
年度盘点第二弹:关于DeepSeek。
1、DeepSeek 不是“中国式创新” 的产物
中国杭州的人工智能创业公司 DeepSeek 是近一段时间硅谷的 AI 研究者和开发者的心魔。它在 2024年12月发布的大语言模型 DeepSeek - V3 被认为实现了诸多的不可能:550万美元和2000块英伟达 H800 GPU(针对中国市场的低配版 GPU)训练出的开源模型,多项评测成绩超越了 Qwen2.5-72B 和 Llama-3.1-405B 等*开源模型,亦与 GPT-4o 和 Claude 3.5-Sonnet 这样世界*的闭源模型不相上下——而训练后者的成本保守估计也要数亿美元和几十万块最强劲的英伟达 H100。
可以想象它在人工智能界引发的震撼 —— 尤其是在 AI 领域的研究人员、创业者、资金、算力和资源最扎堆的硅谷。不少硅谷 AI 领域的重要人士都不吝惜对 DeepSeek 的称赞,比如 OpenAI 联合创始人 Andrej Kaparthy 和 Scale.ai 的创始人 Alexandr Wang。尽管 OpenAI CEO Sam Altman 发了一条疑似影射 DeepSeek 抄袭借鉴其它先进成果的推文(很快就被人回怼“是指把Google 发明的 Transformer 架构拿过来用么?),但 DeepSeek 收获的赞誉确实是广泛而真诚的,尤其是在开源社区,开发者用脚投票。

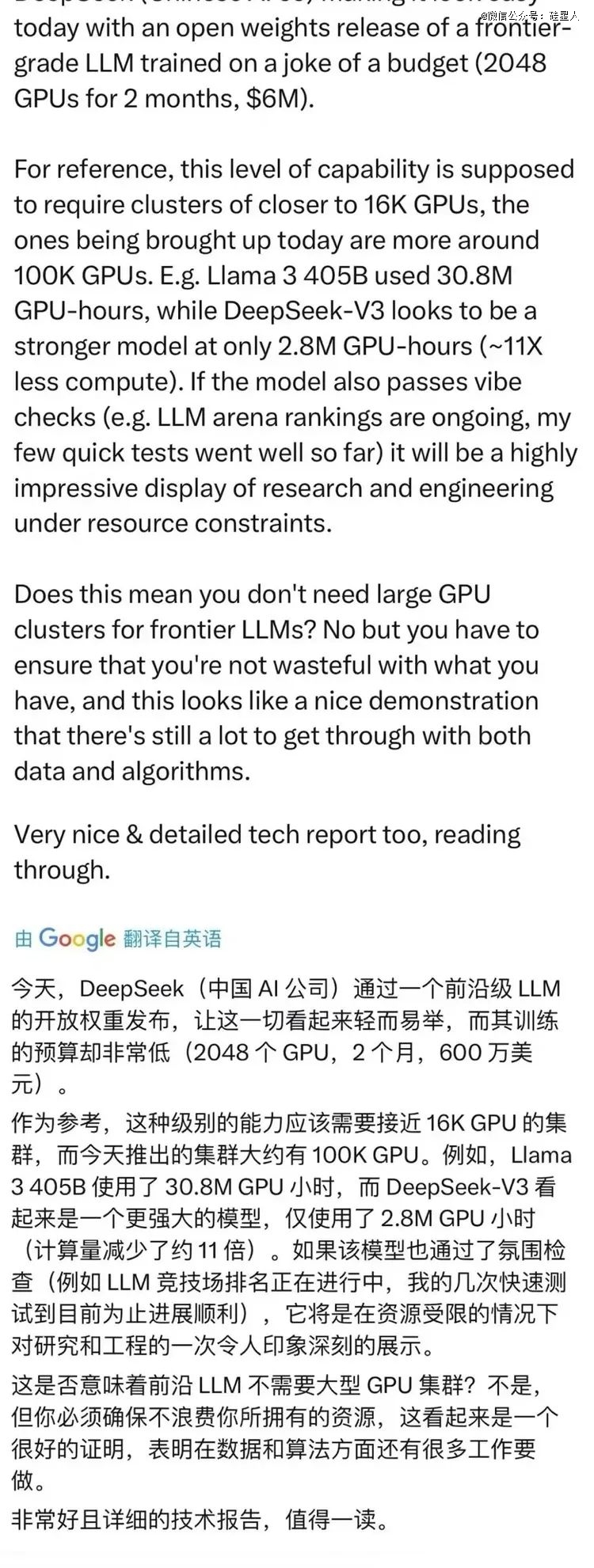
Andrej Kaparthy赞扬Deepseek的技术报告值得一读
很多中国人将 DeepSeek - V3 视作“国货之光”, 也是中国式创新的一个范式。确实,中国聪明的研究人员和工程师非常擅长“多快好省” 干大事,在资源紧缺有限的情况下(很多时候我们也不想),通过技术方法的创新和精进,实现超预期的成果。DeepSeek - V3 对高性能算力的依赖如此之小,将训练和推理当作一个系统,给出了诸多新的技术思路,注重用工程思维高效解决算法和技术问题,集中力量办大事,这确实是中国公司、中国团队和中国研究人员更擅长的。Alexandr Wang 从DeepSeek 总结的经验是:美国人在休息,中国人在奋斗,以更低的成本、更快的速度和更强大的战斗力追赶。
很有意思,美国科技界对中国比较友善的人士——其中包括马斯克——经常总结中国在一些领域的成功经验是聪明、勤奋和有方法,这当然没什么问题。但它解释不了,至少在 AI 领域解释不了的一个问题是:中国的其它大模型公司和 AI 人才同样聪明、勤奋和擅长方法创新,他们的很多技术方法创新也卓有成就(DeepSeek 的分布式推理,我*次注意到类似的创新是月之暗面的 Mooncake),但为什么没有引发如此轰动的世界级效应?当然今后他们可能也会,但至少,为什么这次是DeepSeek?
