
GPU(Graphics Processing Unit)图像处理器,俗称显卡,因20世纪的电子游戏而生,却因21世纪的虚拟货币、科学超算、人工智能、大数据、云计算、数字孪生、自动驾驶、元宇宙和Web3.0等等多重数字经济未来趋势的合成共振,成为全球工业界和金融界一致认可的*确定性的高成长高价值硬科技赛道。
01、GPU赛道空间巨大、前景广阔
GPU分为独显和核显两大类。
服务器级的高性能GPU,俗称独显,性能强劲,功耗一般在百瓦以上。全球范围内,这一领域一直被两家美国公司把持,一家是Nvidia英伟达,另一家是AMD超威。高性能GPU也成为了美国可以随意挥舞的科技大棒中,*经济价值和未来价值的一个。
市场上容易混淆的还有GPGPU(General Purpose GraphicsProcessing Unit),这是将GPU中的渲染模块简化,只保留计算模块的方案,因而图形处理能力为零,它与高性能GPU(独显)是不可同日而语的。
图1.英伟达历年分产品线营收
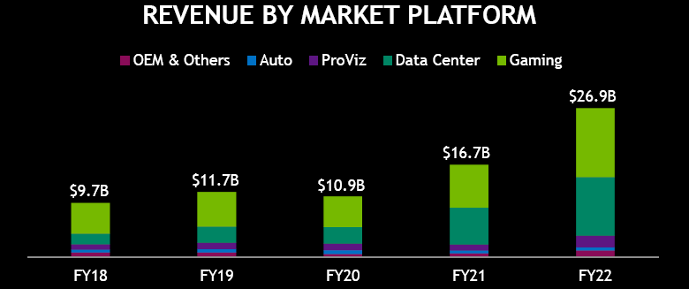
过去五年Nvidia英伟达各条产品线的营收稳步成长。2022财年实现营收合计达269亿美元(约1819亿人民币),游戏显卡(Gaming)营收125亿美元(全部为GPU),占比46%,数据中心产品(Data Center)营收106亿美元(部分GPU,部分GPGPU),占比40%,专业视觉渲染(ProViz)营收21亿美元(全部为GPU),占比8%,自动驾驶(Auto)营收5.7亿美元,占比2%。英伟达65%以上的营收来自GPU。
移动端屏幕也需要图形渲染,此类移动GPU往往以IP的形式和CPU集成为一个SoC出货,俗称核显。手机,平板及车机等领域由于采用电池供电,对功耗有着严苛的要求,整个SoC的功耗一般在10瓦左右,比高性能的GPU至少小了一个数量级。
核显门槛相对较低,竞争格局较为分散,主要的IP供应商有ARM,Imagination和Verisilicon芯原。另外有两家美国公司也有自用的核显能力,一家是Qualcomm高通的手机芯片,另一家就是Intel的PC芯片。
02、GPU的理论基础——实时计算机图形学
图2. 实时计算机图形学渲染管线
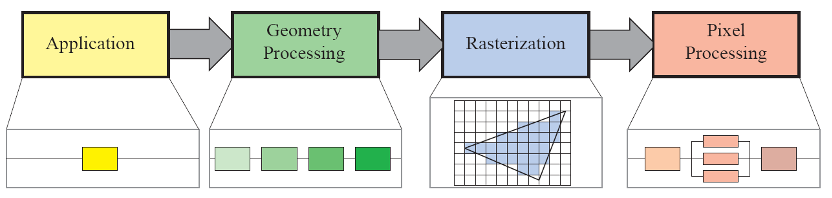
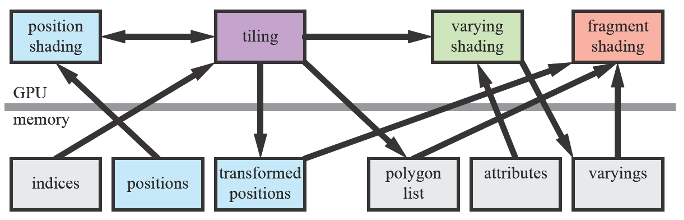
