
2022年11月,OpenAI发布的GPT-3.0震惊全球,2023年3月更新到GPT-3.5后,更是直接在中国引发了一场“百模大战”——紧随其后,2023年3月,百度*发布文心一言,随后很短的时间360、阿里、华为、商汤等一大批企业发布了自己的大模型。
而OpenAI最新推出的文生视频大模型Sora,已经火了一个月。问题来了——2023年上半年的百模大战跟进非常及时,Sora都一个多月了为啥没看到百“兽(Sora)”大战?国内的厂商放弃跟进了吗?
1、Sora火的这一个月,我们怎么不跟了
苹果头显火了一个多月,哑火了。元宇宙火了一年多,哑火了。
ChatGPT火了一年多,不仅没有哑火,反而越烧越旺,持续释放着想象力。Sora,就是那朵位于最上层、跳动最明亮的火苗。
2023年头几个月ChatGPT爆火,除了欧洲有法国初创企业Mistral AI等零星企业跟进之外,很少听说世界其他国家还发布了有较大影响力的大模型;人工智能,就只能看美国和中国了。当然,拆解来看,还是美国跑在最前做原创,我们紧盯着美国科技巨头与AI企业做应用。
但我们毕竟已经是全球*能跟进美国科技企业并快速基于开源研发或自研各类大模型的国家了——2023年的大模型发布会一个接着一个,众多企业一个个宣称水平赶超GPT-4、GPT-3.5。或许这里面有泡沫,但哪一场繁荣不是伴随着泡沫呢?
真正有技术、有商业化能力的企业,自然会从泡沫中走出来,吸收掉泡沫的水分,转化为成长的动力。
最可怕的,是连泡沫都没有。
当然,文本生成可以用llama开源,图片生成可以用Stable DIffusion,但视频生成的门槛一下子高了起来——闭源了,找不到开源参考了。
目前国内的文生视频领域,听说过发布会吗?哪家企业开始宣称自己接近Sora了?
没有。这正是和去年*的区别。
也不能说国内就没有文生视频的研究和应用,大厂也都在筹划相关产品。从抖音转岗剪映的抖音前CEO张楠,上任面临的*个重要任务就是推出AI生图和视频的产品,让剪映在文生视频时代继续成功,从剪辑工具成为一个拥有文生视频能力的造梦工具。张楠就在朋友圈表示,“期待和剪映的小伙伴们一起造梦,与这个AI的时代一起成长,共同绘制出脑海中的奇幻世界”。
Sora虽然抢走了一时的热度,但让整个赛道获得了更多的关注,对国内的文生视频行业也是好事。
尽管如此,大厂们,却普遍更加闷声。BAT以及更多科技企业基本都没怎么“吱声”,要是公司准备上市,上市缄默期还可以理解,但很多推出文生视频的企业显然不在此列。
有的偷偷研发,在开发者社区邀请人做一些内测;有的不声不响地做个产品,但也没有去年文本生成类大模型发布时各家震天响的发布会——大动作才有大效果,去年的众多发布会,让大模型在人们心中的认知度极为普及,其中一些表现优异者,也确实收获了不少商业落地案例。也有科技公司召开发布会的,但主要推的是其他视频能力,文生视频只是一笔带过。
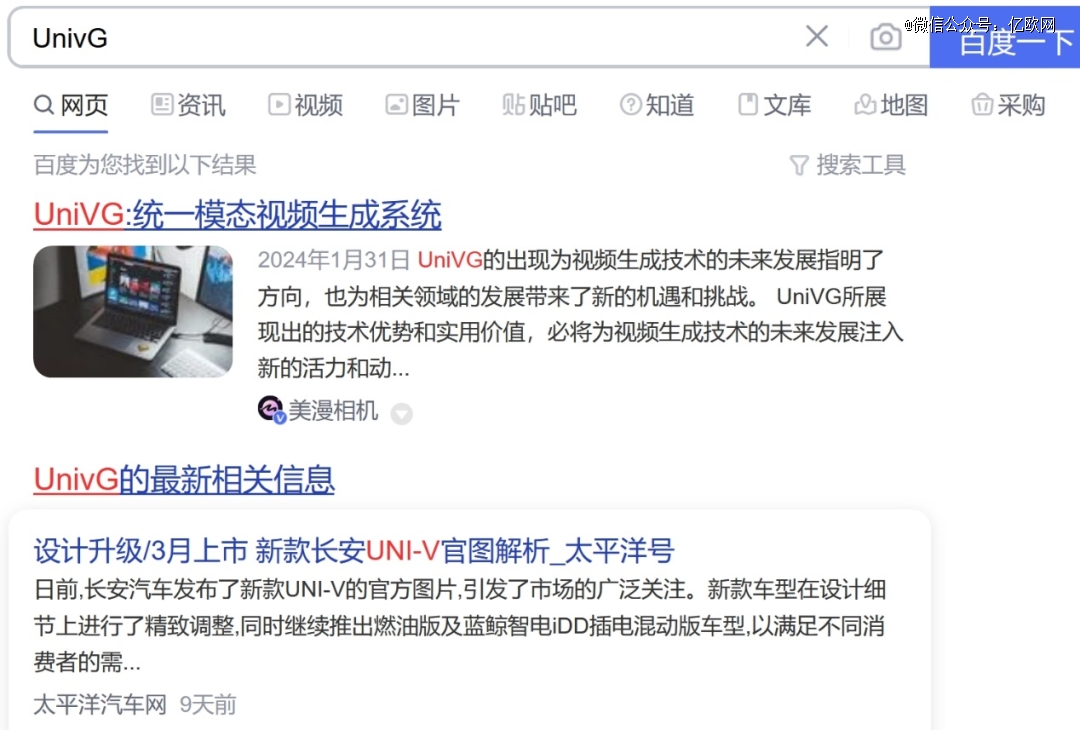
