(DSA),内存内分析加速器(IAA),以及快速协助模块(QAT)。这些独立的加速器是作为一个单独模块集成在CPU之外的。除了这些单独加速模块之外,Intel还在每个CPU核心中集成了用于矩阵计算加速的AMX模块(Advanced Matrix Extensions)。
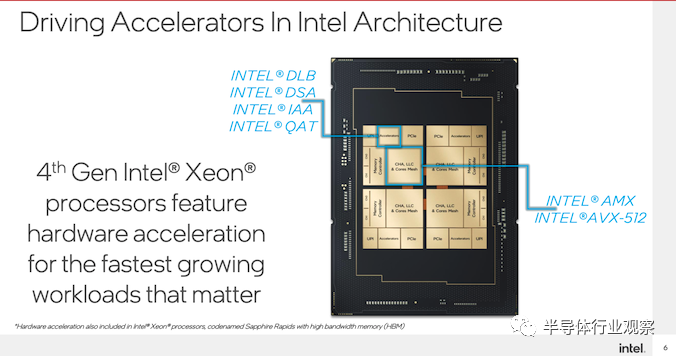
我们不妨来看一下这些加速模块的具体功能。DLB的主要功能是加速不同服务器之间的负载均衡,从而保证服务器的大规模部署分布式计算。DSA主要用于加速CPU和存储(NVMe以及TCP)之间的数据交换和数据转换。IAA主要用于数据库应用,可以加速数据库相关应用中的数据压缩和解压。QAT主要用于网络相关应用中的数据压缩和加密运算。最后,AMX主要是用于人工智能相关的矩阵运算。
我们可以看到,这些加速器几乎都是针对目前最火热的大数据应用,主要目的都是改善这些大数据应用中的痛点。DSA,IAA和QAT针对的应用目前基本都是CPU是主要计算单元,但是由于在数据传输等领域传统CPU的效率不高,目前有不少公司试着在用专门的ASIC来取代CPU,因此Intel这次在Sapphire Rapids中引入这些加速器正是一个希望能保住这些市场中公司份额的举动。AMX主要针对矩阵运算,目前虽然GPU是人工智能相关计算的主流计算单元,但是也有一些模型因为需要使用的一些算子GPU支持不够好,仍然是在CPU上计算,而Intel的AMX正是针对这些模型的部署做加速。
异构计算为软件定义芯片铺平道路
如前所述,Intel在Sapphire Rapids中加入了大量异构计算特性,其主要目的是为了提升性能,确保市场竞争力。而除了这之外,异构计算其实还有另外一个优势,就是可以实现软件定义芯片。这是因为异构计算中,不同的加速器模块相对独立,因此可以通过软件的方式来实现控制这些加速器的开关。这也事实上让付费订阅芯片功能这样的商业模型成为了可行:使用同一款芯片,用户可以在不同的时间点根据需求灵活订阅相关的芯片功能并支付相关的费用,从而让整个芯片的购买和使用过程更加灵活。
对这样新商业模式的尝试也正是Intel在Sapphire Rapids里计划要做的。Intel之前把这样的模式称为Software Defined Silicon(SDSi),而在上周Intel刚刚发布的针对该功能的正式Linux代码中,该模式被改名成了Intel On-Demand(IOD)。根据Intel公布的代码,IOD将会首先检测相关的加速器IP是否存在于对应的物理芯片中,而在检测到相关的加速器IP之后,管理员可以通过IOD来激活这些加速器IP。同时,IOD还可以统计这些相关加速器IP的使用频率,从而帮助系统管理员来决定要购买哪种对应的付费订阅方案。
随着先进半导体工艺的成本越来越高,事实上使用软件定义芯片正在成为越来越合理。使用软件定义芯片,芯片设计公司只需要设计一款芯片,然后可以通过软件的形式来针对不同的用户群体。这样一来,芯片公司就无需为了不同的受众群体而设计多款不同的芯片,因为在先进半导体工艺中,每一款芯片的NRE成本都是非常高的。当然,软件定义芯片造成了芯片面积的一些浪费(例如入门级用户可能不会付费激活大多数加速器IP),但是在NRE成本越来越高的今天,通过一些芯片面积来交换较低的总NRE成本正在成为越来越合理的选择。
软件和异构计算引领行业变革
随着摩尔定律逐渐走向饱和,软件(包括狭义的软件定义芯片和广义的软件-芯片协同优化)和异构计算将会引领高性能计算芯片继续演进。从行业上来看,除了上文讨论的Intel之外,AMD和Nvidia在相关方向上都有重要的布局。
AMD在异构计算和软件方面的布局主要包括对于Xilinx的收购和在高性能计算GPU(CDNA系列)领域的软件生态投资。收购FPGA领域的*Xilinx确保了AMD有机会能把FPGA技术和处理器业务整合在一起,而FPGA正是异构计算的一个重要范式之一。在软件方面,AMD继续大力投资CDNA系列GPU和相关软件生态(包括与CUDA竞争的ROCM生态),预计在未来5-10年内会把CDNA系列GPU生态打造成和Nvidia生态有一较高下的实力。
Nvidia在软件生态方面拥有护城河极高的CUDA,我们认为在可预计的将来该软件生态将会成为Nvidia继续大力布局的领域同时也将是Nvidia*的竞争力来源之一。随着AMD和Intel进一步在GPU和AI加速卡领域的投资,该领域的竞争会变得愈加激烈,软件生态也将会成为决定市场竞争力最关键的核心之一。在异构计算领域,我们也看到了Nvidia在GPU设计中越来越针对相关算法做专用加速器,例如针对整数计算的Tensor Core,以及在最新Hopper系列GPU中加入的Transformer Engine IP。另外一个不容小觑的方向是Nvidia自动驾驶芯片,在Nvidia公布的Orin等自动驾驶芯片中,我们可以看到它集成了多种针对专门应用的加速器,可谓是异构计算的典范。
我们预计,整个高性能计算芯片行业都会继续大力布局软件和异构计算,而在某一个时间点,软件和异构计算将会慢慢融合,例如针对特定算法应用优化的异构计算IP(软件芯片协同优化),同时通过软件定义芯片的方式来实现潜在的新商业模式。整个行业将会看到越来越多在软件方面的投资和收购(例如Intel不久之前对于codeplay的收购),同时整个芯片设计范式将会看到越来越多软件和芯片设计的协同优化。
【本文由投资界合作伙伴微信公众号:半导体行业观察授权发布,本平台仅提供信息存储服务。】如有任何疑问,请联系(editor@zero2ipo.com.cn)投资界处理。





