
Groq是近期AI芯片界的一个明星。原因是其号称比英伟达的GPU更快。3月2日,据报道,Groq收购了一家人工智能解决方案公司Definitive Intelligence。这是 Groq 在 2022 年收购高性能计算和人工智能基础设施解决方案公司 Maxeler Technologies 后的第二次收购。Groq来势很凶。
自从ChatGPT爆火以来,英伟达凭借GPU在市场上独孤求败,虽然也出现了不少挑战者,但都没有像Groq这般引人注意。
成立于2016 年的Groq,其创始人是被称为“TPU之父”的前谷歌员工乔纳森·罗斯,团队中成员不乏有谷歌、亚马逊、苹果的前员工。这帮人通过简单的设计开发了一款LPU(语言处理单元)推理引擎。就是这个LPU芯片让Groq在AI市场上异军突起,引得大家刷屏。据悉,LPU可在当今大火的LLM(大语言模型)中展现出非常快速的推理速度,比GPU有显著提升。不要小看AI推理的市场,2023年第四季度,英伟达有4成收入来源于此。因此,众多英伟达的挑战者是从推理切入的。
那么,它是如何做到速度快的?为何能够叫板英伟达?在芯片架构和技术路径上有哪些可圈可点之处?。。。。对于这款引发广泛关注的芯片,很多人也希望能够了解其背后究竟有哪些玄妙?近日,半导体行业观察有幸采访到了北京大学集成电路学院,长聘副教授孙广宇,孙教授为我们提供了一些专业见解,至于网上对Groq价格的各种推测,其比性能等估算更复杂,本文在此将不作过多探讨,而是侧重于技术层面的解析,以期为读者带来一些启发。
最快的推理速度?
我们处于一个快节奏的世界中,人们习惯于快速获取信息和满足需求。研究表明,当网站页面延迟300 - 500毫秒(ms)时,用户粘性会下降20%左右。这在AI的时代下更为明显。速度是大多数人工智能应用程序的首要任务。类似ChatGPT这样的大语言模型(LLM)和其他生成式人工智能应用具有改变市场和解决重大挑战的潜力,但前提是它们足够快,还要有质量,也就是结果要准确。