大家基本没有市场推广、没有开发布会,在百度上搜索百度的UniVG视频大模型,甚至*的关键词是长安UNI-V;阿里云达摩院也开发了I2VGen-XL,尽管开放且免费,但也没多少人知道;腾讯的视频生成工具VideoArtisan2,字节跳动的MagicVidGen2,没有中文名,英文名又不像Sora那么好记;此外还有万兴科技、昆仑万维、国脉文化(中国电信旗下)、美图等开始涉足或者更早推出文生视频的企业,也没有多少主动的动作。
文生视频方向,国内大厂难得一致的集体“emo”了,没听说什么动作,似乎尽量都不让别人发现自己也有在做——难道是,文字聊天时,哪怕GPT-4也会回复大量废话,咱们同样生成一些废话也能充数;而文生视频这样的全新应用,不好“糊弄”了?
毕竟文字可以废话——正如电影《年会不能停》里的台词“问题的关键就在于找到关键的问题”,视频怎么说废话?
还别说,最近阿里巴巴集团AI研究院就推出了一款文生视频模型——EMO,用户只需要向EMO提供一张图像、一段音频,就能生成脸部表情丰富的唱歌视频。例如,提供一个张国荣的图像和一首歌曲,就能让其唱歌。
但相比于Sora细致逼真的效果,EMO的文生视频,似乎也有点像古早的幼稚版动画片,画面中人物只有嘴巴等少数几个动作,嘴巴嘚吧嘚吧嘚,配上台词就成了。偶尔试玩或许有趣,但生成唱歌的视频,无非就是改一下面容表情与嘴型变化,震撼性还不足以改变相关产业。
2、Sora离AGI的距离有多近,就看马斯克的脾气有多大
国内企业或许还能忍得住Sora独领风骚,毕竟技不如人的时候,不如偷偷修炼。尽管有不完全统计显示,有近20家上市公司在各自的互动平台上披露了视频生成模型领域相关的业务情况,但都没有大张旗鼓地宣传。
首先忍不住的,是马斯克。
马斯克当地时间2月29日在旧金山高等法院起诉OpenAI CEO萨姆·阿尔特曼(Sam Altman)等人,诉讼文件表述的理由是Altman在2015年与马斯克约定,OpenAI作为非营利机构,将为“人类的利益”开发通用人工智能(AGI),AGI实现之后,将开放其技术,这意味着共享其底层软件代码。
正是基于这些约定,从2016年到2020年,马斯克为OpenAI出资超过4400万美元,并在公司成立之初最困难之时提供了各种支持。尽管后来又有其他个人和机构注资OpenAI,但没有马斯克的*笔帮助,OpenAI也没有机会支撑到后面。
翅膀硬了果然就要飞走,马斯克认为,OpenAI已经成为微软事实上的子公司,只是为了*化微软的利润,而不是造福人类。
按照最初的约定——一旦AGI实现之后就要为了全人类利益开源,放弃(为微软)营利,重回非营利。但OpenAI的章程规定,只有董事会有权判断何时OpenAI的产品才算达成了AGI,OpenAI董事会又专门为微软保留了一个观察员席位,等于什么是AGI是由微软说了算的。
这就是荒谬的“第二十二条军规”,马斯克当然不能忍受。马斯克还在起诉书中非常狠地指出,OpenAI利用非营利机构与盈利下属机构混合的结构,就是在利用规则去钻税法的空子。
当然,这些都是写在表层的原因,不管OpenAI内部的宫斗还是外部的起诉、围堵,最深层次的原因就在于——Sora让更多人,看到了AGI的另一种可能。
马斯克选择这个时间点起诉Altman,真的是因为OpenAI没有造福全人类吗?
