
在最近风起云涌的AI圈里,每一片英伟达H100 GPU的走向都被大家紧盯着。原因无它,就因为H100是当前进行人工智能训练的最强引擎。
如今,全球约90%以上的大模型都在使用英伟达的GPU芯片,作为生成式AI时代下最为关键的基础硬件,几乎所有人工智能企业都在四处搜寻H100的踪影。一定程度上来说,谁拥有了更多的H100,谁就在当前AI竞赛中占据着上风。
而今天,在洛杉矶的SIGGRAPH大会上,英伟达宣布了新一代GH200 Grace Hopper超级芯片平台的到来。GH200专门为加速计算和生成人工智能时代而打造,旨在处理世界上最复杂的生成式人工智能工作负载,涵盖大型语言模型、推荐系统和矢量数据库,并将提供多种配置。
不仅仅只是超级芯片,围绕着生成式AI的方方面面,英伟达今天还发布了一系列更新,包括全新AI服务平台、推出了4款新显卡、服务器等等,试图全方位加速和简化生成式AI项目的开发、训练、部署和应用。
为生成式AI时代打造最强超级芯片平台
此次,全新的Grace Hopper 超级芯片该平台配备了全球* HBM3e 处理器,通过大幅增加带宽和内存,将为更大的 AI 模型提供训练和计算能力。该配置经过优化,GH200还可以执行 AI 推理功能,从而有效地为 ChatGPT 等生成式 AI 应用程序提供支持。
英伟达之所以称GH200为“超级芯片”,因为它将基于 Arm 的 Nvidia Grace CPU 与 Hopper GPU 架构结合在了一起。GH200 与目前*的 AI 芯片 H100 具有相同的 GPU,H100 拥有 80GB 内存,而新款 GH200 的内存高达141GB同时与 72 核 ARM 中央处理器进行了配对。
新版本的GH200采用了全球最快的内存技术HBM3e。英伟达表示,HBM3e内存技术带来了50%的速度提升,总共提供了10TB/秒的组合带宽。因此,新平台能够运行比先前版本大3.5倍的模型,并以3倍的内存带宽提高性能。
拥有更大的内存也意味着未来可以让模型驻留在单个 GPU 上,而不必需要多个系统或多个 GPU 才能运行。

不仅能力得到了大幅提升,英伟达还Nvidia 还发布了NVIDIA NVLink™服务器设计对GH200进行了扩展。NVIDIA NVLink™将允许Grace Hopper超级芯片可以与其他超级芯片连接组合,这一技术方案为GPU提供了完全访问CPU内存的途径。
英伟达表示,目前正在开发一款新的双GH200基础NVIDIA MGX服务器系统,将集成两个下一代Grace Hopper超级芯片。在新的双GH200服务器中,系统内的CPU和GPU将通过完全一致的内存互连进行连接,这个超级GPU可以作为一个整体运行,提供144个Grace CPU核心、8千万亿次的计算性能以及282GB的HBM3e内存,从而能够适用于生成式AI的巨型模型。
GH200还能够兼容今年早些时候在COMPUTEX上公布的NVIDIA MGX™服务器规格。有了MGX,制造商可以迅速且经济高效地将Grace Hopper技术整合到100多种服务器变体中。
NVIDIA首席执行官黄仁勋强调,数据中心需要应对生成型AI的激增需求,因此也需要有更具针对性的加速计算平台,GH200平台正是为满足这一需求而生。
“你几乎可以将任何你想要的大型语言模型放入其中,它会疯狂地进行推理。大型语言模型的推理成本将大幅下降,同时将大幅提高数据中心的运作效率和性能。”
目前,英伟达计划销售GH200的两种版本:一种是包含两个可供客户集成到系统中的芯片,另一种则是结合了两种 Grace Hopper 设计的完整服务器系统。