要想快,就要计算和处理数据的能力强大。据Groq的白皮书【Inference Speed Is the Key To Unleashing AI’s Potential】【1】指出,在衡量人工智能工作负载的速度时,需要考虑两个指标:
输出Tokens吞吐量(tokens/s):即每秒返回的平均输出令牌数,这一指标对于需要高吞吐量的应用(如摘要和翻译)尤为重要,且便于跨不同模型和提供商进行比较。
*Token返回时间(TTFT):LLM返回*令牌所需的时间,对于需要低延迟的流式应用(如聊天机器人)尤其重要。
2)影响模型质量的两个*因素是模型大小(参数数量)和序列长度(输入查询的*大小)。模型大小可以被认为是一个搜索空间:空间越大,效果越好。例如,70B参数模型通常会比7B参数模型产生更好的答案。序列长度类似于上下文。更大的序列长度意味着更多的信息——更多的上下文——可以输入到模型中,从而导致更相关和相关的响应。
在Anyscale的LLMPerf排行榜上(这是一个针对大型语言模型(LLM)推理提供商的性能、可靠性和效率评估的基准测试),Groq LPU在其首次公开基准测试中就取得了巨大成功。使用Groq LPU推理引擎运行的Meta AI的Llama2 70B,在输出tokens吞吐量上,实现了平均185 tokens/s的结果,比其他基于云的推理提供商快了3到18倍。对于*Token返回时间(TTFT),Groq达到了0.22秒。所有Llama 2的计算都在FP16上完成。
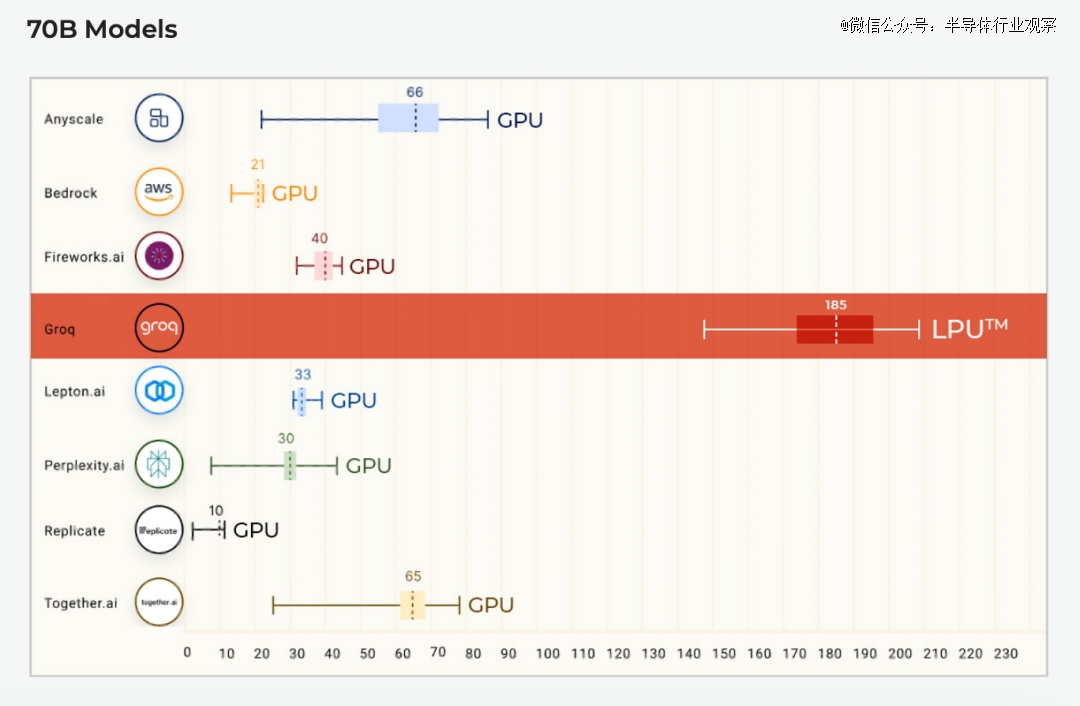
输出tokens吞吐量(tokens/s)
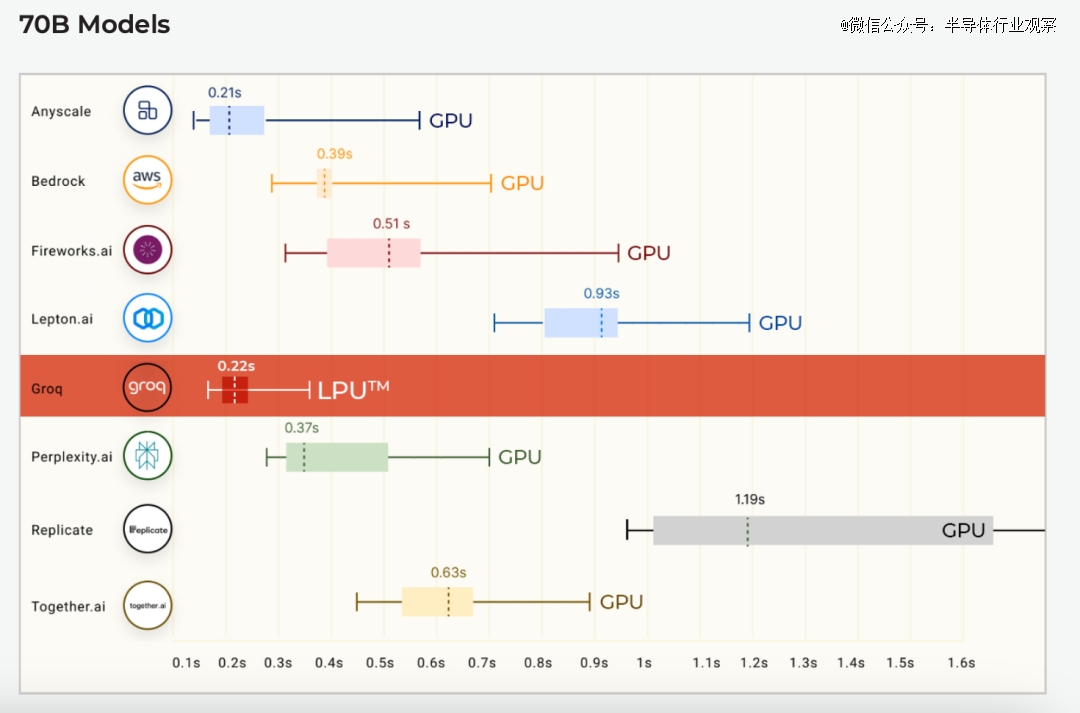
*tokens的返回时间
这是如何实现的呢?
