
深度神经网络(DeepNeuralNetworks, DNNs)由于跨域不匹配(cross-domain mismatch),通常在新域表现不佳。而无监督域自适应(UDA)技术则可通过利用未标记的目标域样本缓解跨域不匹配问题。近日,特斯联科技集团首席科学家、特斯联国际总裁邵岭博士及合作者们提出了基于类别对比的新颖方法Category Contrast (CaCo),并公布了所取得的最新研究成果。该方法在视觉UDA任务的实例判别之上引入了语义先验。该研究成果(标题为:Category Contrast for Unsupervised Domain Adaptation in Visual Tasks)已被今年的 AI顶会CVPR(国际计算机视觉与模式识别会议)收录。
通过将实例对比学习视为字典查询操作,团队利用源域和目标域的样本构建了一个类别感知(category-aware)和域混合(domain-mixed)的字典,其中每个目标样本会根据源域样本的类别先验被分配一个(伪)类别标签,并为UDA提供了相应的类别对比损失(category contrastive loss)。由此鼓励学习完全契合UDA目标的,具有类别判别力但域不变的(category-discriminative yet domain-invariant )表征:同类别样本(无论是来自于源域或者目标域)的距离被拉得更近的同时不同类别样本的距离会被推远。在多种视觉任务(例如分割、分类和检测)中进行的大量实验表明CaCo实现了与当前*进的算法相比更*的性能。此外,实验也显示CaCo可以作为现有UDA方法的补充,并可推广到其它的学习方法中,如无监督模型适应、开放/半开放集域自适应等。
无监督域自适应缓解跨域不匹配
无监督域自适应(UDA)的目的在于通过利用未标记的目标域样本减少轻跨域不匹配问题的影响。为了实现这一目的,科研工作者们针对目标域样本设计了不同的无监督训练目标函数,以在目标域中训练出一个性能良好的模型。现有的无监督损失可以大致分为三类1)对抗性损失函数(adversarial loss):迫使模型学习类似源域的目标表征;2)图像转换损失函数(image translation loss),将源图像转换为具有类似目标的样式和外观;3)自训练损失(self-training loss),用置信度较高的伪标记样本迭代地重新训练网络。
无监督表征学习解决了一个相关问题,即无监督网络预训练,旨在从未标记的数据中学习有判别力的嵌入。近年来,实例对比学习在无监督表征学习方面取得了重大进展。尽管动机不同,实例对比方法可以被看作是一种字典查询式任务,通过将编码查询(encoded query)q与由多个编码键(encoded keys)k构成的字典匹配来训练视觉编码器:编码查询应与编码的正键(encoded positive keys)相似,而与编码的负键(encoded negative keys)相异。由于没有可用于未标记数据的标签,正键通常是查询样本的随机增强版本,而所有其他样本都被视为负键。
在这样的背景下,邵岭博士及团队探究了UDA中实例对比的概念。在把对比学习看作字典查询任务的基础上,团队假设 UDA 字典应该是类别感知的(category-aware),并且应该与来自源域和目标域的键进行域混合(domain-mixed)。直观来说,一个包含类别平衡键(category-balanced keys)的可感知类别的字典可以促进学习类别判别力(category-discriminative)但类别无偏的(category-unbiased)表征,而来自源域和目标域的键将允许学习两个域内和跨域的不变表征,这两点都与UDA的目标相符。
以类别对比方法构建具有类别感知和域混合的字典
团队提出,用类别对比方法(CaCo)来构建具有类别感知和域混合的字典,并为UDA提供相应的对比损失函数。如图1所示,该字典包含在类别和域中均匀采样的键,其中每个目标键都有一个预测的伪类别。以说明性字典K = {![]() }1≤c≤C,1≤m≤M 为例。每个类别c都含有M个键而每个域含有(C × M)/2个键。
}1≤c≤C,1≤m≤M 为例。每个类别c都含有M个键而每个域含有(C × M)/2个键。
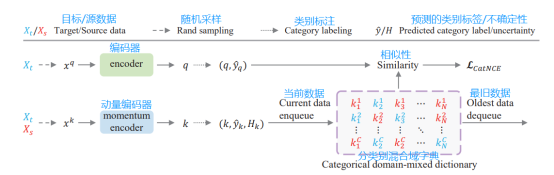
图1
图 1中,团队提出的类别对比方法通过类别对比损失函数![]() 将查询q(来自未标记的目标样本
将查询q(来自未标记的目标样本![]() )与由键组成的字典相匹配,来训练一个无监督域自适应编码器。字典键来自源域