或许有,但不全是。更大的可能,是Sora等新产品的发布,让马斯克认为,OpenAI已经接近于实现了AGI,而且会截断特斯拉扩展该领域的可能。此外,传闻中的Q项目,据说也接近于AGI的实现。
推特(X)用户DrKnowItAll就指出,OpenAI的Sora与特斯拉的FSD v12有很多联系。马斯克也回应该用户并向外界披露,“特斯拉一直能够以精确的物理原理生成真实世界的视频,并且大约一年前就已经实现。不过,由于只是根据特斯拉的数据进行训练,因此输出结果并不那么惊艳(局限于特斯拉汽车开车场景)。”
尽管很多人引用马斯克那句“人类愿赌服输”的夸赞,实际上,马斯克内心真正的态度不是夸赞,是气愤。
科技大佬们的心机,都表现在细节里——Altman同样如此,比如,在谷歌刚刚发布Gemini 1.5之后没多久,OpenAI就发布Sora,直接将谷歌的热搜给干没了。
马斯克批评Altman的一点原因,就在于没有坚持开源,OpenAI变成了“ClosedAI”。当Sora等国外*的大模型不再开源、不再公开核心技术细节(Sora的官方技术报告“视频生成模型作为世界仿真器”尽管讲述了Sora的原理,比如扩散模型、视频压缩与patches、隐空间等,但也就是科普水平)之后,面对文生视频对算力更高要求的前提下,中国的科技企业,如何去追赶这种差距?
3、Sora的逻辑混乱,为什么反而更接近AGI
文本模型的差距上,如果我们和OpenAI只差100米,那么图形大模型和OpenAI的Dalle、midjourney等的差距就是1000米,而与Sora的差距更可能是10000米。
文本大模型的成功,是通过使用token来实现的,这些token统一了文本的不同模式——代码、数学和各种自然语言。视觉生成模型也同样继承了大语言模型的优点,只是将token的概念换成patch(视觉补丁)。
视频和图像并没有本质区别,因为图像就是单帧的视频,视频就是多帧的图像。视频生成也是生成一系列具有动作变化和逻辑通畅的图像。
Sora就是将无数视频和图片数据分解为patch作为文生视频大模型训练的基本单元。
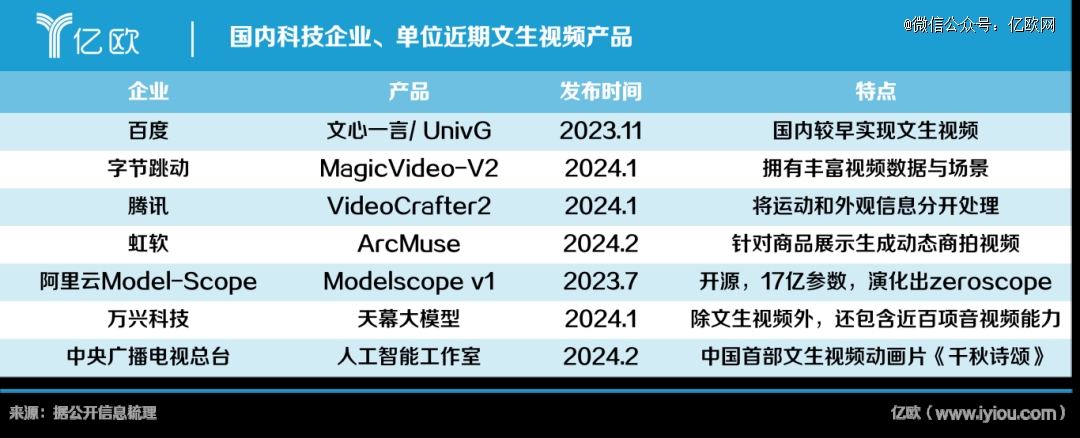
在文生视频上,2023年11月,字节跳动就发表视频生成研究成果PixelDance,2024年1月发布了视频生成模型MagicVideo-V2,此外还在研究Boximator等内部项目。有评测称MagicVideo-V2比其他文生视频模型Gen-2、Stable Video Diffusion、Pika 1.0等更出色。
但官网上的这些示例,和Sora相比,在我们看来,更接近于文生动图,与Sora文生视频的流畅程度、场景复杂度还不能比。
2023年8月,百度文心一言就上线了文生视频等新功能。谷歌的Phenaki、Meta的Make-A-Video,以及国内达摩院,也早在2023年陆续发布文生视频产品。Sora不是*个文生视频模型,只是最惊艳的那一个。
