
当前,越来越多的人工智能模型有望被用于临床,包括预测白血病、中风的危险性。
药物临床开发阶段,AI模型也开始试点对临床试验结果的预测以及分析。
很多模型声称能够对临床结果做出预测及警示,助力临床研究和护理,但是在实际部署过程中,医生与模型的互动反而可能会造成AI性能的改变。
一项新的研究表明,随着时间的推移,这些预测模型可能“会好心办坏事”——导致呈现的数据结果出现误差,效果急剧下降。
明明应该是向善的技术,最终反而害了人?
01 AI临床,模型吃模型
临床中,疾病的发展和死亡息息相关。
例如在ICU病房,急性肾损伤(Acute kidney injury,AKI)是常见的并发症,高达20%-70%患者将会进展到AKI的某个阶段。
另外,急性肾损伤又跟死亡率高度相关,那么预测急性肾损伤概率和预测死亡率就成为了两个模型,针对其中一个结果的处理会影响另一个结果。
近日的论文中,研究人员以美国两大*医院——西奈山医疗系统和贝斯以色列女执事医疗中心重症监护病房(ICU)的入院情况作为研究对象,共计收治了13万名病人。
而为了评估模型的结果,团队又引入了几个数据,一个是依从率,指医生得知模型预警后的遵守程度(毕竟医生不会完全听信模型);
第二个则是有效率,也叫敏感度,指导致管理变化并防止不利结果的真阳性模型预测的比例。
还有一个是特异性,也称作真阴性率,医学中如果特异性较低,则会出现很多假阳性的误诊患者。
研究人员设立了3个场景。
场景1:初次使用后重新训练模型
在*个场景中,研究团队训练一个预测ICU入院后5天死亡率的模型,并根据新的患者数据对其进行了重新训练,模拟了如果预测工具在部署后反馈会发生什么。
他们发现,虽然该方法最初提高了性能,但结果却导致性能进一步下降。表现为死亡率预测模型在重新训练一次后失去了 9%到39% 的特异性。
发生这种情况是因为模型首先适应不断变化的条件,随着患者特征和模型“学习”的结果之间的关系因再训练而发生变化,导致其性能下降。
场景2:按顺序部署模型
第二种情况涉及在已经部署了另一个模型之后开发一个新模型。在部署急性肾损伤的模型后,训练了与预测死亡率的模型。
这一情境下,实施急性肾损伤 (AKI) 后创建的死亡率预测模型失去了 8% 到 15% 的特异性。
当肾脏模型的预测帮助患者避免急性肾损伤时,它也降低了死亡率。因此当后来再使用这些数据创建死亡率预测因子时,其特异性就受到了影响。两个工具都将受到数据漂移的影响。
专家称可能无法定义结果之间的确切关系,这意味着之前接受机器学习引导护理的患者的结果有所改善,但他们的数据不再适合在模型训练中使用。
场景3:同时使用两个预测模型
在这个场景中,将ICU入院后5天内预测死亡率和AKI的模型同时实施。最终发现使用一组预测会使另一组预测变得过时,不再适用了。
因此,预测应该基于新收集的数据,这可能成本高昂或不切实际。
在23053项预测中,118项AKI预测和141项死亡率预测被认为过时,依从率为0.1。当依从率为0.75时,这些值分别增加到5841和6962。
两个模型同时部署时,每个模型各自所驱动的医疗保健变化都会使其他模型的预测失效,每个模型都会导致另一个模型的有效准确度降低 1% 到 28%。
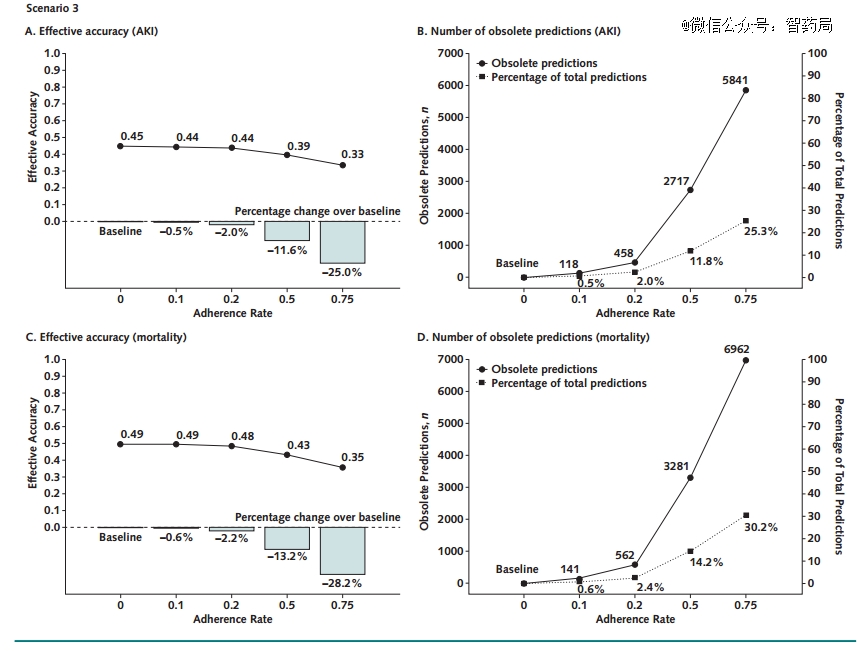
图A和C分别显示了随着依从率的增加,急性肾损伤和死亡率预测模型的有效准确性的变化。A和C中的条形图显示了在基线实验室条件下开发的模型(依从率为0)和临床医生对模型预测的依从率增加之间的性能百分比变化。图B和D显示了对AKI和死亡率结果的预测的数量和百分比,这些预测由于来自另一个模型的预测而因管理变化而过时。对于任何一个模型,有效的准确性降低,而过时的预测数量随着医生对模型预测的坚持而增加。
这也反应了:使用预测模型的时间越长,而不考虑反馈循环后性能下降,它们的可靠性就越低,就像一颗定时炸弹。
02 呼吁更多监管
当然这次研究仍然有局限性,导致结论不一定准确,例如数据上因为伦理和审查问题,导致它是一次回顾性模拟研究,而并非真实临床上的部署。
也就是说,这项研究无法得知真实临床上的依从性,以及临床干预措施在减少肾脏损伤和死亡方面的效果如何。
但它也揭开了一个被忽视的问题,人们总是宣称AI模型的准确度有多么高,进入医院试点部署了,但后续对却缺乏对模型性能的监测。
这些模型在实际部署中会产生复杂的相互作用,例如按顺序部署或者同时部署后,一旦重新训练模型或者数据反馈机制,那么这个模型就没用了。
并且随着临床模型的越来越多,它可能会更加难办。例如此前智药局曾经报道过,当前国内外医疗大模型数量暴增,未来的迭代将接受这些数据的训练,而且可能会产生意想不到的后果。
由此我们陷入了一个“模型吃模型”的世界。(model-eat-model world)
专家警示,如果不加以重视,一个AI模型除了最终使自己无法使用外,还会混淆其他模型的部署和未来开发。
此前FDA出台过关于AI模型的指南草案,并提出了一种全生命周期方法来监管人工智能或机器学习模型,用于监控和更新模型的过程。建议的组件包括数据管理、模型再训练、性能评估和更新程序。
我们早就该意识到,影响患者预后和 EHR 数据下游反馈的成功实施,需要新的方法来更新模型。
【本文由投资界合作伙伴微信公众号:智药局授权发布,本平台仅提供信息存储服务。】如有任何疑问,请联系(editor@zero2ipo.com.cn)投资界处理。