将 DeepSeek 比喻成 “AI 界的拼多多” 是偏颇的,认为 DeepSeek 的秘方就是多快好省也是不全面的。中国的大多数 AI 公司都缺卡,也都因为缺卡而拼命搞架构创新,这点没什么不同。要知道,DeepSeek 在硅谷受到关注和追逐不是这两周刚发生的事。早在2024年5月 DeepSeek - V2发布的时候,它就以多头潜在注意力机制(MLA)架构的创新,在硅谷引发了一场小范围的轰动。V2 的论文就引发了 AI 研究界的广泛分享和讨论。当时,一个非常有意思的现象是:X 和 Reddit 上 AI 从业者在讨论 DeepSeek - V2,同时,DeepSeek 在国内舆论场被描摹成了“大模型价格战的发起者”,有点平行时空的感觉。
这也许能说明:DeepSeek 跟硅谷更有对话和交流的密码,它的秘方应该是硅谷味儿的。
2、DeepSeek 与 2022年之前的 OpenAI 和 DeepMind
如果非要给 DeepSeek 在全球的人工智能玩家里找一个对标的话,请允许我加上一个前置条件:DeepSeek 有点像 OpenAI 和 DeepMind ——2022年之前的 OpenAI 和 DeepMind。
2022年之前的 OpenAI 和 DeepMind 是什么样子?非营利性学术研究机构。尽管已经被微软投资并转型为了营利性公司,但当时 OpenAI 的整体工作方式——至少是首席科学家 Ilya Sustkever 和联合创始人 Andrej Kaparthy 为代表的那群人——仍是非营利机构性质的,公司没有对外的正式产品,2020年公布的 GPT-3 是一个学术研究成果,而且还开源了。DeepMind 尽管名义上是一家创业公司,但无论是它独立在伦敦存在的时期,还是被 Google 收购但尚未与Google Brain 整合之前,都更像是一家研究机构的存在,无论 AlphaGo 还是 AlphaFold,都是研究项目,而不是产品。
DeepSeek 有自己的“产品”么?不能说没有,毕竟普通用户也可以直接跟它的模型聊天,它还顺带手向开发者卖一卖低价的 API。可是它连个移动 APP 都没有,看上去也没对产品做什么运营,不投放流量广告,也不搞社交媒体营销,也不给用户准备各种贴心的 prompt 模板。有个网站,普通人也可以用,就够了。光就这一点看 DeepSeek 就很不中国 AI 公司。在企业和开发者一侧,除了基于架构创新的成本下降让它狠狠砸了一锤子 API 的价格,也看不到它搞什么“加速计划”、“开发者大赛”、“产业生态基金”等等很多企业都搞的项目。这只能说明:现在它是真心不打算做生意。
另一方面,DeepSeek 的研究人员密度是显而易见的。,为我们了解这家公司的研究人员构成和特点提供了非常有价值的探索:清华、北大、北航等中国*高校的应届博士毕业生、顶刊论文发表者、信息竞赛获奖者是 DeepSeek 研究团队的主力,甚至包括硕博在读生。团队构成极其年轻。DeepSeek 创始人梁文锋接受 36 氪旗下“暗涌”采访时透露过招人标准:看能力,不看经验,核心技术岗位以应届和毕业一两年为主。这是典型的为研究人员,而非为产品、市场和工程等岗位招人定制的标准。也像极了 OpenAI 和DeepMind 早期的人才结构:用最年轻、最聪明、最不受拘束的头脑,创造一些前人没创造过的东西。
它营造了一种氛围:这些最聪明的年轻人进入到了一家外表看起来是公司的机构,然后在这里继续延续他们的学术生涯,可以调动比在纯粹的学术机构(比如高校实验室)多得多的计算资源和研究数据。科技公司的研究机构是科学家的“国中之国”,取代高等院校成为学术成果主要贡献者的趋势益发明显。它越不受到公司商业目标的干扰,产生颠覆性学术成果的机会越大。Google 的研究人员提出生成式人工智能的基础—— Transformer 架构是在 Google 的 AI 商业化目标尚不清晰的 2017年,这两年反而鲜有成果。OpenAI 的 GPT-3 和 GPT-3.5 两个关键时刻的诞生都是在聚光灯之外,而当它越来越像一家公司的时候,一切都乱了。
