
过去二十多年,计算性能的提升受益于摩尔定律的扩展,性能增长达到了60000倍,如图1所示。然而,同一时期内,I/O带宽仅增长了30倍。当下,如何将高带宽互连扩展到单个机架之外是NVIDIA以及其他厂商都面临的必然挑战。据行业分析公司LightCounting的分析指出:将 GPU集群从36-72个芯片扩展到500-1000个芯片是加速人工智能训练的*选择;在未来3年内,即使是推理集群也可能需要多达 1,000 个GPU才能支持更大的模型。共封装光学器件(CPO,Co-Packaged Optics)可能是在4-8机架系统中提供数万个高速互连器件的*选择。
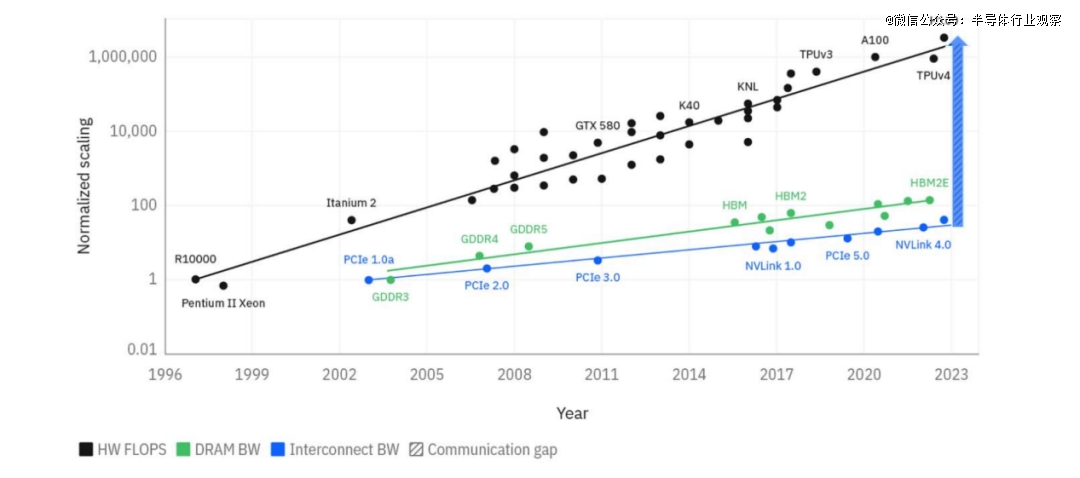
图1:不同代际互连和存储的带宽(BW)以及硬件(HW)峰值FLOPS的扩展。值得注意的是,互连带宽增长的速度远低于硬件FLOPS。(来源:IBM论文,arXiv:2412.06570)
目前,数据中心在数据传输中已广泛依赖光学技术,但对于短至中长距离(< 2米)的互连连接,光学技术的应用仍较少。虽然传统的可插拔光学可作为过渡技术,但其带宽增长速度远低于数据中心流量的增长速度,应用需求和传统可插拔光学技术能力之间的差距不断加大,这一趋势是不可持续的。
共封装光学(CPO)作为一种颠覆性技术,通过先进的封装技术和电子光子协同优化,极大地缩短电气连接路径,从而提高互连带宽密度和能效。因而,CPO也被誉为AI时代的关键互连技术之一。LightCounting创始人兼首席执行官Vlad Kozlov表示:“我们预测,到 2029 年,CPO端口出货量将从目前的不到5万个增长到超过1800万个,其中大多数端口将用于服务器内的连接。”
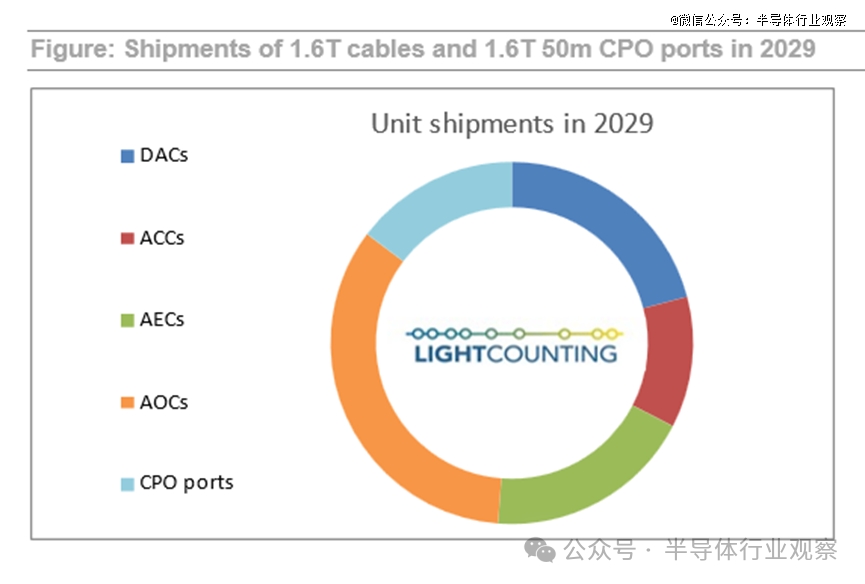
图2:1.6T线缆类和1.6T 50m CPO端口的发货量
(图源:LightCounting)
而从博通、Marvell、IBM等各家厂商在CPO领域的最新进展来看,CPO将迎来云厂商的快速采用和部署的浪潮。
博通CPO,商业化加快
2024年12月30日,据经济日报的报道,台积电硅光战略取得重大进展,近期实现共封装光学元件(CPO)与先进半导体封装技术的整合,预计2025年初开始样品交付,博通和NVIDIA将成为台积电该解决方案的首批客户。
报道中指出,台积电与博通联合开发的微环调制器(MRM)近期已通过3nm试产,为*AI芯片集成到CPO模块奠定基础,预计台积电将采用其CoWoS或SoIC先进封装。此举也说明CPO技术已从研发阶段向量产化迈进,1.6T光传输时代正加速到来。
去年3月份,博通已向小部分客户交付了业界* 51.2 兆兆位/秒 (Tbps) 共封装光学 (CPO) 以太网交换机 Bailly。该产品集成了八个基于硅光子的 6.4-Tbps 光学引擎和 Broadcom 一流的 StrataXGS Tomahawk5 交换机芯片。与可插拔收发器解决方案相比,Bailly 使光学互连的运行功耗降低了70%,硅面积效率提高了8倍。