GPU的理论基础是实时计算机图形学(real-time computer graphics),它的渲染管线包括应用application,几何处理geometry processing,光栅化rasterization和像素处理pixel processing四个阶段。其中应用层级的开发一般在CPU进行,而后三个阶段几何处理、光栅化和像素处理(可以细分为如图所示的八个步骤),它们就是GPU要用数十亿个晶体管要实现的事情。
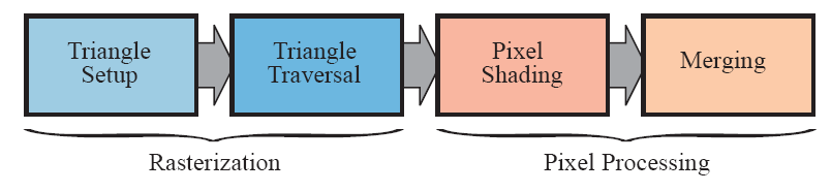
图3. 几何处理、光栅化和像素处理

03、独显有多复杂?——以GTX1080为例
GPU要实现对二维屏幕上每一个像素点的输出,需要很多个并行工作的着色处理器shader processor同步工作,示意图中将硬件中的四个小处理器连为一组,软件层面将各类渲染任务按4个thread打成一个卷warp发给硬件,同时加入了多warp切换的机制,保证了GPU任务执行的高效性。
图4. GPU渲染管线示意图
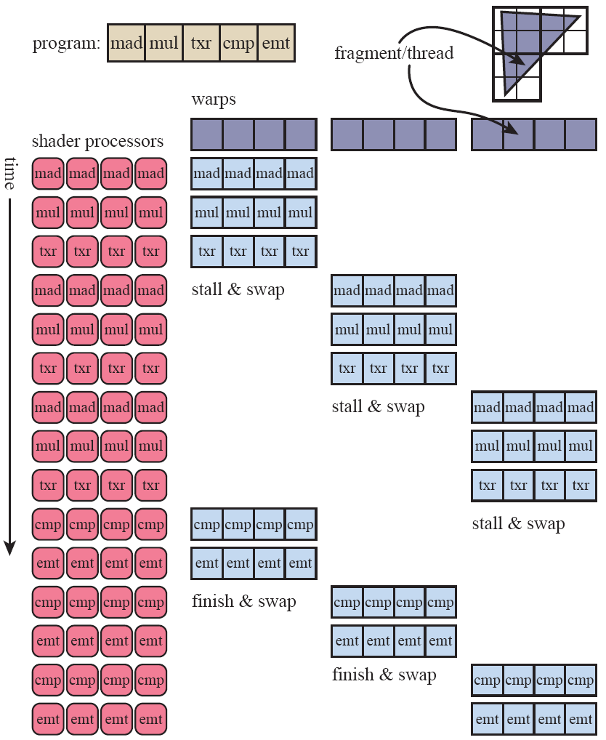
下面让我们通过拆解Nvidia GTX 1080这一架构实例,感受下独显的复杂度。
GeForceGTX 1080是Nvidia于2016年发布的Pascal架构的GPU芯片。Pascal架构将用于图形处理的部分去除,仅保留通用的ALU单元后,即可产生专用于AI计算的GPGPU(General-PurposeGPU)芯片,著名的Tesla P100。如减少GPU内核数量,加入CPU控制核,降低算力和功耗,形成SoC芯片,就成为同样知名的Jaston TX2边缘计算芯片。以上芯片均可以让用户方便的在不同的场景采用Nvidia知名的Cuda软件栈,其核心是硬件层面都采用了统一的Pascal架构的GPU内核,这是Nvidia具备超高生态壁垒的底层技术基础。
1080中使用了Nvidia统一的ALU-CUDA内核架构如图所示。ALU主要负责浮点和整数运算。为了提高计算能力, ALU被合并到流多处理器(SM)中。在Pascal中,SM由四个处理块组成,每个处理块有32个ALU。这意味着SM可以同时执行32个线程的4个Warp。每个处理块,即宽度为32的SIMT引擎,也有8个加载/存储(LD/ST)单元和8个特殊功能单元(SFU)。加载/存储单元处理读取并将值写入寄存器。即16384×4字节,即每个处理块64 kB,每个SM总计256 kB。SFU处理超越函数指令,例如正弦、余弦、指数(以2为底)、对数(基数2)、倒数和倒数平方根。