挖掘深度学习应用处理过程中的“确定性”
如今行业不少人的共识认为,英伟达的成功不仅仅归功于其GPU硬件,还在于其CUDA软件生态系统。CUDA也被业界称为是其“护城河”。那么,其他AI芯片玩家该如何与英伟达竞争?
孙教授表示,诚然,CUDA为GPU开发者提供了一个高效的编程框架,方便编程人员快速实现各种算子。不过,仅靠编程框架并不能实现高性能的算子处理。因此,英伟达有大量的软件开发团队和算子优化团队,通过仔细优化底层代码并提供相应的计算库,提升深度学习等应用计算效率。由于CUDA有较好的生态,这部分开源社区也有相当大的贡献。
然而,CUDA框架和GPU硬件架构的紧密耦合同时也带来了挑战,比如在GPU之间的数据交互通常需要通过全局内存(Global Memory),这可能导致大量的内存访问,从而影响性能。如果需要减少这类访存,需要利用Kernel的Fusion等技术。实际上,英伟达在H100里增加SM-SM的片上传输通路来实现SM间数据的复用、减少访存数量,但是这通常需要程序员手工完成,同样增加了性能优化的难度。另外,GPU的整个软件栈最早并不是专为深度学习设计的,它在提供通用性的同时,也引入了不小的开销,这在学术界也有不少相关的研究。
因此,这就给AI芯片的新挑战者如Groq,这提供了机会。例如Groq就是挖掘深度学习应用处理过程中的“确定性”来减少硬件开销、处理延时等。这也是Groq芯片的特色之处。
孙教授告诉笔者,实现这么一款芯片的挑战是多方面的。其中关键之一是如何实现软硬件方面协同设计与优化,极大的挖掘“确定性”实现系统层面的Strong Scaling 。为了达到这个目标,Groq设计了基于“确定性调度”的数据流架构,硬件上为了消除“不确定性” 在计算、访存和互联架构上都进行了定制,并且把一些硬件上不好处理的问题通过特定的接口暴露给软件解决。软件上需要利用硬件的特性,结合上层应用做优化,还需要考虑易用性、兼容性和可扩展性等,这些需求都对配套工具链和系统层面提出很多新的挑战。如果完全依赖人工调优的工作是很大的,需要在编译器等工具层面实现更多的创新,这也是新兴的AI芯片公司(包括Tenstorrent、Graphcore、Cerebras等)面临的共同问题。
HBM是*解?纯SRAM来挑战
LPU 推理引擎主要攻克 LLM的两个瓶颈——计算量和内存带宽。Groq LPU能够与英伟达叫板,其纯SRAM的方案起到了很大的作用。

简化的LPU架构
不同于英伟达GPU所使用的HBM方案,Groq舍弃了传统的复杂储存器层级,将数据全部放置在片上SRAM中,利用SRAM的高带宽(单芯片80TB/s),可以显著提升LLM推理中带宽受限的(Memory Bound)部分,比如Decode Stage计算和KV cache的访存。SRAM本身是计算芯片必须的存储单元,GPU 和CPU等利用SRAM来搭建片上的高速缓存,在计算过程中尽可能减少较慢的DRAM访问。但由于单个芯片的SRAM容量有限,所以涉及到数百个芯片协同处理,这也涉及芯片间的互连设计,以及系统层面的算法部署等。
Groq提到,由于没有外部内存带宽瓶颈,LPU推理引擎提供了比图形处理器更好的数量级性能。
这种纯SRAM的架构在最近几年一直被学术界和工业界所讨论,比如华盛顿大学在文章【Chiplet Cloud: Building AI Supercomputers for Serving Large Generative Language Models】【2】中提到,与DDR4和HBM2e相比,SRAM在带宽和读取能耗上具有数量级的优势,从而获得更好的TCO/Token设计,如下图所示。市面上,包括Groq以及其他公司如Tenstorrent、Graphcore、Cerebras和国内的平头哥半导体(含光800)、后摩智能(H30)等,都在尝试通过增加片上SRAM的容量和片上互连的能力来提升数据交互的效率,从而在AI处理芯片领域寻求与英伟达不同的竞争优势。