随着台积电的强势参与,为CPO技术注入了可信赖的供应链能力,并可能助推博通CPO方案在市场中加速推广,为芯片与光学技术的融合提供强有力的支撑。
Marvell:XPU架构正式整合CPO
Marvell在收购Inphi之后,大大增强了在光通信和数据中心领域的研发能力。自2017年以来,Marvell开始为全球*超大规模数据中心提供硅光子设备,并成功将其应用于COLORZ数据中心互连光学模块。这一技术已获得多个行业*的数据中心认证,并实现大规模生产。截至目前,Marvell的硅光设备已累计记录超过100亿小时的现场运行时间。
作为硅光技术发展的下一步,Marvell正重点布局共封装光学(CPO)技术,这是公司在下一代互连技术发展中的关键一步。
2025年1月6日,Marvell宣布,其下一代定制XPU架构将采用共封装光学 (CPO) 技术。CPO技术使得AI服务器的规模从目前使用铜互连的机架内数十个XPU扩展到使用CPO 的多个机架中的数百个XPU,这意味着AI服务器的计算能力可以在更大范围内得到提升,同时保持低延迟和高效的能耗表现。
Marvell指出,下一代定制AI加速器XPU架构使用高速 SerDes、die-to-die芯片接口和先进封装技术,将 XPU计算芯片、HBM和其他芯片与Marvell 3D SiPho引擎整合在同一基板上。这种方法无需电信号离开XPU封装进入铜缆或穿过印刷电路板。CPO利用高带宽硅光子光学引擎来提高数据吞吐量,与传统铜连接相比,硅光子光学引擎可提供更高的数据传输速率,并且不易受到电磁干扰。这种集成还通过减少对高功率电气驱动器、中继器和重定时器的需求来提高电源效率。
早在2024年,Marvell就展示了全球*3D SiPho引擎——一个集成度极高的光学引擎,支持200Gbps的电气和光学接口。而Marvell 6.4T 3D SiPho 引擎是一款高度集成的光学引擎,具有 32 个 200G 电气和光学接口通道、数百个组件(例如调制器、光电探测器、调制器驱动器、跨阻放大器、微控制器)以及大量其他无源组件,这些组件集成在一个统一的设备中,与具有 100G 电气和光学接口的同类设备相比,可提供 2 倍的带宽、2 倍的输入/输出带宽密度和 30% 的每比特功耗降低。多家客户正在评估该技术,以将其集成到其下一代解决方案中。
借助集成光学器件,XPU 之间的连接可以实现更快的数据传输速率和比电缆长100 倍的距离。这可以在 AI 服务器内实现跨多个机架的扩展连接,并具有*延迟和功耗。通过实现更长距离和更高密度的 XPU 到 XPU 连接,CPO 技术促进了高性能、高容量扩展 AI 服务器的开发,从而优化了下一代加速基础设施的计算性能和功耗。
Marvell的此次宣布无疑昭示出CPO已经逐渐被XPU厂商认可。要知道,Marvell前不久才与全球云端服务供应商龙头亚马逊AWS签署五年合作协议,供应亚马逊AWS客制化AI芯片。随着Marvell AI定制化芯片整合CPO步伐的加快,预计CPO的应用和部署将大大提速。
IBM:新工艺突破加速CPO实现
尽管硅光子学并不是一个新概念,但需要开发先进的制造工艺和器件结构,以满足CPO的需求。近年来,CPO解决方案逐渐兴起。尽管如此,CPO的广泛应用仍面临许多挑战,而增加光纤集成密度可能是推动市场采纳的一个步骤。
