
AI 时代就这么悄悄降临了。
大概谁也没想到,今年春节,打的最热的不再是传统互联网的红包大战,谁和春晚合作了,而是 AI 公司。
临近春节,各家大模型公司都完全没放松,更新了一波模型和产品,而最受关注的,却是去年崭露头角的「大模型公司」DeepSeek(深度求索)。
1 月 20 日晚,DeepSeek 公司发布推理模型 DeepSeek-R1 正式版,使用低廉的训练成本直接训练出了不输 OpenAI 推理模型 o1 的性能,而且完全免费开源,直接引发了行业地震。
这是*次国产 AI 大范围在全球,特别是美国引起了科技圈的震动。开发者纷纷表示,正在考虑用 DeepSeek「重构一切」,在这一浪潮下,经过一周的发酵,甚至一月才刚刚发布的 DeepSeek 移动端应用,迅速登顶美区苹果应用商店免费 App 排行*,不但超越了 ChatGPT,也直接超越了美区的其他热门应用。
DeepSeek 的成功甚至直接影响了美股,没有使用巨量昂贵 GPU 就训练出的模型,让人们重新思考了 AI 的训练路径,直接让 AI *股英伟达*跌幅达到 17%。
而这还没结束。
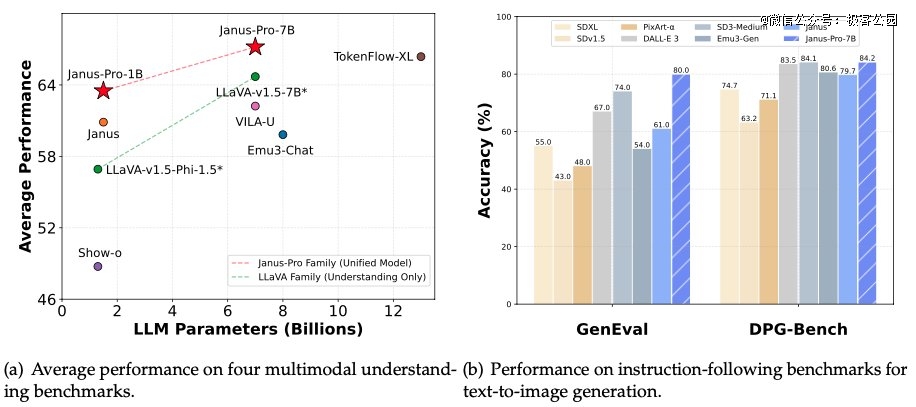
1 月 28 日凌晨,除夕夜前一晚,DeepSeek 又开源了其多模态模型 Janus-Pro-7B,宣布在在 GenEval 和 DPG-Bench 基准测试中击败了 DALL-E 3(来自 OpenAI)和 Stable Diffusion。
DeepSeek 真的要血洗 AI 圈了吗?从推理模型到多模态模型,拿 DeepSeek 重构一切,是蛇年开年的*主题吗?