这也是 DeepSeek 区别于大多数中国的 AI 创业公司,反而更像是一家研究机构的地方。这轮 AI 创业的创始人基本都是科学家和研究人员,但他们拿了 VC 和 PE 一轮又一轮的钱,就不能随心所欲地搞研究和发 paper,而必须聚焦产品化和商业化(这很可能不是他们最擅长的事)。科技巨头养得起研究机构和科学家,但一旦要求研究成果迅速应用于产品和商业,团队也会变得更复杂,而不再有纯研究人员的简单和清澈。美国的一些科技巨头有不受商业目标干扰的研究机构,但时间过久,又难免沾染了学术界论资排辈的门阀气息。都是由最聪明的年轻人组成的商业公司的研究机构,只在关键的几个时间点出现过——几年前的 OpenAI 和 DeepMind,以及现在的DeepSeek。
一个证据就是:DeepSeek *的“产品”除了模型,还有它的论文。无论是 V-2 还是 V-3 的发布,DeepSeek 的两篇对应论文都得到了来自全球研究者的仔细阅读、分享、引用和大力推荐。相比之下,GPT-4 发布之后 OpenAI 公布的论文几乎不能叫做论文。这年头做模型的都在抢在各种 benchmark 上拿名次,注重论文质量的已经不多了。而一篇详尽、规范和实验细节丰富的论文,仍然能获得业界额外的尊重。
当然这件事的一个重要前提是:DeepSeek 有钱,有不输于巨头、远多于创业公司的弹药。但并不是所有巨头都愿意有一个自己的 DeepMind。
3、开源永远是正确的
2023年初,科技媒体 The Information 进行过一轮中国可能出现哪些人工智能明星创业公司的盘点。已经做出了一些成绩的智谱和 Minimax 在列,刚刚创建的百川智能、零一万物和光年之外也被提及,该文章还特别提及了当时正准备再度创业尚名不见经传的杨植麟。这里面没有 Deepseek。
至少一年半之前,没人真的把 DeepSeek 当成 AI 的圈内人。尽管当时业界开始流传 DeepSeek 的母公司——从事私募量化技术的幻方握有数量丰沛的英伟达高性能显卡,仍没太多人相信它自己下场做大模型会有水花。现在,人人都在谈论 DeepSeek,而且走的又是“墙外开花墙内香” 的老路。
可以认为,从*天开始,DeepSeek 与国内的诸多大模型新秀,选择的就不是同一个战场。它不拿融资(至少一开始不用拿),不用争抢大模型四小龙六小虎的座次,不比国内的舆论声势(*接受暗涌的采访,目的大概是招聘那些最热血的聪明的科学家),不搞产品投放投流。它选择的是与研究机构的本质最匹配的路径——走全球开源社区,分享最直接的模型、研究方法和成果,吸引反馈,再迭代优化,自我进益。
开源社区迄今仍是 AI 学术研究、分享和讨论最热烈、充分、自由和无国界的地方,也是 AI 领域最不“内卷”的地方。DeepSeek 从*天就开源,应该是深思熟虑的。开源就要真开源,开得彻底,从模型权重、到数据集,再到预训练方法,悉数公开,而高质量的论文也是开源的一部分。年轻聪明的研究人员在开源社区的亮相、分享和活跃具有高能见度。看见他们的人,并不乏一些全球 AI 领域最重要的推动者。
聪明的年轻 AI 研究人员 + 研究机构的氛围(配上大厂的package)+ 开源社区的分享和交流,提高了 DeepSeek 在全球 AI 领域影响力和声望。对一家以产生 AI 研究成果而非发布商业化产品为主要目标的机构而言,Hugging Face 和 Reddit 就是*的发布会会场,数据集和代码库就是*的 demo,论文就是*的新闻稿。DeepSeek 基本就是这么做的,而且做得很讲究。所以即便 DeepSeek 的研究人员和 CEO 鲜少接受媒体采访,也几乎从不在论坛和活动上分享技术经验和洞察,但你不能说它没做营销。反之,以证明中国 AI 原创研究可以引领全球趋势、招聘最聪明的研究人员的目的来说,DeepSeek 的“营销”是极其精准和有效的。
这里值得提一句,过去的一年中国的开源大模型主要玩家确实在全球 AI 研究和产品方面赢得了不少尊敬。一个越来越普遍的看法是:比起美国和欧洲的一些开源模型,中国的开源大模型在开源程度上更为彻底,更容易被研究人员和开发者直接拿过来上手研究或优化自己的模型。DeepSeek 就是一个典型代表,除了 DeepSeek,阿里巴巴的通义(Qwen)也被 AI 研究领域普遍认为开源态度较为真诚,面壁智能的小模型 Mini-CPM-Llama3-V 2.5 因为被斯坦福本科生团队直接套壳也意外走红了一把。