Sora的友商们尽管还达不到Sora展现出来的水平,但中国有阿里、字节、百度、腾讯等企业推进,美国有Pika(创业者是中国留学生)、Phenaki、Make-A-Video、Runway等。
在最近召开的商汤年会上,商汤的如影数字人团队,用几个十来秒的生成视频片段,"复活"了创始人汤晓鸥教授,展现了商汤强大的视频生成能力——创始人的年会脱口秀回归了,逼真的效果惊艳年会全场,也温暖了商汤的所有员工。通过数字技术的极限应用,商汤让我们每个人看到了心中期待的那道光。在中国AI产业面临美国各方面打压限制的时候,商汤不仅在推进技术的进步,也用技术制造了这场浪漫——同样的,中国更多的AI企业或许暂时相比OpenAI还有一些差距,但未来的落地说不定会更早。
幸运的是,目前Sora仅开发给少数“红队测试人员”((针对潜在危险行为的测试))与创作者试用,对公众开放有预计称最快也得今年8月。这也给国内科技企业留出了部分缓冲时间。
而且,现在公开的很多Sora生成视频案例里,都有很多不符合物理定律、现实逻辑的bug,Sora 对物理世界的理解,或许能够精细模拟,仍不够充分,如杯子没有破裂便流水、人物或动物会发生融合或者分离、火焰没有被扰动或是熄灭,越远处细节越少背景人物越像NPC……
有bug,既是国内科技企业追赶的机会,也是AGI(通用人工智能)将加速到来的预示。
为什么这么说?
游戏引擎渲染的画面,一般都不会发生Sora这种逻辑错误,比如游戏主角端着枪走路,不会发生忽然双腿交换的bug。但Sora恰恰走的不是游戏引擎的升级版,而是全新的技术路线。出现一些逻辑混乱,反而更接近AGI——游戏引擎,不出现逻辑错误,但已经没有更多想象;有逻辑混乱,只是AGI深入理解人类世界但一时没琢磨明白的短期阶段。
英伟达人工智能研究主管Jim Fan就指出,很多人没有认识到Sora“数据驱动的物理引擎”特点,Sora从大量视频中通过去噪和梯度算法来学习,从而实现对真实或者虚幻世界的模拟。

Sora视频中出现的一些混乱,让人有兴趣去挑错,甚至一些物理规则的错乱还有魔法一般的效果。挑剔Sora的错误其实没有意义,因为这仅仅只是开始。
比如流传甚广的那段60秒东京街道视频(提示词为“一位时尚女性走在充满温暖霓虹灯和动画城市标牌的东京街道上。她穿着黑色皮夹克、红色长裙和黑色靴子,拎着黑色钱包。她戴着太阳镜,涂着红色口红。她走路自信而随意。街道潮湿且反光,在彩色灯光的照射下形成镜面效果。很多行人走来走去”)中,第15秒处穿黑色皮夹克女性的左右腿忽然互换——而AI生成时却没有发现这处的不合理。
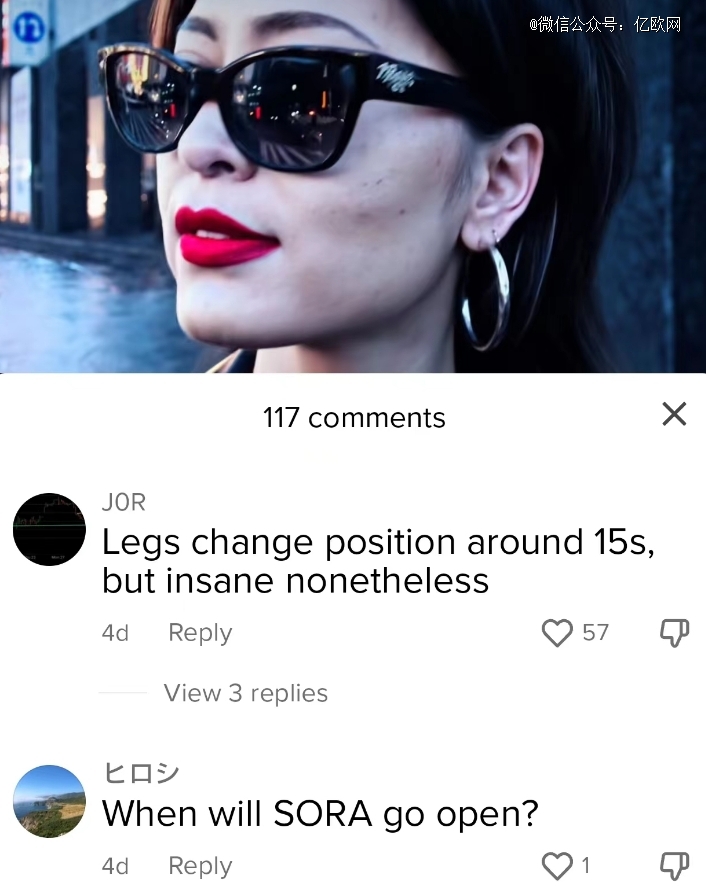
但除此之外,从城市环境到人物穿着、街道特点、人物背景的诸多描述都*实现,皮肤纹理也非常清晰。
