 旗下微信矩阵:
旗下微信矩阵:

随着产业数字化浪潮的推进,出版物的形态发生了巨大改变,逐渐走向多样化,这也对校对工作提出了更高的要求。校对工作已不再局限于过去简单的校对方法与模式,需要校对工作者具备更高的专业素质和能力。
随着人工智能技术高速发展,业界对智慧出版的关注又一次迎来热潮。如何将各类人工智能技术应用在出版领域,如何用大模型再造出版实施流程、优化与创新商业模式,已成为出版业和学界普遍关注的焦点。2023年7月10日,由国家网信办联合国家发展改革委、教育部、科技部、工业和信息化部、公安部、广电总局等七部委联合发布《生成式人工智能服务管理暂行办法》。此前,国内与国外已有为数不少的图书作者、出版社编辑和科研人员纷纷体验了大模型的能力。
图书质量既是图书出版的底线,更是出版社的生命线。提升图书质量成为出版从业者的重要任务,然而在完成这一重要任务的过程中,出版机构也面临着诸多挑战。
挑战一 出版量大、差错类型多
国家新闻出版署公布的《2021新闻出版行业基本情况》显示,2021年,全国出版新版图书达到了225253种,重印图书303944种。可见我国图书种类之多,出版业之繁荣。
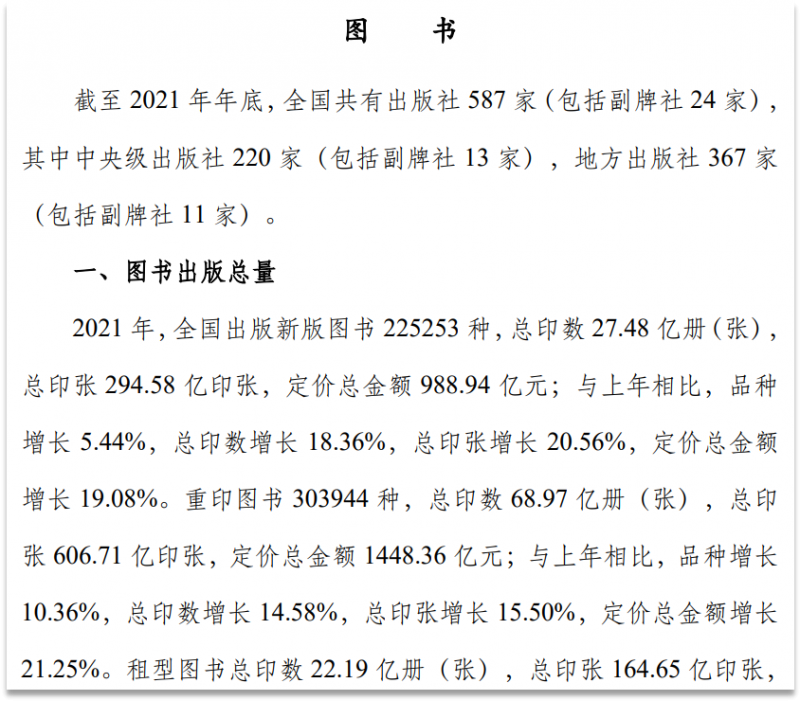
来源:国家新闻出版署《2021新闻出版行业基本情况》
为保障图书出版的质量,有关管理部门及各出版单位会定期或不定期地对图书编校质量进行检查。根据《图书质量管理规定》,差错率超过万分之一的图书属不合格。图书出版涉及多个环节,包括选题、编辑、校对和印刷,每个环节都需严谨细致。文字差错可能导致读者困扰和误解,影响图书质量和出版社形象。

来源:国家新闻出版署
在国家新闻出版署开展的图书“质量管理2022”专项工作中,国家新闻出版署对于编校质量不合格图书进行了通报。《通报》显示,国家新闻出版署重点对2021年以来出版的社科、文艺、少儿、教辅和科普等类别图书进行编校质量检查,共组织抽查102家出版单位的306种图书。经审核,认定其中64种图书差错率超过万分之一。
图书编校质量的检查重点在于对图书辅文及正文的检查。辅文部分不但有标点符号差错,还可能存在人名、叙述等与正文不一致的问题。正文部分的检查则更加严格,需要检查引号、书名号里的文字,人名地名等专有名词用字是否准确,是否多字漏字;所述的事件是否与年代相符,知识点是否陈旧过时等问题。这些不同类型的内容差错对于保障图书质量构成了不小的挑战。
挑战二 出版周期紧、人工审校压力大
在图书出版审校环节中,从业者需要严格遵守三审三校的制度。在此过程中,责任编辑需全面审阅稿件内容,精确校正文字疏漏。但在应对大量稿件时,人工审校的效率难以满足出版周期方面的要求。
接下来,我们来看看文修智能校对大模型在图书出版审校方面,能发挥哪些作用。
审校覆盖多类型 为图书内容质量保驾护航
文修以大模型为技术底座,实现语言规律的学习和行业知识的复用,将出版行业的隐性知识转化为可复用的显性知识,进而依据出版领域的行业规范、标准和业务知识,形成文字标点差错、知识性差错、内容导向风险识别三大审核与校对类型。
对于文字标点差错,文修大模型通过深度学习语言规律,能够精准识别并纠正文本中的错别字、标点符号使用不当等问题。
对于知识性差错,文修大模型依托其强大的知识库和推理能力,对文本中的事实性错误、概念性偏差等进行智能识别和提示,帮助用户及时发现并修正内容中的知识性问题。
对于内容导向风险识别,文修大模型结合出版领域的行业规范、标准和业务知识,对文本进行深度分析和评估,有效识别潜在的内容导向风险。
校对效率高 有效提升出版行业办公效率
一本20万字的书稿,如果采用传统的校对方式,可能需要数天的时间才能完成。而使用文修大模型,整个校对过程仅需90秒即可完成,为大幅缩短出版周期提供了良好基础。
结语
2023年7月,蜜度在世界人工智能大会期间,发布了自研的文修智能校对大模型。2024年3月22日,文修智能校对大模型2.0在天津发布,相较于1.0版本,文修智能校对大模型2.0的训练参数规模增至70亿,基础预训练模型的数据量超过1万亿词符,校对任务训练数据也超过5000亿词符。

目前,文修智能校对大模型能力已落地应用在蜜度旗下“蜜度校对通”产品中,并在多行业实现商业化落地。
未来在出版行业中,人机协同的工作模式或将成为主流趋势。蜜度将继续提供智能、安全、高效的“AI+”解决方案,为出版单位提供专业、可靠、高效的内容导向筛查及文字质量把关服务,助力出版单位守牢防线,保障图书出版质量。