01
Janus Pro,多模态模型创新架构的验证
Janus Pro,多模态模型创新架构的验证
DeepSeek 此次深夜一共发布了两个模型,Janus-Pro-7B 和 Janus-Pro-1B(1.5B 参数量)。
从命名上就能看出,模型本身来自之前 Janus 模型的升级。
2024 年 10 月,DeepSeek 才*次发布 Janus 模型。和 DeepSeek 的一贯套路一样,模型采取了一个创新的架构。在不少视觉生成模型中,模型都是采用了统一的 Transformer 架构,能够同时处理文生图和图生文任务。
而 DeepSeek 则是提出了一种新的思路,对理解(图生文)和生成任务(文生图)的视觉编码进行解耦,提升了模型训练的灵活性,有效缓解了使用单一视觉编码导致的冲突和性能瓶颈。
这也是 DeepSeek 为什么将模型命名为 Janus (杰纳斯)。Janus 是古罗马门神,被描绘为有分别朝向相反方的两个面孔。DeepSeek 表示命名为 Janus,指的是模型可以像 Janus 一样,用不同的眼睛看向视觉数据,分别编码特征,然后用同一个身体 (Transformer) 去处理这些输入信号。
在 Janus 系列模型中,这种新思路已经产生了不错的效果,团队表示,Janus 模型的指令跟随能力很强,有多语言能力,且的模型更聪明,能读懂 meme 图像。同时还能处理 latex 公式转换、图转代码等任务。
而在 Janus Pro 系列模型中,团队对模型的训练流程进行了部分修改,直接做到了在 GenEval 和 DPG-Bench 基准测试中击败了 DALL-E 3 和 Stable Diffusion。