图5. ALU单元和multiprocessor示意图
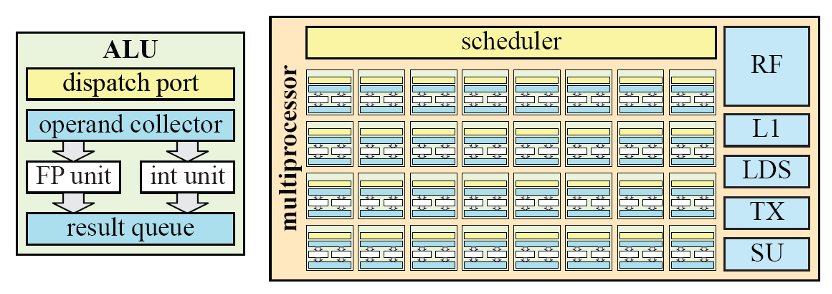
SM中的所有ALU共享一个指令缓存,而每个SIMT引擎具有它自己的指令缓冲区带有一组最近加载的本地指令,以进一步增加指令缓存命中率。Warp调度程序能够调度每个时钟周期有两条Warp指令,可以调度到两个ALU和LD/ST单元处于同一时钟周期。每个SM还有L1缓存24 kB的存储空间,即每个SM 有48 kB。每个SM有8个纹理单元。
图6. SM架构图
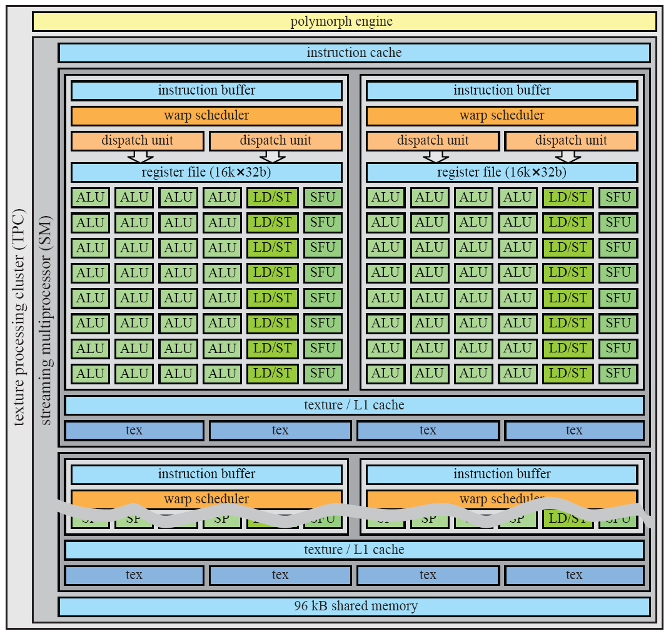
由于着色必须在2×2像素的四边形中完成,因此Warp调度程序可以将8个不同的像素四边形组合在一起,以便在32 SIMT中执行。由于这是一个统一的ALU设计,warp调度程序可以将其中一个分组顶点、像素、基本体或计算着色器打包成一个warp。SM可以同时处理不同类型的warp(例如顶点、像素和基本体)。切换当前正在执行和准备执行的warp的开销为零。
SM与多形引擎(PM)协同工作。PM可执行几何相关的任务,包括顶点提取、细分、同时多投影、属性设置和流输出。*阶段从全局顶点缓冲并将Warp发送到SM以进行顶点和外壳着色。然后是可选的细分阶段,其中新生成的(u,v)坐标被调度到SM,用于域着色和几何体着色。第三阶段处理视角变换和透视校正。接下来是可选第四阶段,顶点流式输出到内存。最后,结果转发到相关光栅引擎。光栅引擎有三个任务,即三角形设置、三角形遍历和z消隐。三角形设置获取顶点,计算边方程,并执行背面剔除。三角形遍历使用分层平铺遍历技术来处理重叠的三角形。它使用边缘方程来执行平铺测试并进行内部测试。如果剔除了一个图块,则立即终止对该图块的处理。流处理器与多形引擎耦合称为纹理处理集群(TPC)。在更高的层次上,五个TPC被分组到一个图形处理中集群(GPC),具有一个为这五个TPC服务的光栅引擎。GPC可以认为是一个小型GPU,其目标是提供一组平衡的硬件单元用于图形,例如顶点、几何体、光栅、纹理、像素和ROP的处理。
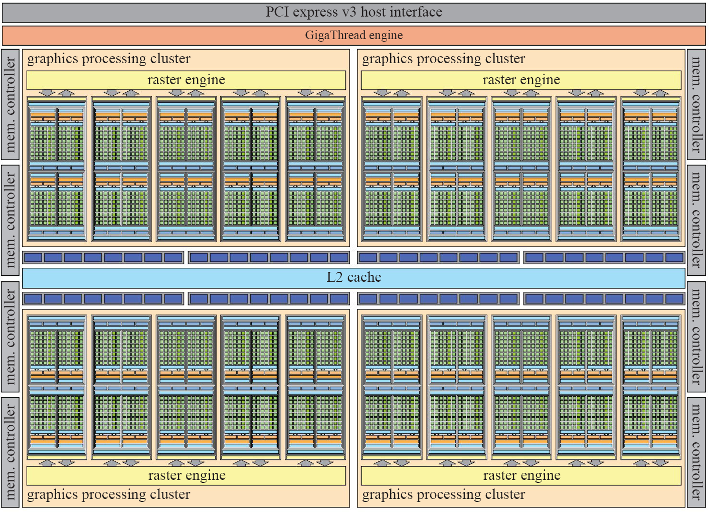
经典的GeForce GTX 1080架构如下图所示,大功告成。
图7. GeForce GTX 1080架构
04、核显IP能做高性能独显么?