AI的效果,依赖于特殊的算法,也依赖于高质量数据的喂养。人类从进入互联网时代之后,就已经创造了无数的数据,这些数据多以文字、图片、视频、语音、数据库等形式呈现,并以各种后缀名的文件存储。Sora让人们看到了,从无数沉睡的视频数据中挖出金矿的可能。
4、Sora一出,谁与争锋?
很多团队或者企业都在跃跃欲试,试图与Sora一较高低。
最近,北大研究团队发起了一项Sora复现计划——Open Sora,计划采用去噪扩散型Transformer等技术原理,实现可变长宽比、可变时长的视频生成。据了解,该项目在8个A100-80G显卡上进行训练,但算力资源依然不够,生成一段分辨率128×128的8帧视频需要一周时间。
正如语言大模型从最初的几百、几千token进化到32K token甚至更长,文生视频模型也在向更高分辨率、更高帧率、更高时长,更真实、精细地模拟真实物理世界进化。
Sora的训练成本,相比文本型大模型,也是指数级的增长。
当我们为了文本型大模型建设算力中心甚至一度担心算力供过于求之时,Sora这个更加耗费算力的新方向又出现了。
国内同行的类似文生视频,在时长、角色一致性、人物皮肤纹理等方面的差距,也有部分是算力的原因。
当然,大家都具备同样的缺点:无法进行人物模型或者环境背景的细节调整,无法生成连续的具备特征一致性的主角,每一次生成都需要很高的算力。
Sora是一个全新的方向,但算力的高门槛,也让初创企业更难进入,或许前期更适合巨头。
中国的文本大语言模型,不论是否真的超越GPT-4,在商业市场中,中国的科技企业,基本已经实现了对ChatGPT的平替。这至少是文本大模型上的一种成功。
中国当然也有很多ChatGPT的付费用户,但这只是C端层面。国内大模型企业的收入主要依赖B端,另外向C端收费仅有百度文心一言4.0等少数。
在文生视频大模型上,据了解,剪映旗下类似Sora的AI视频生成工具Dreamina就在开发并已经开启内测,但具体进展未知。
现在Sora生成的还只是无声视频(仅有背景音乐),更多依靠画面变动去阐述描述词中承载的意向。配合Sora倒是有另外一种创业方向——AI配音。ElevenLabs就根据Sora发布的无声视频,配上声音,从走路的脚步声,到环境的氛围声,都可以精准映射视频。
与文本和图片生成相比,视频生成是一个门槛更高的领域,但也是一个商业化方向更明确的领域,影视制作、*生成、商业片宣传、动漫、短剧、短视频、电子游戏等众多领域,都需要一个能够帮助人们实现文生视频的工具。
对Sora来说,可能限制视频效果的,只有想象力。但对其他文生视频工具来说,现在能不能理解描述词,都是个门槛。
两艘海盗船在一杯咖啡里逐浪而行,互相战斗——我们将该描述词输入另一个文生视频工具NeverEnds,但该工具并没有理解咖啡杯,两艘船还是在大海里。
【本文由投资界合作伙伴微信公众号:亿欧网授权发布,本平台仅提供信息存储服务。】如有任何疑问,请联系(editor@zero2ipo.com.cn)投资界处理。