随着模型本身,DeepSeek 也发布了 Janus Flow 新型多模态 AI 框架,旨在统一图像理解与生成任务。
Janus Pro 模型能做到使用简短提示提供更稳定的输出,具有更好的视觉质量、更丰富的细节以及生成简单文本的能力。
模型既可以生成图像,也可以对图片进行描述,识别地标景点(例如杭州的西湖),识别图像中的文字,并能对图片中的知识(如「猫和老鼠」蛋糕)进行介绍。
X 上不少人已经开始试用新模型。
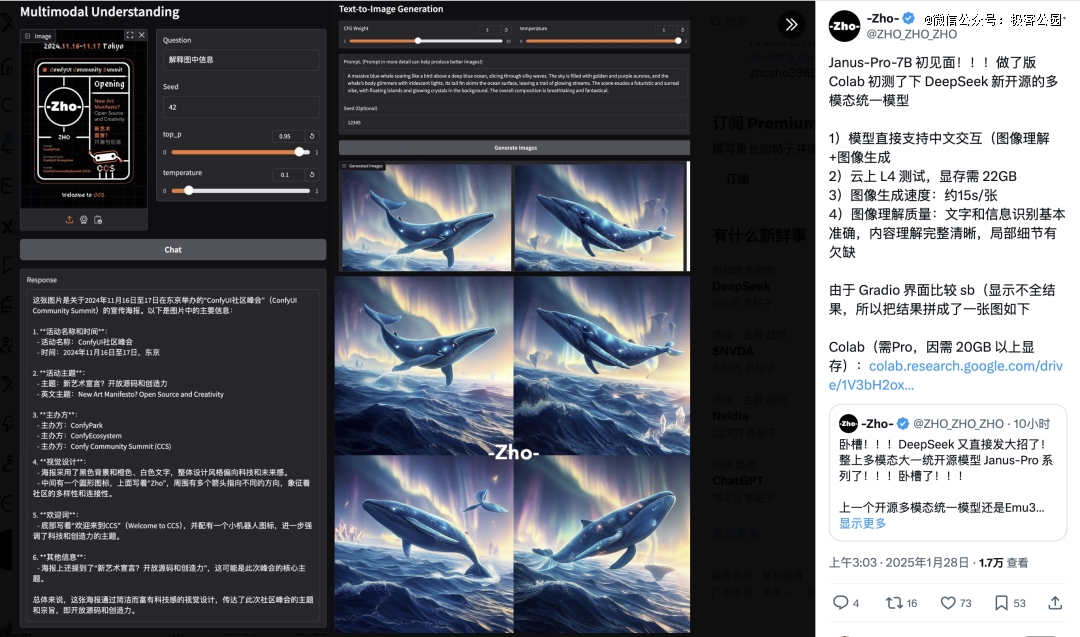
上图左为图像识别的测试,右图则为图像生成的测试。
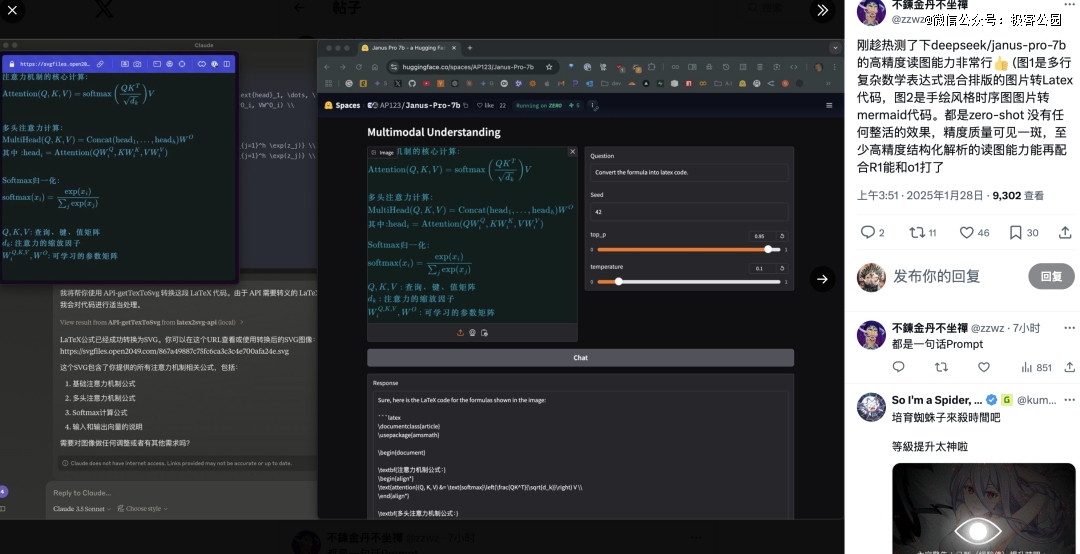
可以看到,在高精度读图上,Janus Pro 也做的很好。能够识别数学表达式和文字的混合排版。未来搭配推理模型使用,可能有更大意义。
02
1B 和 7B 的参数量,或能解锁新应用场景
在多模态理解任务中,新模型 Janus-Pro 采用 SigLIP-L 作为视觉编码器,支持 384 x 384 像素的图像输入。而在图像生成任务中,Janus-Pro 使用一个来自特定来源的分词器,降采样率为 16。
相对而言,这样的图像规模尺寸仍然较小。X 上有用户分析认为,Janus Pro 模型更多是方向上的验证,如果验证靠谱,就会推出可以投入生产的模型了。
不过值得注意的是,此次 Janus 发布的新模型,不但在架构上对多模态模型有创新意义可以参考,在参数量上,也是一个新的探索。
此次 DeepSeek Janus Pro 对比的模型,DALL-E 3,之前公布的参数量为 120 亿,而 Janus Pro 的大尺寸模型只有 70 亿参数。在这样紧凑的尺寸下,Janus Pro 能够做到这样的效果已经十分不错。