近日,IBM宣布,其研究人员开创了一种新型的共封装光学(CPO)工艺,全新的共封装光学 (CPO) 原型将通过使用聚合物材料来引导光学而不是传统的基于玻璃的光纤。IBM 的论文概述了这些新的高带宽密度光学结构如何与每个光通道传输多个波长相结合,有可能将芯片之间的带宽提高到电气连接的 80 倍。
在IBM的技术研究论文《Next generation Co-Packaged Optics Technology to Train & Run Generative AI Models in Data Centers and Other Computing Applications,下一代共封装光学技术用于在数据中心和其他计算应用中训练和运行生成式AI模型》中报告了成功设计和制造基于50微米间距聚合物波导接口的光学模块,这些模块经过集成优化,能够实现低损耗、高密度的光数据传输,并在硅光子芯片上占据极小的空间。该原型模块符合JEDEC可靠性标准,承诺将芯片边缘可连接的光纤数量——即所谓的“海滨密度”——提高六倍,超越了当前*进技术的水平。聚合物波导的可扩展性,使其能够缩小至小于20微米的间距,预计将使带宽密度提升至10 Tbps/mm以上。
根据Weight&Biases的报道,在使用GPU训练时,网络经常成为瓶颈,导致三分之一的用户平均利用率不足15%。这无疑增加了成本和能耗。对于参数超过十亿的模型,在8000个H100 GPU上训练大约需要3个月。根据估算,训练一个GPT-4模型可能消耗50千兆瓦时的电力。此外,国际能源署(IEA)计算出,2022年数据中心消耗了460太瓦时的电力,占全球电力需求的近2%,预计这一数字到2026年将翻倍。
而IBM的全新的CPO工艺技术有望显著提高数据中心通信的带宽,减少GPU空闲时间,同时大幅加速AI处理过程。根据这一创新研究,未来CPO技术可带来如下成果:
更低的生成式AI扩展成本:相比中等距离电气互连,CPO可减少超过5倍的能耗,同时将数据中心互连电缆的传输距离从一米延伸至数百米。
更快的AI模型训练:通过CPO,开发者能够将大型语言模型(LLM)的训练速度提高至常规电气线路的五倍,预计训练一个标准LLM的时间可从三个月缩短至三周,性能提升会随着使用更大模型和更多GPU而进一步增强。
显著提高数据中心能效:每训练一个AI模型,CPO技术将节省相当于5,000户美国家庭年用电量的能量。
IBM还在努力开发下一代测试载体,采用子20 µm间距的光波导、增加的波导通道、增加的多波长(λ)兼容硬件演示,并提供多个层次的光纤连接器/连接器组装选项,适用于CPO模块。针对这一未来节能硬件演示的建模和仿真表明,该技术能够支持更高的带宽密度。借助改进的能源效率,提升未来生成性AI应用和其他计算应用的性能已成为可能,令人激动地推动这一进程。IBM计划在2025年初发布更多详细的CPO信息。
【本文由投资界合作伙伴微信公众号:半导体行业观察授权发布,本平台仅提供信息存储服务。】如有任何疑问,请联系(editor@zero2ipo.com.cn)投资界处理。