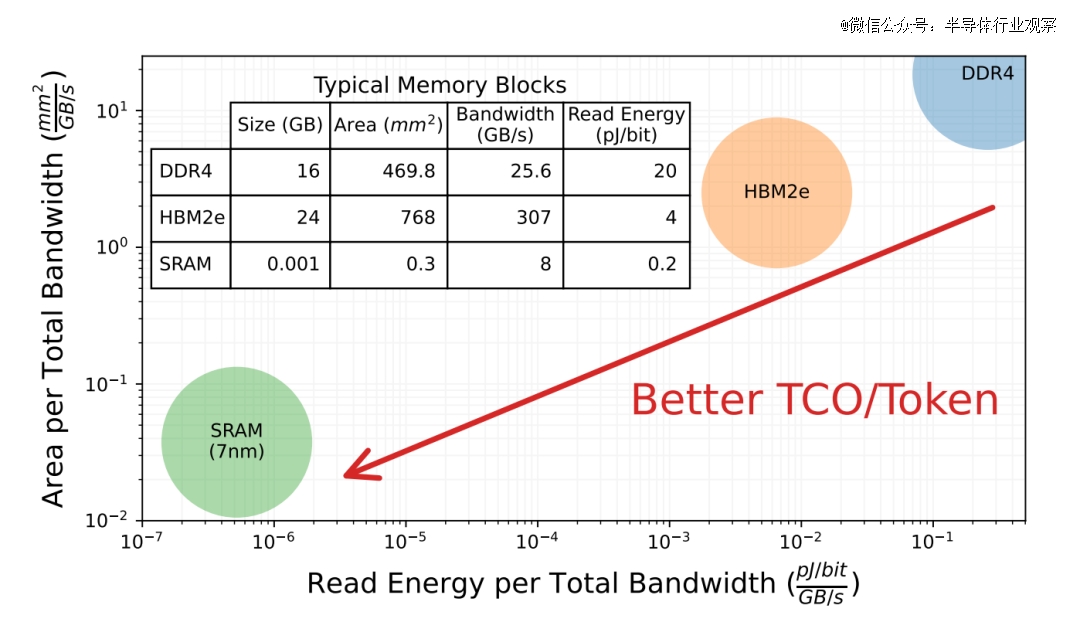
与DDR4和HBM2e相比,SRAM在带宽和读取能耗上具有数量级的优势,从而获得更好的TCO/Token设计(来源:【2】)
纯SRAM架构的优势在哪里?孙教授指出主要涵盖两方面:*个方面是SRAM本身有着高带宽和低延迟优势,可以显著提升系统在处理访存受限算子的能力。另一方面,由于SRAM的读写相比DRAM具有确定性,纯SRAM的架构给软件提供了确定性调度的基础。编译器可以细粒度地排布计算和访存操作,*化系统的性能。对于GPU来说,由于HBM访问延迟会有波动,Cache层级的存在也提升了访存延迟的不确定性,增加了编译器做细粒度优化的难度。
众所周知,英伟达GPU所使用的HBM方案面临着成本高、散热、产能不足的难题。那么,这种纯SRAM架构又有哪些挑战呢?
孙教授分析到:“纯SRAM架构的挑战也很明显,主要来自于容量的限制。Groq等芯片基本上都是在CNN时代进行的立项和设计,对于这个阶段的模型,单芯片百兆SRAM来作为存储是够用的。但是在大模型时代,由于模型大小通常可以达到上百GB,而且KV-Cache(一种关键数据结构)的存储也非常占用内存,单芯片SRAM的容量在大模型场景下显得捉襟见肘。”
他以Groq的方案为例来说,为了满足70B模型的推理需求,它集成了576个独立的芯片,而集成如此多的芯片,对芯片间、节点间互联的带宽和延迟要求也非常的高。576芯片的集群只有100GB的SRAM容量。模型需要通过细粒度的流水线并行(PP)和张量并行(TP)的方式进行切分,来保证每个芯片分到的模型分块在200MB以内。细粒度切分的代价是芯片间通信的数据量和开销显著上升,虽然Groq在互联方面也进行了定制优化来降低延迟,但是通过简单估算可以发现,目前芯片间数据传输同样可能成为性能瓶颈。”
另一方面,由于容量的限制,其留给推理时的激活值的存储空间十分受限。特别是目前LLM推理需要保存KV-Cache,这是随着输入输出长度线性增长的数据。通常对于70B模型,即使用了特殊技术进行KV-Cache压缩(GQA),32K的上下文长度需要为每个请求保留10GB左右的KV-Cache,这意味着在32K场景下同时处理的请求数*仅为3。对于Groq来说,由于依赖流水线并行(TP),需要至少流水线级数这么多的请求来保证系统有较高利用率,较低的并发数会显著降低系统的资源利用率。所以,如果未来长上下文(Long-Context)的应用场景,在100K甚至更长的上下文下,纯SRAM架构能支持的并发数会非常受限。换一个角度看,对于边缘场景,如果采用更激进的MQA、更低的量化比特,可能会使SRAM架构更为适用。
如果Groq 这类芯片确实能够找到合适的应用场景,应该会让算法从业者更积极挖掘模型压缩、KV-Cache压缩等算法,来缓解纯SRAM架构的容量瓶颈。一些对推理延迟有强需求的算法和应用,如AutoGPT, 各种Agent算法等,整个算法流程需要链式处理推理请求的,会更有可能做到实时处理,满足人与真实世界交互的需求。
因此,在孙教授看来,采用纯SRAM还是HBM与未来模型发展和应用的场景非常相关。对于数据中心这类采用较大的batch数、较长的sequence length、追求吞吐的场景,HBM这类大容量存储应该更加合适。对于机器人、自动驾驶等边缘侧,batch通常为1,sequence length有限,追求延时的场景,尤其考虑到模型有机会继续压缩,纯SRAM的场景应该有更大的机会。另外,还可以同时期待一些新的存储介质的发展,能否将片上存储容量从百MB突破到GB的规模。