)与由键组成的字典相匹配,来训练一个无监督域自适应编码器。字典键来自源域![]() (图中红字,带标签)和目标域
(图中红字,带标签)和目标域![]() (图中蓝字,带伪标签)的域混合,这样可以学习域内和跨域的不变表征。 这些键也是类别感知和类别平衡的,这样可以学习类别具有类别区分力的但无偏的表征。注意类别平衡指每个查询q与字典中的所有键(在损失计算中)相比较,这些字典键均匀分布在所有的数据类别中,缓解了数据不平衡。
(图中蓝字,带伪标签)的域混合,这样可以学习域内和跨域的不变表征。 这些键也是类别感知和类别平衡的,这样可以学习类别具有类别区分力的但无偏的表征。注意类别平衡指每个查询q与字典中的所有键(在损失计算中)相比较,这些字典键均匀分布在所有的数据类别中,缓解了数据不平衡。
因此,网络学习将努力最小化目标查询和字典键之间的类别对比损失![]() :相同类别的样本被拉近而不同类别的样本被推远。这自然会产生完全符合 UDA 目标的,具有类别判别力的但域不变的表征。
:相同类别的样本被拉近而不同类别的样本被推远。这自然会产生完全符合 UDA 目标的,具有类别判别力的但域不变的表征。
在类别感知和域混合字典以及类别对比损失函数的应用下,所提出的类别对比通过三个理想的特征来解决 UDA 挑战:1)利用类别感知字典设计,同时最小化类别内变化并*化类别间距离;2)依靠同时包含源域样本和目标域样本的混合域字典设计同时实现了域间和域内对齐;3)依靠类别平衡字典设计有效缓解了数据平衡问题,使得在学习过程中均匀计算所有类别的对比损失。
大量实验结果表明类别对比方法展现优异性能
团队分享了其实验结果,分为以下几个维度。
泛化能力:团队通过评估CaCo在多个基础视觉UDA应用,即分割、检测和分类,中的性能效果来研究它的泛化能力。实验结果显示CaCo始终展现出了与当前*进的方法相当的性能。
互补能力:团队探究了CaCo与现有的UDA方法相结合的协同优势。这表明当加入 CaCo时,可以在不同的视觉任务中一致地改进所有现有方法。
与现有的无监督表征学习方法对比:团队将CaCo与无监督表征学习方法用于UDA任务以进行对比。大多数现有的方法通过某些前置任务实现了无监督表征学习,比如说实例对比学习、图像块排序(patch ordering)、旋转预测和降噪/上下文/着色自编码器。在UDA任务GTA→Cityscapes上进行的实验显示了现有的无监督表征学习应用于UDA任务时效果不理想。主要原因是这些方法是针对学习可用于判别实例的表征(instance-discriminative representations)而设计的,并没有考虑到语义先验和域间隙(domain gaps)。CaCo也被用于进行无监督学习,应用于UDA时更有效,很大程度上是因其学习了具有类别判别力且域不变的表征,而这些表征对于多种视觉UDA任务是至关重要的。
参数研究:参数M(在提出的CaCo中)控制了分类别字典的长度(或者说大小)。团队将M从50逐渐调至150,对其进行了研究。在UDA分割任务GTA-to-Cityscapes上进行的实验显示了M在50至150之间进行调整时,对UDA的影响并不明显。
不同学习类型中的泛化:团队从学习类型的角度研究了所提出的CaCo的可扩展性。具体而言,团队把CaCo应用于多种涉及无标签数据学习和某些语义先验的任务,如无监督模型自适应和半开放集/开放集UDA,并对其进行评估。结果显示CaCo的可以稳健展现与当前*进的方法相当的性能。
类别感知字典:团队研究了提出的类别感知字典的3种变体设计: 1) 为所有的键分配同样的温度参数;2)(对于源数据和目标数据)使用两个独立的字典而不是一个单独的域混合字典;3)使用内存库或当前小批量(current mini-batch)来更新字典。实验证实了设计的优越性。
总体而言,邵岭博士及团队提出了一种类别对比方法CaCo,该方法引入了通用的类别对比损失函数(generic category contrastive loss),可有效用于多种视觉UDA任务。团队用来自源域和目标域的样本构建了一个语义感知字典,域中的每一个目标样本都根据源域样本的类别先验被分配了一个(伪)类别标签。这使得(目标查询和类别级的字典间的)类别对比学习可以学习具有类别判别力且域不变的表征:同类别的样本(无论是来自于源域或者目标域)会被拉近而不同类别的样本被同时推远。在多种视觉任务(例如分割、分类和检测)中进行的大量实验显示单独使用CaCo就可以展现出与当前*进的方法相当的性能。另外,实验也显示CaCo可以与现有的UDA方法互补,也可以外推至其他的学习类型,如无监督模型自适应、开放/半开放集域自适应等。
