
程序员要被淘汰了,这可能不是危言耸听。
这个职业原本几乎是“金饭碗”一样的存在,技术门槛高、考验创造力,收入也高。但ChatGPT的问世,改变了这种固有态势。
最近这两天,GPT还升级到了第四代——GPT-4。
要知道,上一代ChatGPT已经具有*的语义理解能力。虽然这种能力仅限于文字处理,但也已经有公司在使用ChatGPT相关技术,替代掉一些初级程序员的工作了。
而GPT-4不光文字理解能力更高,还有*的图片理解能力,就连一些互联网梗图都能读懂。
这还不是GPT-4的全部实力。在GPT开发者OpenAI发布的演示视频中,GPT-4能根据一张非常潦草的demo图,在10秒之内生成一个网站页面。
10秒,是人类无论如何都不可能达到的速度,但AI可以。而且才100多天,它就跃进到了这个水平。
下一代GPT又会有多么强大的能力呢?这既让人期待和兴奋,又感觉有点后背发凉。
1.GPT-4,无所不能?
上一代GPT并不是*代,版本号其实是“3.5”。但因为其文字理解能力比较强,尤其对话交流表现非常“顺滑”,所以才被称为“ChatGPT”。
比起很多如同“人工智障”的AI助手,ChatGPT给出的回答更像人类,但也不是毫无漏洞。有用户问过ChatGPT:“林黛玉三打白骨精是怎么回事?”
ChatGPT还真给胡诌出了一段故事,看起来有点像从网友二创作品中提炼出来的剧情。
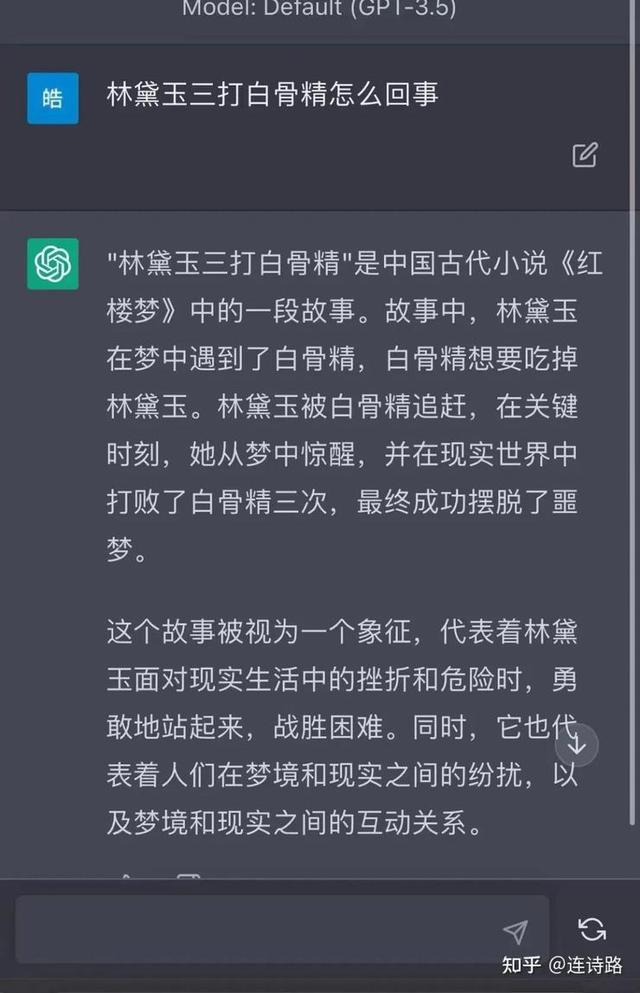
林黛玉三打白骨精是怎么回事?/知乎答主@连诗璐
但拿同样的问题去问GPT-4,它会提醒用户不要混合《红楼梦》和《西游记》的剧情。
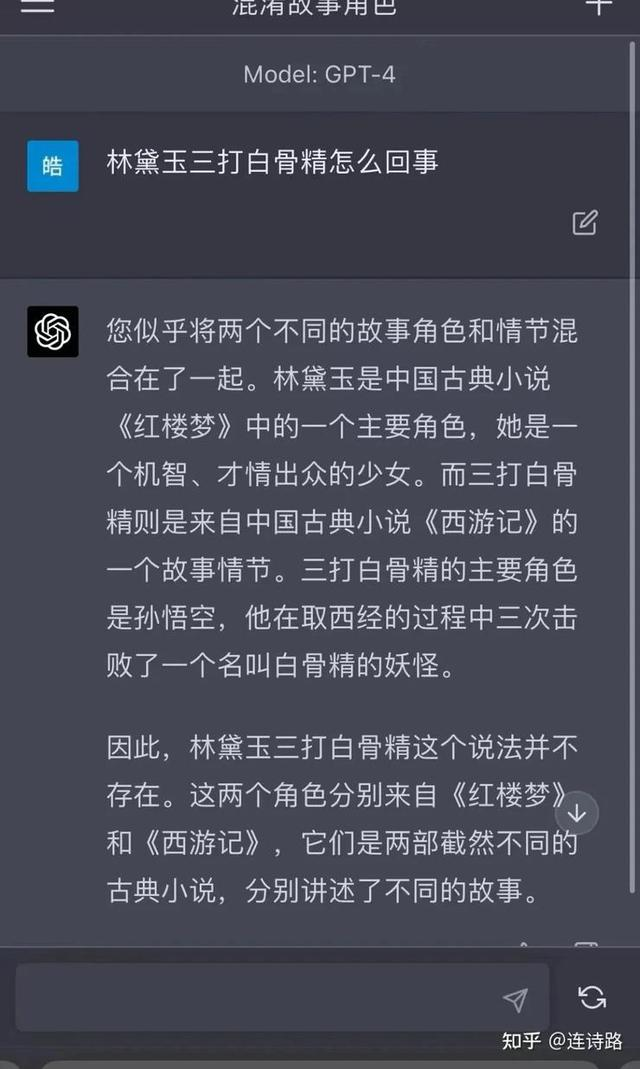
ChatGPT有点像喝醉了在说胡话,而GPT-4保持了清醒。/知乎答主@连诗璐