尤其是 Janus Pro 的 1B 模型,只使用了 15 亿参数。外网上已经有用户将对模型的支持添加到了 transformers.js。这意味着模型现在可以在 WebGPU 上的浏览器中 100%运行!
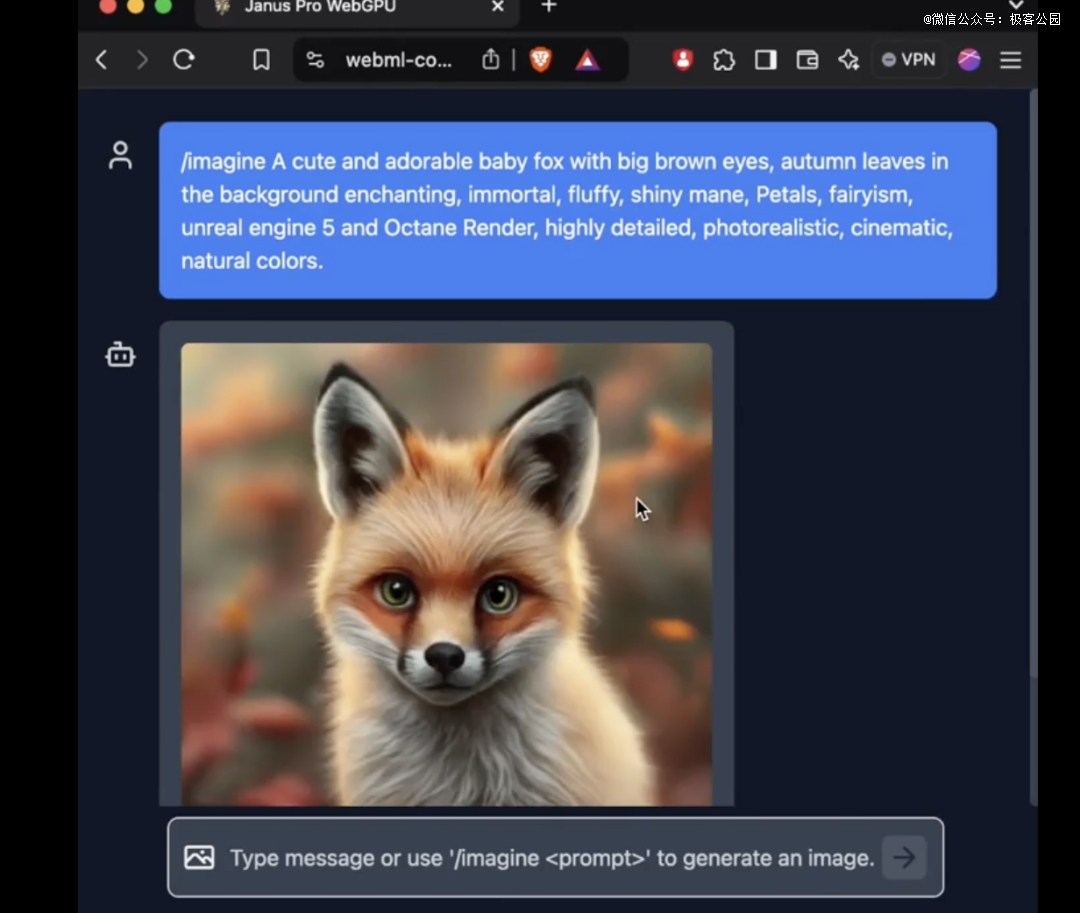
虽然截止发稿,笔者还没能成功地在网页版上使用到 Janus Pro 的新模型,但是参数量小到能够在网页端直接运行,仍然是一项令人惊叹的进步。
这意味着图片生成/图片理解的成本,正在进一步下降。而我们有机会在更多原本无法使用生图和图片理解功能的地方,看到 AI 的使用,改变我们的生活。
2024 年的一大热点,在于加入了多模态理解的 AI 硬件,能够如何介入我们的生活。而参数量越来越低的多模态理解模型,或者可以让我们期待能够在端侧运行的模型,能够让 AI 硬件进一步爆发。
03
DeepSeek 搅动新年,万事万物可以用中国 AI 重做一遍?
AI 世界一日千里。
去年春节前后,搅动世界的是 OpenAI 的 Sora 模型,而一年下来,中国公司已经完全在视频生成方面迎头赶上,让年尾 Sora 的发布显得有些暗淡了。
而今年搅动世界的,变成了中国的 DeepSeek。
DeepSeek 并不算传统的科技公司,然而用远低于美国大模型公司 GPU 卡和成本,做出了极其创新的模型,直接让美国同行感到震动——美国人纷纷感叹:R1 模型的训练,仅仅花费 560 万美元,甚至只相当于 Meta GenAI 团队任一高管的薪资,这是什么神秘的东方力量?