所以很有意思:国际 AI 界特别是硅谷认为中国大模型的代表玩家是 DeepSeek 和阿里巴巴,而我们自己觉得是豆包、可灵和所谓的 AI 六小龙。客观地说,就国际 AI 界特别是硅谷能公正、积极地看待中国 AI 创新能力和对全球社区的贡献方面,DeepSeek 和阿里巴巴们做得更多。开源在任何时候都是一件正确的事。
4、V-3 是 DeepSeek 的 GPT-3 时刻
V-3 模型引发了破圈的国际反应,CNBC 的报道已经把 V-3 及其背后的 DeepSeek 视作中国 AI 迎头赶上美国的标志。如果仔细观察的话,并不难发现:DeepSeek 从隐秘低调到备受关注,以及它从 Coder 到 V-3 模型的三次迭代,与 OpenAI 从 GPT-1 到 GPT-3 的升级节奏和它引发的反响,是非常接近的。
我们先看看OpenAI——
2018年 OpenAI 放出了 GPT-1 模型,是它*个基于 Transformer 架构的预训练模型,证明了语言模型是一个有效的预训练目标,但质量和多样性有限,引发了一定的学界关注,但整体反应平常。
2019年早些时候,OpenAI 推出 GPT-2,生成文本的质量和多样性大幅跃迁,基本验证了语言模型这条路的有效性,也引发了 AI 领域广泛的讨论和关注。
2020年6月,OpenAI 发布 GPT-3,以1750亿参数成为当时世界上*的语言模型,除了生成文本内容,还能进行翻译、问答和持续对话和思考,成为了生成式人工智能发展的里程碑。即便如此,GPT-3 仍然是一个实验室项目。
让我们再看 DeepSeek——
2023年11月,DeepSeek 先后发布了两款开源模型 DeepSeek Coder 和 DeepSeek LLM, 只有少数人关注到了,而它们也在计算的效率和可扩展性上遇到了挑战。
2024年5月,DeepSeek 发布了 V-2,以混合专家模型(MoE)和多头潜在注意力机制(MLA)技术的结合,大幅降低了模型训练特别是推理的成本,且性能可以在很多维度与世界*模型相比较,它开始引发 AI 学术界和开发者的广泛讨论和推荐,这是 DeepSeek 走进更多人视野的开始。
2024年12月,DeepSeek 发布了 V-3,以 OpenAI、Anthropic 和 Google 百分之一的成本,实现了模型性能超越同类开源模型 Llama 3.1 和 Qwen 2.5,媲美闭源模型 GPT-4o 和 Claude 3.5 Sonnet 的成绩,引发轰动,成为世界大语言模型发展的里程碑。
可以说,V-3 就是 DeepSeek 的“GPT-3” 时刻,一个里程碑。
当然,DeepSeek 与 OpenAI 在实现里程碑式跃迁的进程中区别在于——
OpenAI 在这一进程中一直致力于实现计算资源规模与成本的无限扩张,而 DeepSeek 则一直致力用尽可能低成本的计算资源实现更高的效率。
OpenAI 花了两年时间达到 GPT-3 时刻,而 DeepSeek 用了一年摘得了 V-3 的圣杯。
OpenAI 在 GPT 路线上一直聚焦在预训练的进步,而DeepSeek 则是训练与推理并重——这也是全球模型技术发展趋势的要求。
如果 V-3 真的是 DeepSeek 的 GPT-3 时刻,那接下来将发生什么?是 DeepSeek 的 GPT-3.5——也就是 ChatGPT时刻,或是其它?没人知道,但有意思的事儿应该还在后头。DeepSeek 应该不会永远是一个“计算机系Pro”的存在,它也理应为全人类的人工智能事业做出更大的贡献。
无论如何,DeepSeek 已经是中国最全球化的 AI 公司之一,它赢得来自全球同行甚至对手的尊重的秘方,也是硅谷味儿的。
【本文由投资界合作伙伴微信公众号:硅星人授权发布,本平台仅提供信息存储服务。】如有任何疑问,请联系(editor@zero2ipo.com.cn)投资界处理。