英伟达表示,全新的GH200将大大降低训练成本和提升训练速度,预计将于明年第二季度上市。
|推出AI Workbench服务,企业级AI项目本地也能开发部署
除了全新的超级芯片平台,英伟达今天还宣布了推出了一个新的AI服务——AI Workbench,这是一个易于使用的统一工具包,让开发人员能够在 PC 或工作站上快速创建、测试和自定义预训练的生成式 AI 模型,然后将其扩展到几乎任何数据中心、公共云或NVIDIA DGX™ 云。
英伟达认为,当前企业级AI的开发过程太过繁琐和复杂,不仅需要在多个库中寻找合适的框架和工具,当项目需要从一个基础设施迁移到另一个基础设施时,过程可能会变得更加具有挑战性。
研究机构KDnuggets曾进行过一个调查,80%或更多的项目在部署机器学习模型之前停滞不前。Gartner的另一项研究也显示,由于基础设施的障碍,有接近85%的大数据项目失败。
总体来看,企业模型投入生产的成功率总体较低,世界各地的企业都在寻找合适的基础设施来构建生成AI模型和应用。而此次,AI Workbench则为这个过程提供了简化的路径。
黄仁勋在会议上表示,为了推动AI技术普惠,必须让其有可能在几乎任何地方运行。因此,AI Workbench将支持在本地机器上进行模型的开发和部署,而不是云服务上。
AI Workbench提供了一个简单的用户界面,开发人员能够将模型、框架、SDK 和库从开源资源整合到统一的工作区中,可以在本地计算机上运行并连接到 HuggingFace、Github以及其他流行的开源或商用 AI 代码存储库。也就是说,开发人员可以在一个界面上轻松访问大部分AI开发所需资源,不用打开不同的浏览器窗口。
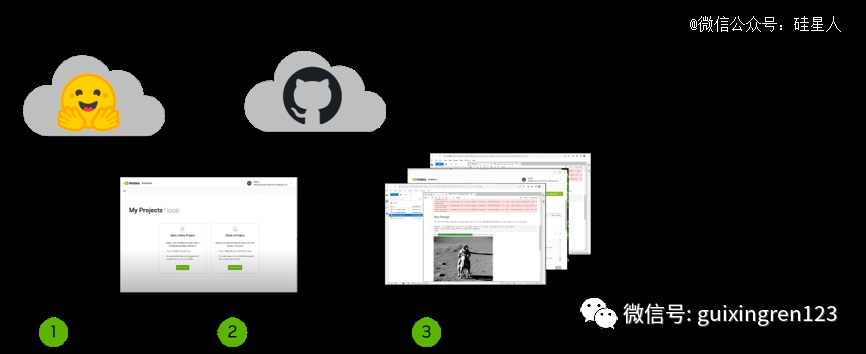
英伟达表示,使用 AI Workbench 的一些主要优势包括:
易于使用的开发平台。AI Workbench 通过提供单一平台来管理数据、模型和计算资源,支持跨机器和环境的协作,从而简化了开发流程。
与 AI 开发工具和存储库集成。AI Workbench 与 GitHub、NVIDIA NGC 和 Hugging Face 等服务和 Git 服务器集成,用户可以使用 JupyterLab 和 VS Code 等工具跨平台和基础设施进行开发,具有高度的可重复性和透明度。
增强协作。该项目结构有助于自动化围绕版本控制、容器管理和处理机密信息的复杂任务,同时还支持跨团队协作。
访问加速计算资源:AI Workbench 部署是客户端-服务器模型,用户能够开始在其工作站中的本地计算资源上进行开发,并随着训练作业的规模扩大而转向数据中心或云资源。
英伟达表示,目前戴尔、惠普、Lambda、联想等人工智能基础设施提供商已经采用了 AI Workbench服务,并看到了其提升最新一代多 GPU 能力的潜力。在实际用例中,Workbench 可以帮助用户从单台 PC 上的开发转向更大规模的环境,在所有软件都保持不变的情况下帮助项目投入生产。
|万亿芯片老大,要用AI守擂
此次,围绕着生成式 AI 和数字化时代的开发和内容创作,英伟达还一口气推出了多项的新产品和服务,可以说是涵盖了生成式AI开发的方方面面。
在桌面AI工作站方面,推出了RTX 6000、RTX 5000、RTX 4500和RTX 4000四款新显卡,旨在为全球专业人士提供最新的 AI图形和实时渲染技术。并基于新GPU推出了一套一站式解决方案 RTX Workstation。
针对 AI 训练和推理、3D 设计和可视化、视频处理和工业数字化等计算密集型应用的需求,推出了配备 Nvidia L40S GPU 的 Nvidia OVX 服务器,旨在加速多个行业的工作流程和服务。

Nvidia 推出了新的RTX 工作站GPU
发布最新版本的企业软件平台 Nvidia AI Enterprise 4.0,同时引入用于构建和定制生成式 AI 基础模型的端到端框架 Nvidia NeMo,旨在为企业提供在其运营中集成和部署生成式 AI 模型的工具,但以安全的方式和稳定的 API 连接。
推出了GPU 加速的软件开发套件和云原生微服务 Maxine,让专业人士、团队和创作者能够利用人工智能的力量并创造高质量的音频和视频效果,从而改进实时通信服务。此外Nvidia Research 还宣布推出人工智能驱动的 3D 视频技术,在沉浸式通信领域取得进展。
随着英伟达一个接一个新产品和新服务的揭晓,我们似乎也看到生成式AI的生产力爆炸时代正在加速到来。
在人工智能的驱动下,英伟达今年的来收益和股价节节攀升,公司市值一度突破万亿美元。但越是风光,竞争对手就越是虎视眈眈。随着人工智能芯片荒的加剧,巨头们都开始加大投资、奋起直追。
比如,就在今天的大会不久前,AMD刚刚发布了自己“大模型专用”的AI芯片MI300X,直接对标H100。此外,谷歌、亚马逊、特斯拉等也都在设计自己的定制人工智能推理芯片。但目前来看,在越来越激烈的赛道上,跑在最前边的英伟达丝毫没有松懈。
靠AI“翻身”的英伟达,显然还想要乘着AI的风跑得更快、更远。
*参考资料:
Nivida Technical Blog
注:封面图和插图均来自于英伟达官方。
【本文由投资界合作伙伴微信公众号:硅星人授权发布,本平台仅提供信息存储服务。】如有任何疑问,请联系(editor@zero2ipo.com.cn)投资界处理。