一个模仿 DeepSeek 创始人梁文峰的 parody 账号直接在 X 上发布了一张有趣的图片:

图片使用了爆火的 2024 年全球爆火的土耳其射击选手的梗。
在法国巴黎奥运会射击项目10 米气手枪决赛中,51 岁的土耳其射击男选手迪凯奇,仅佩戴了一副普通的近视眼镜和一对睡眠耳塞,便以单手插兜的潇洒姿态,稳稳地将银牌收入囊中。而在场的全部其他射击选手都需要两块聚焦和遮光的专业镜片和一副防噪声耳塞,才能开始比赛。
自从 DeepSeek「破解」了 OpenAI 的推理模型,美国各大科技公司开始背上了巨大的压力。今天,Sam Altman 也终于扛不住压力出来回应了一段官方发言。
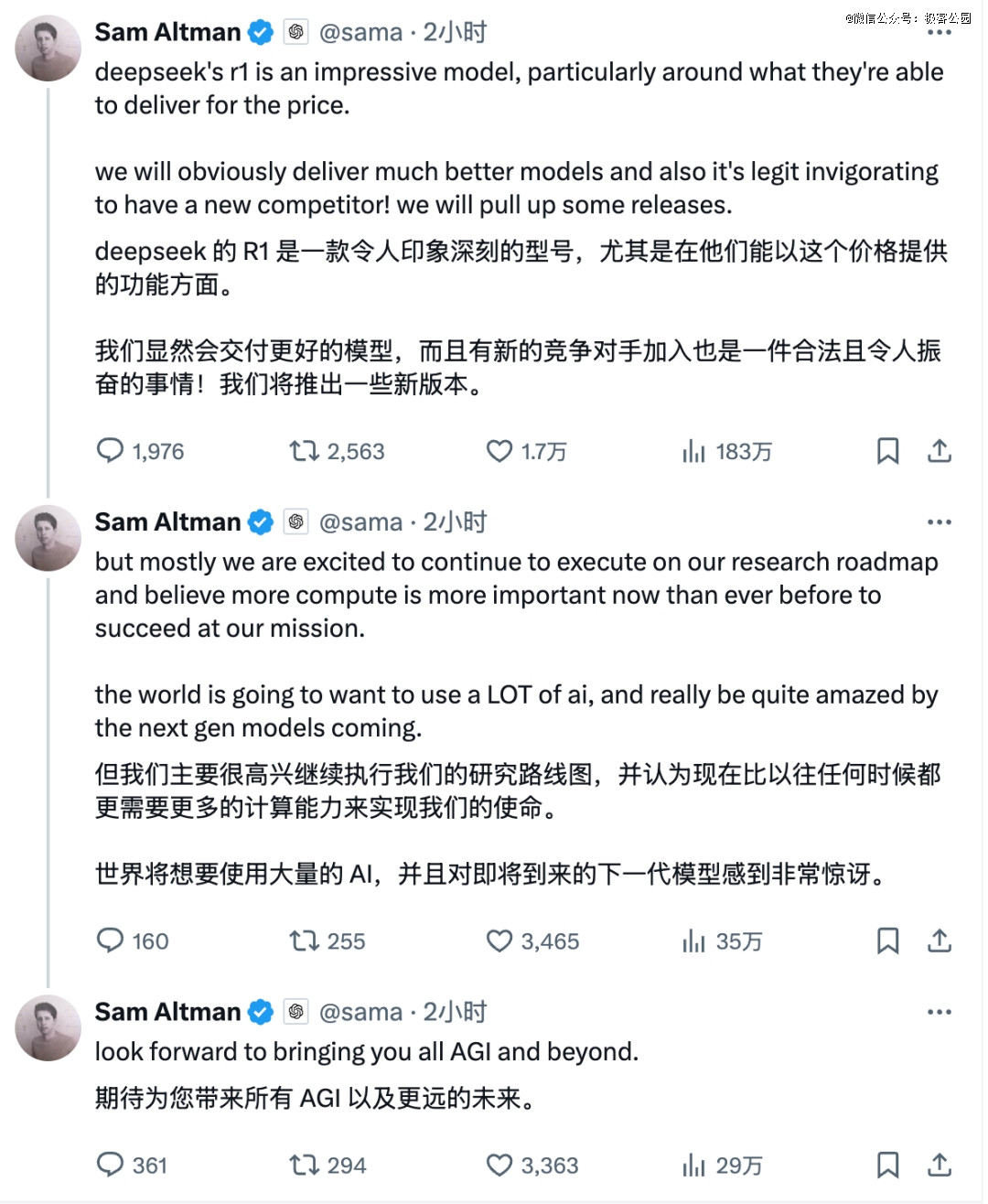
2025 年,会是中国 AI 冲击美国认知的一年吗?
DeepSeek,手里还藏着什么秘密——这注定是个不平凡的春节。
【本文由投资界合作伙伴微信公众号:极客公园授权发布,本平台仅提供信息存储服务。】如有任何疑问,请联系(editor@zero2ipo.com.cn)投资界处理。