中国国有资本全资间接收购英国Imagination后,众多创业企业纷纷试图利用移动端GPU IP改造成独显高性能芯片,似乎找到了高性能GPU自主可控的“终南捷径”。然而这条路真的能走通么?
不同于独显,在移动GPU领域功耗是有上限的。试想如果拿一个百瓦级功耗的手机,不仅用电量根本无法接受,甚至手都会被烫熟。
GPU功耗*的消耗是对外部存储器的访问。于是如何降低对外部存储器的访问量,进而降低功耗,成为移动端GPU的首要课题。
图8. TBDR管线
TBDR(tile-based deferred rendering)技术应运而生,这一技术的核心是将需要渲染的图形拆成瓦片tile,tile部分单独渲染,不需要和其他tile有过多的信息交换,这样的好处是外部存储的访问量大大降低,存储带宽效率提升,功耗下降。但带来的问题是这一不完全按物理规则画图的方式导致了关联信息的丢失,特别在有透明物体的场景下往往会出现“错误”,视觉呈现出错乱的感觉(如左图所示,正确的渲染效果如右图)。
图9. 渲染效果对比

以ARM MaliG71 Bifrost架构为例,其专门设计了tiler单元来降低功耗。
图10. MaliG71 Bifrost架构
从电路设计的角度,CMOS工艺中芯片功耗的75%来自状态翻转的动态功耗,且大部分来自IO,存储,客户定制单元和时钟。为了对移动端进行优化,移动GPU的设计理念必须*性的专用,将TBDR的图形渲染管线尽量的固化,专用化的设计在某些场景下可以将功耗降低为通用处理电路的百分之一甚至千分之一。应用固化在带来*低功耗的同时也几乎完全丧失了运算单元的灵活性。所以你可能从未听说过哪个移动GPU IP厂家推出可以挖矿的移动GPU IP。由此可知,核显IP是无法做出高性能独显的。
05、GPGPU/AI加速芯片和GPU不可同日而语
既然移动端GPU IP做不了通用计算芯片,那先研发出GPGPU,是不是离高性能独显GPU就不远了呢?事实上,如前文所述,GPGPU在计算上是有一定通用性的,但在图形上的处理能力为零。比较二者的技术门槛,差距不言自明。

综上,读者可能很快理解了为何国内很多初创期的“GPU”或GPGPU公司往往有两条产品线,一条是“GPU”(采用移动GPU IP),另一条是GPGPU(类似一个AI加速芯片)。因为采用了移动端GPU IP可以快速出产品,但无计算功能;而GPGPU更类似一个AI加速芯片,但图形处理能力为零。这两条产品线的研发团队也往往是各自为政,南辕北辙,统一的软件栈根本无从谈起。采用这样的研发思路想挑战Nvidia CUDA软硬件生态的强悍壁垒几乎是不可能的了。
06、路在何方——深流微全自研高性能GPU
深流微从成立的*天开始,坚持从“零”开始,独立自主,基于团队合计上百人年的研发经验和技术积累,对操作系统,图形及通用计算横纵扩展,开发了GPU专用compiler/debugger/emulator等关键工具,形成了完整且可迭代升级的基础开发生态系统。2021年,深流微成功获得了兴旺投资*领投的preA轮融资。
从对图形学理论的基础解析开始,深流微团队对各种应用场景的算法和算力要求进行了全面分析,定义出相应的GPU架构。在此基础上,深流微研发出自主的多功能渲染运算单元,并将上千个单元集于深流微*的XST超级流架构中。这种超级流架构采用动态无阻任务调度发送,合理分配运算资源,从而实现高效率的渲染和计算(Unified Shading & Computation)。从*行代码开始,公司已经成功完成了XST架构基础渲染管线的设计和FPGA验证,联合研发优化的全栈软件也如期达成。
类似Nvidia的Pascal架构,XST架构GPU内核可以通过不同的配置形成XST-G(Graphic),XST-C(Computing),和XST-E(Edge)三条产品线,分别对标Nvidia的GeForce GTX 1080,Tesla P100和Jeston TX2,形成图形处理,AI超算和边缘计算三条硬件产品线和统一的上层软件栈。之后团队将更进一步,迭代开发出与目前Nvidia的主力产品GeForce RTX 3080对标的高性能GPU芯片。
07、结语
“淋我淋过的雨,吹你吹过的风”,原始创新没有捷径,弯道超车和换道超车都是童话,只有直道加速是*的出路。中华民族的伟大复兴,科技强国的中国梦需要每一位科技从业者踏踏实实,自主创新,拿出真正具有核心技术的优秀产品,实力报国。静水流深,静待佳音。
【本文由投资界合作伙伴微信公众号:兴旺投资授权发布,本平台仅提供信息存储服务。】如有任何疑问,请联系(editor@zero2ipo.com.cn)投资界处理。