如果你以为GPT-4的文字理解能力只停留在“语句”的水平,那你就错了。GPT-4还可以理解“代码语言”。
在GPT-4的产品视频中,OpenAI总裁直接把一段1万字的代码发给GPT-4,让它修bug。结果GPT-4只用了几秒钟就找到了bug,并且分点给出了解决办法。换做是程序员去找,绝不可能有这个效率。
这次升级和更新之后,OpenAI还将GPT-4处理文字内容的上限拓展到了2.5万个字符,这是ChatGPT上限的8倍。这意味着,GPT-4可以处理更大的信息量。
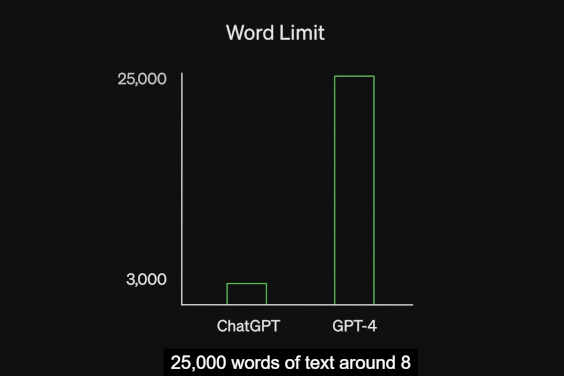
GPT-4更为突出的能力体现在图片理解方面。
在OpenAI发布的产品视频中,开发者给GPT-4看了一张“用VGA电脑接口给iPhone充电”的图片,并问GPT-4“笑点在哪里”,GPT-4在条分缕析之后得出了结论:
“这张图搞笑的地方在于,它将一个很大并且过时的VGA接口插在一个很小并且现代的智能手机充电口上,这很荒谬。”

GPT-4是懂幽默的。
更重要的是,它还能把对图片和文字的理解结合起来,同步进行。
比如,给GPT-4一些统计图表进行分析,GPT-4能高效地得出结论、发现问题,并迅速反馈给使用者。甚至直接把整篇论文截图上传给GPT-4,它都能在几秒之内概括出论文的核心内容来。
将来,大公司的财报、销售业务数据等内容,即便图表内容再复杂、内容维度再多、数据量再大,只要不超过2.5万个字符的限制,GPT-4都能分析得清楚。
如此看来,似乎GPT-4几乎可以秒杀相当一部分人类了,程序员、金融分析师、数据分析师、音乐创作人(GPT-4可以自己写歌)都要下岗。

至少,初级程序员会被淘汰。/微博截图
2.GPT性能跃进,留给人类的机会不多了?