应对“存储墙”挑战:芯片架构创新势在必行
实际上,除了前述的纯SRAM解决方案外,为了应对当前冯诺依曼架构面临的“存储墙”问题,业界正在探索多种新型架构,包括存算一体和近存计算等。这些探索涵盖了基于传统的SRAM、DRAM以及新兴的非易失性存储技术,如RRAM、STTRAM等,都有广泛的研究正在进行中。在处理大型模型的场景中,也有相关的创新尝试,例如三星、海力士等企业正积极研发的DRAM近存计算架构,可以很好的在带宽和容量之间提供权衡,对于访存密集KV cache和小batch的Decode处理部分也提供了不错的机会。(对这部分有兴趣,可以参考“Unleashing the Potential of PIM: Accelerating Large Batched Inference of Transformer-Based Generative Models”【3】这篇文章关于KV cache的处理,孙教授团队比较关注的研究方向。)
另外,从更广义的角度分析,无论采用哪种存储介质、无论采用存算还是近存架构,其本质目的和Groq出发点是类似的,都是挖掘存储架构的内部高带宽来缓解访存瓶颈。如果同时考虑大容量的需求,都需要将存储分块,然后在存储阵列附近(近存)或阵列内(存内)配备一定的算力单元。当这种分块的数量达到一定数量,甚至会突破单个芯片的边界,就需要考虑芯片间的互连等问题。对于这类计算和存储从集中式走向分布式的架构,孙教授团队在研究时也习惯称为空间型计算(Spatial Computing)架构。简言之,每个计算或者存储单元的位置都对它承担的任务有影响。一方面,在芯片层面,这种分布式计算架构和GPU提供抽象是不同的;另一方面,当规模扩大到多芯片/多卡这个级别,面临的问题又是类似的。
总之,大模型确实给传统的芯片架构带来了极大的挑战,迫使芯片从业者发挥主观能动性,通过“另辟蹊径”的方式来寻求突破。值得关注的是,国内也已经有一批架构创新型的芯片企业,陆续推出了存算一体或近存计算的产品,例如、知存科技、后摩智能、灵汐科技等。
考虑到芯片的研发周期通常长达数年,孙教授认为在尝试新技术的时候需要对未来的应用(如LLM技术)的发展趋势有一个合理的预判。分析好应用的发展趋势,通过软硬件的设计预留一定的灵活性和通用性,更能够保证技术长期适用性。
参考
【1】《Inference Speed Is the Key To Unleashing AI’s Potential》,Groq
附孙教授所提及的论文地址:
【2】Chiplet Cloud: Building AI Supercomputers for Serving Large Generative Language Models(https://arxiv.org/pdf/2307.02666.pdf)
【3】Unleashing the Potential of PIM: Accelerating Large Batched Inference of Transformer-Based Generative Models(https://ieeexplore.ieee.org/abstract/document/10218731)
【本文由投资界合作伙伴微信公众号:半导体行业观察授权发布,本平台仅提供信息存储服务。】如有任何疑问,请联系(editor@zero2ipo.com.cn)投资界处理。