问题来了,GPT-4连代码里的bug都能自己修,就不怕它自我进化,最后产生自主意识取代人类吗?
答案是:目前不会,因为GPT-4也不是*无缺的。
虽然它是多模态模型,目前已经可以处理文字和图片两种“模态”,这比ChatGPT只能处理文字的“单模态模型”进步了很多,但也仅限于此。
至少,目前它还分析不了声音和视频。后续的版本必然会覆盖这些“模态”,以增强AI的理解能力。
事实上,对声音的理解会更加复杂,比如一句话中的语气、停顿都包含着信息。另外还有非语言类声音,比如风声、撞击声,以及声音距离、方位的辨别,都是需要突破的点。而视频图像会更复杂,对这些技术的攻坚,势必要耗时更久。
当然,这也只是时间问题。
目前来看,它还有一个明显的问题就是,容易产生“AI幻觉”,生成错误答案,并出现逻辑错误。
所谓“AI幻觉”,是指模型过于自信,生成的内容与提供的源内容无关或不忠实,有时会出现听起来合理,但不正确或荒谬的答案,比如上文中提及的“林黛玉三打白骨精”问答。
中国信通院云计算与大数据研究所所长何宝宏曾在接受采访时指出,“ChatGPT的幻觉来自两个方面,一是训练数据本身,二是训练方法。AI是通过海量数据训练出来的,因此这一缺点也与大数据的问题一样:数据很精确但错得离谱”。
如果过于依赖AI,那么由这种幻觉导致的不准确性,显然会影响一些业务的正常进行。这就意味着,人工必须对其反馈的分析进行复核,这是AI取代不了的职责和必要性。
好在GPT迭代至今,其能力都仅限于被动响应。也就是说,不论是ChatGPT还是GPT-4,它们的信息读取能力都只是对人类提问的反馈,而不会主动去评判或者分析。
这一点“被动”的属性很关键,一方面能让AI处于从属地位,只会被动解决人类提出的问题。这一点,应当成为AI行业不可逾越的红线,否则就会面临很多麻烦,比如AI的自我演进,AI的权益和福利问题,AI越过防火墙进行监听,甚至衍生出黑客行为……
另一方面,这也对人类提出了更高的要求,比如提问能力。
很显然,GPT-4是根据指令进行分析的,那就是说,只有在指令或提问明确、清晰的情况下,GPT-4才能给出针对性的答案。否则,如果问得很浅,那得到的反馈也只会是和百科一样的表面回答。
一个会让人警铃大作的消息是,著名金融服务公司摩根士丹利已经在实际业务中使用了GPT。
摩根士丹利的工作人员所面对的巨大内容库,涵盖了投资策略、市场研究和评论以及分析师见解等长达数十万页的内容。这些信息大多以PDF格式分布在内部网站上,需要浏览大量信息才能找到特定问题的答案,检索起来费时费力。
而GPT高效的信息处理能力,让这部分工作量得到了有效疏解。
但这也意味着,这部分信息处理类的初级岗位将要被淘汰,留下来的人必然要具备更强的洞察力,并且能提出好的问题来引导GPT。
所以,就目前来看,人类还不用为被AI取代而担心,但*不能躺平大意,而是要不断增强自己的水平,让AI取代不了自己。
【本文由投资界合作伙伴微信公众号:新周刊授权发布,本平台仅提供信息存储服务。】如有任何疑问,请联系(editor@zero2ipo.com.cn)投资界处理。





